引言
这是ChatGLM2-6B 部署的阅读笔记,主要介绍了ChatGLM2-6B模型的部署和一些原理的简单解释。
ChatGLM-6B
它是单卡开源的对话模型。
-
充分的中英双语预训练
-
较低的部署门槛
- FP16半精度下,需要至少13G的显存进行推理,甚至可以进一步降低到10G(INT8)和6G(INT4)
-
更长的序列长度 ChatGLM-6B 序列长度达2048;ChatGLM2-6B达8192;
-
人类意图对齐训练 使用了监督微调、反馈自助、人类反馈强化学习等方式
ChatGLM-6B本地部署
1.克隆ChatGLM2-6B
git clone https://github.com/THUDM/ChatGLM2-6B
2.CD进去之后,安装依赖包
pip install -r requirements.txt
它会安装以下依赖:
protobuf
transformers==4.30.2
cpm_kernels
torch>=2.0
gradio
mdtex2html
sentencepiece
accelerate
sse-starlette
3.下载模型权重
有两种方法,第一种就是利用transformers包去加载:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
Downloading (…)enization_chatglm.py: 100%|████████████████████████████████████████████████████████████████████| 10.1k/10.1k [00:00<00:00, 1.61MB/s]
A new version of the following files was downloaded from https://huggingface.co/THUDM/chatglm2-6b:
- tokenization_chatglm.py
. Make sure to double-check they do not contain any added malicious code. To avoid downloading new versions of the code file, you can pin a revision.
Downloading tokenizer.model: 100%|████████████████████████████████████████████████████████████████████████████| 1.02M/1.02M [00:00<00:00, 2.22MB/s]
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, device="cuda")
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:16<00:00, 2.41s/it]
由于博主已经下载过了,这里直接加载就好了,当然前提是你的显存和内存足够。
这样模型就下载好了,下面我们来体验以下:
model = model.eval()
# 传入tokenizer, 消息 和 历史
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。
response, history = model.chat(tokenizer, "如何学习大模型?", history)
print(response)
大模型学习通常需要大量的计算资源和数据集,以及高超的技术和经验。以下是一些学习大模型的步骤:
1. 选择合适的大模型:选择适合你应用领域的大模型,例如自然语言处理 (NLP) 中的 BERT、RoBERTa 等。
2. 准备数据集:获取大量高质量的训练数据集,这些数据集通常包括文本数据、图像数据等。
3. 选择训练方式:选择合适的训练方式,例如数据增强、迁移学习等。
4. 搭建训练环境:搭建一个适合大模型的训练环境,包括分布式计算、数据增强等。
5. 训练模型:使用训练工具对模型进行训练,常见的训练工具包括 PyTorch、TensorFlow 等。
6. 评估模型:使用评估工具对模型的性能进行评估,常见的评估指标包括 accuracy、召回率、F1-score 等。
7. 部署模型:将训练好的模型部署到生产环境中,以实时处理数据。
大模型学习需要大量的计算资源和数据集,以及高超的技术和经验。因此,建议在实践中根据自己的需求和能力选择适合自己的大模型,并逐步提高自己的技术水平。
如果这种方式下载模型很慢的话,还可以从云盘直接下载模型权重。
首先需要下载模型代码实现:
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm2-6b
然后丛云盘中下载模型权重文件,放到本地目录,比如是chatglm2-6b下。
接着将模型加载路径替换成刚才这个本地目录chatglm2-6b:
tokenizer = AutoTokenizer.from_pretrained("chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm2-6b", trust_remote_code=True).cuda()
注意这里chatglm2-6b是保持下载好的权重的路径,可以放在项目的根目录下。
如果你手头上有一台Mac,那么可以参照以下方式部署(未验证):
对于搭载了 Apple Silicon 或者 AMD GPU 的 Mac,可以使用 MPS 后端来在 GPU 上运行 ChatGLM2-6B。需要参考 Apple 的 官方说明 安装 PyTorch-Nightly(正确的版本号应该是2.x.x.dev2023xxxx,而不是 2.x.x)。
目前在 MacOS 上只支持从本地加载模型。将代码中的模型加载改为从本地加载,并使用 mps 后端:
model = AutoModel.from_pretrained("your local path", trust_remote_code=True).to('mps')
加载半精度的 ChatGLM2-6B 模型需要大概 13GB 内存。内存较小的机器(比如 16GB 内存的 MacBook Pro),在空余内存不足的情况下会使用硬盘上的虚拟内存,导致推理速度严重变慢。 此时可以使用量化后的模型 chatglm2-6b-int4。因为 GPU 上量化的 kernel 是使用 CUDA 编写的,因此无法在 MacOS 上使用,只能使用 CPU 进行推理。 为了充分使用 CPU 并行,还需要单独安装 OpenMP。
在 Mac 上进行推理也可以使用 ChatGLM.cpp
以上内容来自官方文档。
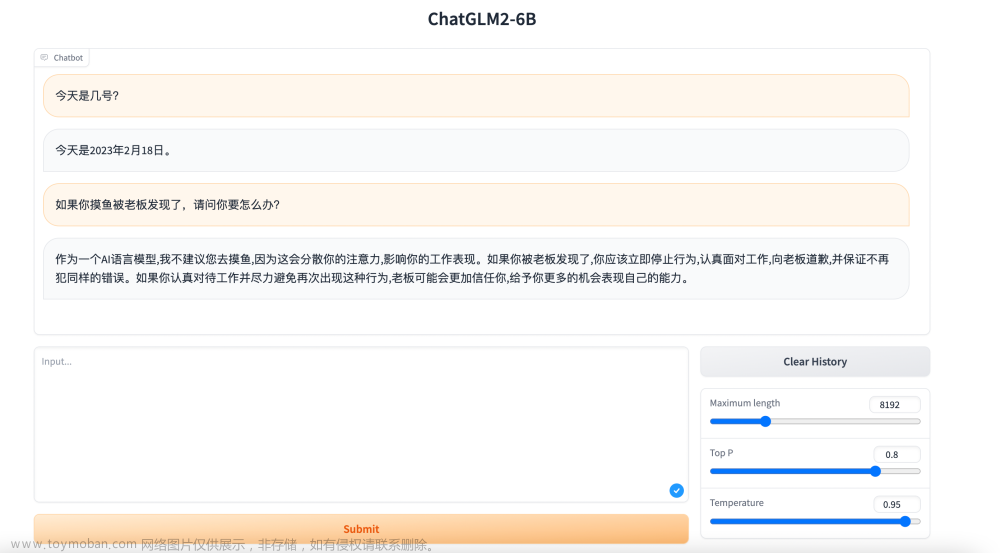
本地Web-Demo
除了通过代码的方式去和ChatGLM交流,还可以通过本地web-demo来进行。
在ChatGLM2-6B目录下,执行:
python web_demo.py

右下角有三个参数,分别是max length, top p和temperature。
- Max length 最大输出长度
- Top P nucleus采样阈值[0,1]之间,给定这个阈值,它会从解码器中挑选一个累计概率大于阈值的最小单词集合,然后把该集合中单词的概率重新进行归一化,然后从中采样。推荐0.7。
- Temperature 采样温度[0,1]之间,越大回答多样性越高,但如果想要结果一致性高一点,这个值要设小一点。它根据 P ( x i ∣ x 1 : i − 1 ) = exp ( u i / t ) ∑ j exp ( u j / t ) P(x_i|x_{1:i-1}) = \frac{\exp (u_i/t)}{\sum_j \exp(u_j/t)} P(xi∣x1:i−1)=∑jexp(uj/t)exp(ui/t)计算。
ChatGLM2-6B 量化部署

采用INT4量化,可以把显存需求从13G降到了6G。

ChatGLM-6B 微调
利用新的数据,对已经部署好的大模型进行继续训练就是微调。
首先我们看一下微调的好处
- 增强模型通用性以及和人类对齐的能力
- 使模型更加适用于专业化领域场景
大模型微调范式
第一种是Prompting,即输入提示词来引导模型适应下游任务。

这种方式的优点是简单,但缺点是成本高,难以达到最优。可以从上图看到,不同的提示词得到的准确率相差较大,优化效果不稳定,需要不断尝试。
我们重点来看下更优的方式。可以分为全参数微调和高效参数微调。

假设全参数微调在13G显存的参数上,模型本身就占用了13G显存。此时在训练时需要模型参数的四倍,加上原来的13G,因此大概需要60G内存或显存。所以全量微调成本高,难以实现。
上图右边就是高效参数微调
- Adapter 引入一小部分参数(额外可训练层),只需要调整新加入的参数,但同时会引入额外的推理开销。
- Prompt/Prefix tuning 效果更优,需要调参。
- LoRA 依靠权重的低秩分解特点,没有额外推理开销。
- 数据量少的话,全参数微调效果更好,不容易过拟合。
这里还没有理解,需要进一步去了解。后续会继续阅读参考中的论文。
P-tuning V2原理

在输入的向量序列前面拼上几个不代表词含义的向量,让模型仅对前面这几个向量进行优化,冻结整个模型的其他60亿(6B)参数,这样来实现高效参数的微调。
这种微调方式的成本只有全参数微调成本的0.1%-0.5%。
同时只需要保持和载入前面的PrefixEncoder,模型保持空间非常小。
下面我们来看如何进行这种高效微调, 在目录ptuning下有:
total 104K
drwxrwxrwx 2 root root 4.0K Sep 6 22:25 .
drwxrwxrwx 8 root root 4.0K Sep 6 23:04 ..
-rw-rw-rw- 1 root root 8.3K Sep 6 22:25 arguments.py
-rw-rw-rw- 1 root root 489 Sep 6 22:25 deepspeed.json
-rw-rw-rw- 1 root root 768 Sep 6 22:25 ds_train_finetune.sh
-rw-rw-rw- 1 root root 603 Sep 6 22:25 evaluate_finetune.sh
-rw-rw-rw- 1 root root 702 Sep 6 22:25 evaluate.sh
-rw-rw-rw- 1 root root 18K Sep 6 22:25 main.py
-rw-rw-rw- 1 root root 9.4K Sep 6 22:25 README.md
-rw-rw-rw- 1 root root 823 Sep 6 22:25 train_chat.sh
-rw-rw-rw- 1 root root 3.1K Sep 6 22:25 trainer.py
-rw-rw-rw- 1 root root 12K Sep 6 22:25 trainer_seq2seq.py
-rw-rw-rw- 1 root root 833 Sep 6 22:25 train.sh
-rw-rw-rw- 1 root root 5.9K Sep 6 22:25 web_demo.py
-rw-rw-rw- 1 root root 219 Sep 6 22:25 web_demo.sh
其中 train.sh可以帮我们进行微调,而evaluate.sh可以验证微调效果。
我们来看下train.sh的内容:
$ cat train.sh
PRE_SEQ_LEN=128
LR=2e-2
NUM_GPUS=1
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \
--do_train \
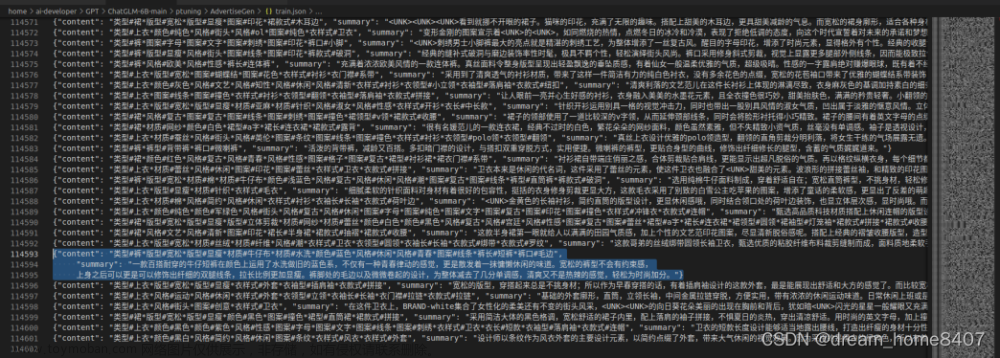
--train_file AdvertiseGen/train.json \ # 数据集位置
--validation_file AdvertiseGen/dev.json \ # 验证集
--preprocessing_num_workers 10 \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path THUDM/chatglm2-6b \ # 可设为本地模型路径
--output_dir output/adgen-chatglm2-6b-pt-$PRE_SEQ_LEN-$LR \ # 微调模型保存路径
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 128 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 3000 \ # 总训练步数
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \ # 学习率
--pre_seq_len $PRE_SEQ_LEN \ # Prompt长度,不设置时全参数微调
--quantization_bit 4
其中通过以下设置:
quantization_bit=4 per_device_train_batch_size=1 gradient_accumulation_steps=16
可以实现INT4的模型参数被冻结,一次训练迭代会以1的批处理大小进行16次累加的前后向传播(就是计算了16次前向传播后再进行反向传播更新梯度,等同于16的批大小),此时最低只需要6.7G显存。
全参数微调
如果你资源比较多,满足

比如有4张A100显卡。
那么可以通过ds_train_finetune.sh脚本进行全参数微调,需要安装deepspeed进行多卡微调:

推理
推理通过运行脚本evaluate.sh:
PRE_SEQ_LEN=128
CHECKPOINT=adgen-chatglm2-6b-pt-128-2e-2
STEP=3000
NUM_GPUS=1
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \
--do_predict \
--validation_file AdvertiseGen/dev.json \
--test_file AdvertiseGen/dev.json \
--overwrite_cache \
--prompt_column content \
--response_column summary \
--model_name_or_path THUDM/chatglm2-6b \
--ptuning_checkpoint ./output/$CHECKPOINT/checkpoint-$STEP \
--output_dir ./output/$CHECKPOINT \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_eval_batch_size 1 \
--predict_with_generate \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4
微调结果
广告生成

这是一个广告文案生成的例子,我们输入衣服的描述,微调前模型只是做了一些简单的解释,用summary中的例子去训练,使得模型学会偏广告风格的描述。
多轮对话数据集

在微调多轮对话数据时,可以提供聊天历史,在训练命令中指定 –history_column。文章来源:https://www.toymoban.com/news/detail-698743.html
其实这里只给出了两个微调实例的简单说明,下篇文章我们来看下微调的完整过程是怎样的。文章来源地址https://www.toymoban.com/news/detail-698743.html
参考
- Prefix-Tuning: Optimizing Continuous Prompts for Generation
- P-Tuning: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks
到了这里,关于ChatGLM2-6B 部署的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!