架构原理
一、高吞吐机制:Batch打包、缓冲区、acks
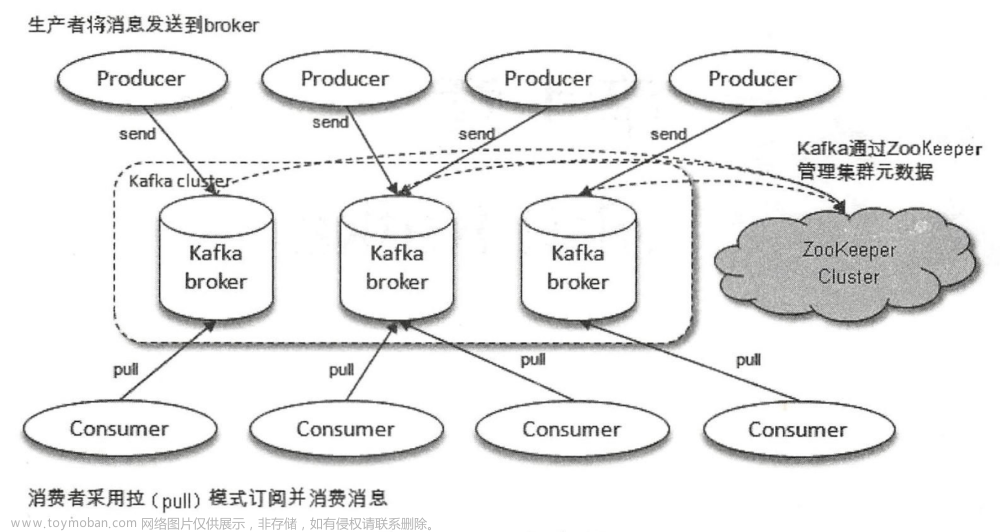
1. Kafka Producer怎么把消息发送给Broker集群的?
需要指定把消息发送到哪个topic去
首先需要选择一个topic的分区,默认是轮询来负载均衡,但是如果指定了一个分区key,那么根据这个key的hash值来分发到指定的分区,这样可以让相同的key分发到同一个分区里去,还可以自定义partitioner来实现分区策略
producer.send(msg); // 用类似这样的方式去发送消息,就会把消息给你均匀的分布到各个分区上去
producer.send(key, msg); // 订单id,或者是用户id,他会根据这个key的hash值去分发到某个分区上去,他可以保证相同的key会路由分发到同一个分区上去
知道要发送到哪个分区之后,还得找到这个分区的leader副本所在的机器,然后跟那个机器上的Broker通过Socket建立连接来进行通信,发送Kafka自定义协议格式的请求过去,把消息就带过去了
如果找到了partition的leader所在的broker之后,就可以通过socket跟那台broker建立连接,接着发送消息过去
Producer(生产者客户端),起码要知道两个元数据,每个topic有几个分区,每个分区的leader是在哪台broker上,会自己从broker上拉取kafka集群的元数据,缓存在自己client本地客户端上
kafka使用者的层面来考虑一下,我如果要把数据写入kafka集群,应该如何来做,怎么把数据写入kafka集群,以及他背后的一些原理还有使用过程中需要设置的一些参数,到底应该怎么来弄

2. 用一张图告诉你Producer发送消息的内部实现原理
每次发送消息都必须先把数据封装成一个ProducerRecord对象,里面包含了要发送的topic,具体在哪个分区,分区key,消息内容,timestamp时间戳,然后这个对象交给序列化器,变成自定义协议格式的数据
接着把数据交给partitioner分区器,对这个数据选择合适的分区,默认就轮询所有分区,或者根据key来hash路由到某个分区,这个topic的分区信息,都是在客户端会有缓存的,当然会提前跟broker去获取
接着这个数据会被发送到producer内部的一块缓冲区里
然后producer内部有一个Sender线程,会从缓冲区里提取消息封装成一个一个的batch,然后每个batch发送给分区的leader副本所在的broker
3. 基于Java API写一个Kafka Producer发送消息的代码示例
package com.zhss.demo.kafka;
import java.util.Properties;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
public class ProducerDemo {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
// 这里可以配置几台broker即可,他会自动从broker去拉取元数据进行缓存
props.put("bootstrap.servers", "hadoop03:9092,hadoop04:9092,hadoop05:9092");
// 这个就是负责把发送的key从字符串序列化为字节数组
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 这个就是负责把你发送的实际的message从字符串序列化为字节数组
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("acks", "-1");
props.put("retries", 3);
props.put("batch.size", 323840);
props.put("linger.ms", 10);
props.put("buffer.memory", 33554432);
props.put("max.block.ms", 3000);
// 创建一个Producer实例:线程资源,跟各个broker建立socket连接资源
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
ProducerRecord<String, String> record = new ProducerRecord<>(
"test-topic", "test-key", "test-value");
// 这是异步发送的模式
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception == null) {
// 消息发送成功
System.out.println("消息发送成功");
} else {
// 消息发送失败,需要重新发送
}
}
});
Thread.sleep(10 * 1000);
// 这是同步发送的模式
// producer.send(record).get();
// 你要一直等待人家后续一系列的步骤都做完,发送消息之后
// 有了消息的回应返回给你,你这个方法才会退出来
producer.close();
}
}
4. 发送消息给Broker时遇到的各种异常该如何处理?
之前我们看到不管是异步还是同步,都可能让你处理异常,常见的异常如下:
LeaderNotAvailableException:这个就是如果某台机器挂了,此时leader副本不可用,会导致你写入失败,要等待其他follower副本切换为leader副本之后,才能继续写入,此时可以重试发送即可
如果说你平时重启kafka的broker进程,肯定会导致leader切换,一定会导致你写入报错,是LeaderNotAvailableException
NotControllerException:这个也是同理,如果说Controller所在Broker挂了,那么此时会有问题,需要等待Controller重新选举,此时也是一样就是重试即可
NetworkException:网络异常,重试即可
我们之前配置了一个参数,retries,他会自动重试的,但是如果重试几次之后还是不行,就会提供Exception给我们来处理了
5. 发送消息的缓冲区应该如何优化来提升发送的吞吐量?
buffer.memory:设置发送消息的缓冲区,默认值是33554432,就是32MB
如果发送消息出去的速度小于写入消息进去的速度,就会导致缓冲区写满,此时生产消息就会阻塞住,所以说这里就应该多做一些压测,尽可能保证说这块缓冲区不会被写满导致生产行为被阻塞住
compression.type,默认是none,不压缩,但是也可以使用lz4压缩,效率还是不错的,压缩之后可以减小数据量,提升吞吐量,但是会加大producer端的cpu开销
6. 消息批量发送的核心参数batch.size是如何优化吞吐量?
batch.size,设置meigebatch的大小,如果batch太小,会导致频繁网络请求,吞吐量下降;如果batch太大,会导致一条消息需要等待很久才能被发送出去,而且会让内存缓冲区有很大压力,过多数据缓冲在内存里
默认值是:16384,就是16kb,也就是一个batch满了16kb就发送出去,一般在实际生产环境,这个batch的值可以增大一些来提升吞吐量,可以自己压测一下
还有一个参数,linger.ms,这个值默认是0,意思就是消息必须立即被发送,但是这是不对的,一般设置一个100毫秒之类的,这样的话就是说,这个消息被发送出去后进入一个batch,如果100毫秒内,这个batch满了16kb,自然就会发送出去
但是如果100毫秒内,batch没满,那么也必须把消息发送出去了,不能让消息的发送延迟时间太长,也避免给内存造成过大的一个压力
7. 如何根据业务场景对消息大小以及请求超时进行合理的设置?
max.request.size:这个参数用来控制发送出去的消息的大小,默认是1048576字节,也就1mb,这个一般太小了,很多消息可能都会超过1mb的大小,所以需要自己优化调整,把他设置更大一些
你发送出去的一条大数据,超大的JSON串,超过1MB,就不让你发了
request.timeout.ms:这个就是说发送一个请求出去之后,他有一个超时的时间限制,默认是30秒,如果30秒都收不到响应,那么就会认为异常,会抛出一个TimeoutException来让我们进行处理
8. 基于Kafka内核架构原理深入分析acks参数到底是干嘛的
acks参数,其实是控制发送出去的消息的持久化机制的
如果acks=0,那么producer根本不管写入broker的消息到底成功没有,发送一条消息出去,立马就可以发送下一条消息,这是吞吐量最高的方式,但是可能消息都丢失了,你也不知道的,但是说实话,你如果真是那种实时数据流分析的业务和场景,就是仅仅分析一些数据报表,丢几条数据影响不大的
会让你的发送吞吐量会提升很多,你发送弄一个batch出,不需要等待人家leader写成功,直接就可以发送下一个batch了,吞吐量很大的,哪怕是偶尔丢一点点数据,实时报表,折线图,饼图
acks=all,或者acks=-1:这个leader写入成功以后,必须等待其他ISR中的副本都写入成功,才可以返回响应说这条消息写入成功了,此时你会收到一个回调通知
min.insync.replicas = 2,ISR里必须有2个副本,一个leader和一个follower,最最起码的一个,不能只有一个leader存活,连一个follower都没有了
acks = -1,每次写成功一定是leader和follower都成功才可以算做成功,leader挂了,follower上是一定有这条数据,不会丢失
retries = Integer.MAX_VALUE,无限重试,如果上述两个条件不满足,写入一直失败,就会无限次重试,保证说数据必须成功的发送给两个副本,如果做不到,就不停的重试,除非是面向金融级的场景,面向企业大客户,或者是广告计费,跟钱的计算相关的场景下,才会通过严格配置保证数据绝对不丢失
acks=1:只要leader写入成功,就认为消息成功了,默认给这个其实就比较合适的,还是可能会导致数据丢失的,如果刚写入leader,leader就挂了,此时数据必然丢了,其他的follower没收到数据副本,变成leader
9. 针对瞬间异常的消息重试参数有哪些需要考虑的点
有的时候一些leader切换之类的问题,需要进行重试,设置retries即可,而且还可以跟消息不丢失结合起来,但是消息重试会导致重复发送的问题,比如说网络抖动一下导致他以为没成功,就重试了,其实人家都成功了
所以消息重试导致的消费重复,需要你在下游consumer做幂等性处理,但是kafka已经支持了一次且仅一次的消息语义
另外一个,消息重试是可能导致消息的乱序的,因为可能排在你后面的消息都发送出去了,你现在收到回调失败了才在重试,此时消息就会乱序,所以可以使用“max.in.flight.requests.per.connection”参数设置为1,这样可以保证producer同一时间只能发送一条消息
两次重试的间隔默认是100毫秒,用“retry.backoff.ms”来进行设置
一般来说,某台broker重启导致的leader切换,是最常见的异常,所以尽可能把重试次数和间隔,设置的可以cover住新leader切换过来
10. Kafka Producer高阶用法(一):自定义分区
public class HotDataPartitioner implements Partitioner {
private Random random;
@Override
public void configure(Map<String, ?> configs) {
random = new Random();
}
@Override
public int partition(String topic, Object keyObj, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
String key = (String)keyObj;
List<PartitionInfo> partitionInfoList = cluster.availablePartitionsForTopic(topic);
int partitionCount = partitionInfoList.size();
int hotDataPartition = partitionCount - 1;
return !key.contains(“hot_data”) ? random.nextInt(partitionCount - 1) : hotDataPartition;
}
}
props.put(“partitioner.class”, “com.zhss.HotDataPartitioner”);
测试发送
bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic test-topic
11. Kafka Producer高阶用法(二):自定义序列化
12. Kafka Producer高阶用法(三):自定义拦截器
二、Kafka Consumer选举与Rebalance实现原理
1. 一张图画清Kafka基于Consumer Group的消费者组的模型
每个consumer都要属于一个consumer.group,就是一个消费组,topic的一个分区只会分配给一个消费组下的一个consumer来处理,每个consumer可能会分配多个分区,也有可能某个consumer没有分配到任何分区
分区内的数据是保证顺序性的
group.id = “membership-consumer-group”
如果你希望实现一个广播的效果,你的每台机器都要消费到所有的数据,每台机器启动的时候,group.id可以是一个随机生成的UUID也可以,你只要让不同的机器的KafkaConsumer的group.id是不一样的
如果consumer group中某个消费者挂了,此时会自动把分配给他的分区交给其他的消费者,如果他又重启了,那么又会把一些分区重新交还给他,这个就是所谓的消费者rebalance的过程
2. 消费者offset的记录方式以及基于内部topic的提交模式
每个consumer内存里数据结构保存对每个topic的每个分区的消费offset,定期会提交offset,老版本是写入zk,但是那样高并发请求zk是不合理的架构设计,zk是做分布式系统的协调的,轻量级的元数据存储,不能负责高并发读写,作为数据存储
所以后来就是提交offset发送给内部topic:__consumer_offsets,提交过去的时候,key是group.id+topic+分区号,value就是当前offset的值,每隔一段时间,kafka内部会对这个topic进行compact
也就是每个group.id+topic+分区号就保留最新的那条数据即可
而且因为这个__consumer_offsets可能会接收高并发的请求,所以默认分区50个,这样如果你的kafka部署了一个大的集群,比如有50台机器,就可以用50台机器来抗offset提交的请求压力,就好很多
3. 基于Java API写一个Kafka Consumer消费消息的代码示例
String topicName = “test-topic”;
String groupId = “test-group”;
Properties props = new Properties();
props.put(“bootstrap.servers”, “localhost:9092”);
props.put(“group.id”, “groupId”);
props.put(“enable.auto.commit”, “true”);
props.put(“auto.commit.ineterval.ms”, “1000”);
// 每次重启都是从最早的offset开始读取,不是接着上一次
props.put(“auto.offset.reset”, “earliest”);
props.put(“key.deserializer”, “org.apache.kafka.common.serialization.StringDeserializer”);
props.put(“value.deserializer”, “org.apache.kafka.common.serialization.SttringDeserializer”);
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(topicName));
try {
while(true) {
ConsumerRecords<String, String> records = consumer.poll(1000); // 超时时间
for(ConsumerRecord<String, String> record : records) {
System.out.println(record.offset() + “, ” + record.key() + “, ” + record.value());
}
}
} catch(Exception e) {
}
4. Kafka感知消费者故障是通过哪三个参数来实现的?
heartbeat.interval.ms:consumer心跳时间,必须得保持心跳才能知道consumer是否故障了,然后如果故障之后,就会通过心跳下发rebalance的指令给其他的consumer通知他们进行rebalance的操作
session.timeout.ms:kafka多长时间感知不到一个consumer就认为他故障了,默认是10秒
max.poll.interval.ms:如果在两次poll操作之间,超过了这个时间,那么就会认为这个consume处理能力太弱了,会被踢出消费组,分区分配给别人去消费,一遍来说结合你自己的业务处理的性能来设置就可以了
5. 对消息进行消费时有哪几个参数需要注意以及设置呢?
fetch.max.bytes:获取一条消息最大的字节数,一般建议设置大一些
max.poll.records:一次poll返回消息的最大条数,默认是500条
connection.max.idle.ms:consumer跟broker的socket连接如果空闲超过了一定的时间,此时就会自动回收连接,但是下次消费就要重新建立socket连接,这个建议设置为-1,不要去回收
6. 消费者offset相关的参数设置会对运行产生什么样的影响?
auto.offset.reset:这个参数的意思是,如果下次重启,发现要消费的offset不在分区的范围内,就会重头开始消费;但是如果正常情况下会接着上次的offset继续消费的
enable.auto.commit:这个就是开启自动提交位移
7. Group Coordinator是什么以及主要负责什么?
每个consumer group都会选择一个broker作为自己的coordinator,他是负责监控这个消费组里的各个消费者的心跳,以及判断是否宕机,然后开启rebalance的,那么这个如何选择呢?
就是根据group.id来进行选择,他有内部的一个选择机制,会给你挑选一个对应的Broker,总会把你的各个消费组均匀分配给各个Broker作为coordinator来进行管理的
他负责的事情只要就是rebalance,说白了你的consumer group中的每个consumer刚刚启动就会跟选举出来的这个consumer group对应的coordinator所在的broker进行通信,然后由coordinator分配分区给你的这个consumer来进行消费
coordinator会尽可能均匀的分配分区给各个consumer来消费
8. 为消费者选择Coordinator的算法是如何实现的?
首先对groupId进行hash,接着对__consumer_offsets的分区数量取模,默认是50,可以通过offsets.topic.num.partitions来设置,找到你的这个consumer group的offset要提交到__consumer_offsets的哪个分区
比如说:groupId,“membership-consumer-group” -> hash值(数字)-> 对50取模 -> 就知道这个consumer group下的所有的消费者提交offset的时候是往哪个分区去提交offset,大家可以找到__consumer_offsets的一个分区
__consumer_offset的分区的副本数量默认来说1,只有一个leader
然后对这个分区找到对应的leader所在的broker,这个broker就是这个consumer group的coordinator了,接着就会维护一个Socket连接跟这个Broker进行通信
9. Coordinator和Consume Leader如何协作制定分区方案?
每个consumer都发送JoinGroup请求到Coordinator,然后Coordinator从一个consumer group中选择一个consumer作为leader,把consumer group情况发送给这个leader,接着这个leader会负责制定分区方案,通过SyncGroup发给Coordinator
接着Coordinator就把分区方案下发给各个consumer,他们会从指定的分区的leader broker开始进行socket连接以及消费消息
10. rebalance的三种策略分别有哪些优劣势?
这里有三种rebalance的策略:range、round-robin、sticky
0~8
order-topic-0
order-topic-1
order-topic-2
range策略就是按照partiton的序号范围,比如partitioin02给一个consumer,partition35给一个consumer,partition6~8给一个consumer,默认就是这个策略;
round-robin策略,就是轮询分配,比如partiton0、3、6给一个consumer,partition1、4、7给一个consumer,partition2、5、8给一个consumer
但是上述的问题就在于说,可能在rebalance的时候会导致分区被频繁的重新分配,比如说挂了一个consumer,然后就会导致partition04分配给第一个consumer,partition58分配给第二个consumer
这样的话,原本是第二个consumer消费的partition3~4就给了第一个consumer,实际上来说未必就很好
最新的一个sticky策略,就是说尽可能保证在rebalance的时候,让原本属于这个consumer的分区还是属于他们,然后把多余的分区再均匀分配过去,这样尽可能维持原来的分区分配的策略
consumer1:0~2 + 6~7
consumer2:3~5 + 8
11. Consumer内部单线程处理一切事务的核心设计思想
其实就是在一个while循环里不停的去调用poll()方法,其实是我们自己的一个线程,就是我们自己的这个线程就是唯一的KafkaConsumer的工作线程,新版本的kafka api,简化,减少了线程数量
Consumer自己内部就一个后台线程,定时发送心跳给broker;但是其实负责进行拉取消息、缓存消息、在内存里更新offset、每隔一段时间提交offset、执行rebalance这些任务的就一个线程,其实就是我们调用Consumer.poll()方法的那个线程
就一个线程调用进去,会负责把所有的事情都干了
为什么叫做poll呢?因为就是你可以监听N多个Topic的消息,此时会跟集群里很多Kafka Broker维护一个Socket连接,然后每一次线程调用poll(),就会监听多个socket是否有消息传递过来
可能一个consumer会消费很多个partition,每个partition其实都是leader可能在不同的broker上,那么如果consumer要拉取多个partition的数据,就需要跟多个broker进行通信,维护socket
每个socket就会跟一个broker进行通信
每个Consumer内部会维护多个Socket,负责跟多个Broker进行通信,我们就一个工作线程每次调用poll()的时候,他其实会监听多个socket跟broker的通信,是否有新的数据可以去拉取
12. 消费过程中的各种offset之间的关系是什么?
上一次提交offset,当前offset(还未提交),高水位offset,LEO
内存里记录这么几个东西:上一次提交offset,当前消费到的offset,你不断的在消费消息,不停的在拉取新的消息,不停的更新当前消费的offset,HW offset,你拉取的时候,是只能看到HW他前面的数据
LEO,leader partition已经更新到了一个offset了,但是HW在前面,你只能拉取到HW的数据,HW后面的数据,意味着不是所有的follower都写入进去了,所以不能去读取的
13. 自动提交offset的语义以及导致消息丢失和重复消费的问题
默认是自动提交
auto.commit.inetrval.ms:5000,默认是5秒提交一次
如果你提交了消费到的offset之后,人家kafka broker就可以感知到了,比如你消费到了offset = 56987,下次你的consumer再次重启的时候,就会自动从kafka broker感知到说自己上一次消费到的offset = 56987
这次重启之后,就继续从offset = 56987这个位置继续往后去消费就可以了
他的语义是一旦消息给你poll到了之后,这些消息就认为处理完了,后续就可以提交了,所以这里有两种问题:
第一,消息丢失,如果你刚poll到消息,然后还没来得及处理,结果人家已经提交你的offset了,此时你如果consumer宕机,再次重启,数据丢失,因为上一次消费的那批数据其实你没处理,结果人家认为你处理了
poll到了一批数据,offset = 65510~65532,人家刚好就是到了时间提交了offset,offset = 65532这个地方已经提交给了kafka broker,接着你准备对这批数据进行消费,但是不巧的是,你刚要消费就直接宕机了
其实你消费到的数据是没处理的,但是消费offset已经提交给kafka了,下次你重启的时候,offset = 65533这个位置开始消费的,之前的一批数据就丢失了
第二,重复消费,如果你poll到消息,都处理完毕了,此时还没来得及提交offset,你的consumer就宕机了,再次重启会重新消费到这一批消息,再次处理一遍,那么就是有消息重复消费的问题
poll到了一批数据,offset = 65510~65532,你很快的处理完了,都写入数据库了,结果还没来得及提交offset就宕机了,上一次提交的offset = 65509,重启,他会再次让你消费offset = 65510~65532,一样的数据再次重复消费了一遍,写入数据库
重启kafka consumer,修改了他的代码
14. 如何实现Consumer Group的状态机流转机制?
刚开始Consumer Group状态是:Empty
接着如果部分consumer发送了JoinGroup请求,会进入:PreparingRebalance的状态,等待一段时间其他成员加入,这个时间现在默认就是max.poll.interval.ms来指定的,所以这个时间间隔一般可以稍微大一点
接着如果所有成员都加入组了,就会进入AwaitingSync状态,这个时候就不能允许任何一个consumer提交offset了,因为马上要rebalance了,进行重新分配了,这个时候就会选择一个leader consumer,由他来制定分区方案
然后leader consumer制定好了分区方案,SyncGroup请求发送给coordinator,他再下发方案给所有的consumer成员,此时进入stable状态,都可以正常基于poll来消费了
所以如果说在stable状态下,有consumer进入组或者离开崩溃了,那么都会重新进入PreparingRebalance状态,重新看看当前组里有谁,如果剩下的组员都在,那么就进入AwaitingSync状态
leader consumer重新制定方案,然后再下发
15. 最新设计的rebalance分代机制可以有什么作用?
大家设想一个场景,在rebalance的时候,可能你本来消费了partition3的数据,结果有些数据消费了还没提交offset,结果此时rebalance,把partition3分配给了另外一个cnosumer了,此时你如果提交partition3的数据的offset,能行吗?
必然不行,所以每次rebalance会触发一次consumer group generation,分代,每次分代会加1,然后你提交上一个分代的offset是不行的,那个partiton可能已经不属于你了,大家全部按照新的partiton分配方案重新消费数据
consumer group generation = 1
consumer group generation = 2
16. Consumer端的自定义反序列化器是什么?
17. 自行指定每个Consumer要消费哪些分区有用吗?
List partitions = consumer.partitionsFor(“order-topic”);
new TopicPartition(partitionInfo.topic(), partitionInfo.partition());
consumer.assign(partitions); //指定每个consumer要消费哪些分区,你就不是依靠consumer的自动的分区分配方案来做了
18. 老版本的high-level consumer的实现原理是什么?
producer和consumer api原理,都是新版本的kafka api
老版本的kafka consumer api分成两种,high-level和low-level,都是基于zk实现的,只不过前者有consumer group的概念,后者没有
high-level的api,比如说consumer启动就是在zk里写一个临时节点,但是如果自己宕机了,那么zk临时节点就没了,别人就会发现,然后就会开启rebalance
然后在消费的时候,可以指定多个线程取消费一个topic,比如说你和这个consumer分配到了5个分区,那么你可以指定最多5个线程,每个线程消费一个分区的数据,但是新版本的就一个线程负责消费所有分区
在提交offset,就是向zk写入对某个分区现在消费到了哪个offset了,默认60秒才提交一次
新版本的api就不基于zk来实现了呢,zk主要是做轻量级的分布式协调,元数据存储,并不适合高并发大量连接的场景,cnosumer可能有成百上千个,成千上万个,zk来做的,连接的压力,高并发的读写
broker内部基于zk来进行协调
19. 老版本的low-level consumer的实现原理是什么?
老版本的low-level消费者,是可以自己控制offset的,实现很底层的一些控制,但是需要自己去提交offset,还要自己找到某个分区对应的leader broker,跟他进行连接获取消息,如果leader变化了,也得自己处理,非常的麻烦
比如说storm-kafka这个插件,在storm消费kafka数据的时候,就是使用的low-level api,自己获取offset,提交写入zk中自己指定的znode中,但是在未来基本上老版本的会越来越少使用
三、Kafka的时间轮延时调度机制与架构原理总结
1. Producer的缓冲区内部数据结构是什么样子的?
producer会创建一个accumulator缓冲区,他里面是一个HashMap数据结构,每个分区都会对应一个batch队列,因为你打包成出来的batch,那必须是这个batch都是发往同一个分区的,这样才能发送一个batch到这个分区的leader broker
{
“order-topic-0” -> [batch1, batch2],
“order-topic-1” -> [batch3]
}
batch.size
每个batch包含三个东西,一个是compressor,这是负责追加写入batch的组件;第二个是batch缓冲区,就是写入数据的地方;第三个是thunks,就是每个消息都有一个回调Callback匿名内部类的对象,对应batch里每个消息的回调函数
每次写入一条数据都对应一个Callback回调函数的
2. 消息缓冲区满的时候是阻塞住还是抛出异常?
max.block.ms,其实就是说如果写缓冲区满了,此时是阻塞住一段时间,然后什么时候抛异常,默认是60000,也就是60秒
3. 负责IO请求的Sender线程是如何基于缓冲区发送数据的?
Sender线程会不停的轮询缓冲区内的HashMap,看batch是否满了,或者是看linger.ms时间是不是到了,然后就得发送数据去,发送的时候会根据各个batch的目标leader broker来进行分组
因为可能不同的batch是对应不同的分区,但是不同的分区的Leader是在一个broker上的,<Node, List>,接着会进一步封装为<Node, Request>,每个broker一次就是一个请求,但是这里可能包含很多个batch,接着就是将分组好的batch发送给leader broker,并且处理response,来反过来调用每个batch的callback函数
发送出去的Request会被放入InFlighRequests里面去保存,Map<NodeId, Deque>,这里就代表了发送出去的请求,但是还没接收到响应的
4. 同时可以接受有几个发送到Broker的请求没收到响应?
Map<NodeId, Deque> => 给这个broker发送了哪些请求过去了?
max.in.flight.requests.per.connection:5
这个参数默认值是5,默认情况下,每个Broker最多只能有5个请求是发送出去但是还没接收到响应的,所以这种情况下是有可能导致顺序错乱的,大家一定要搞清楚这一点,先发送的请求可能后续要重发
5. Kafka自定义的基于TCP的二进制协议深入探秘一番(一)
kafka自定义了一组二进制的协议,现在一共是包含了43种协议类型,每种协议都有对应的请求和响应,Request和Response,其实说白了,如果大家现在看咱们的那个自研分布式存储系统的课,里面用到了gRPC
你大概可以认为就是定义了43种接口,每个接口就是一种协议,然后每个接口都有自己对应的Request和Response,就这个意思
每个协议的Request都有相同的请求头(RequestHeader),也有不同的请求体(RequestBody),请求头包含了:api_key、api_version、correlation_id、client_id,这里的api_key就类似于“PRODUCE”、“FETCH”,你可以认为是接口的名字吧
“PRODUCE”就是发送消息的接口,“FETCH”就是拉取消息的接口,就这个意思
api_version,就是这个API的版本号
correlation_id,就是类似客户端生成的一次请求的唯一标志位,唯一标识一次请求
client_id,就是客户端的id
每个协议的Response也有相同的响应头,就是一个correlation_id,就是对某个请求的响应
6. Kafka自定义的基于TCP的二进制协议深入探秘一番(二)
比如说发送消息,就是ProduceRequest和ProduceResponse,代表“PRODUCE”这个接口的请求和响应,api_key=0,其实就是“PRODUCE”接口的代表
他的RequestBody,包含了:transactional_id,acks,timeout,topic_data(topic,data(partition,record_set)),acks就是客户端自己指定的acks参数,这个会指示leader和follower副本的写入方式,timeout就是超时时间,默认就是30秒,request.timeout.ms
然后就是要写入哪个topic,哪个分区,以及对应数据集合,里面是多个batch
ProduceResponse,ResponseBody,包含了responses(topic,partition_responses(partition,error_code,base_offset,log_append_time,log_start_offset)),throttle_time_ms,简单来说就是当前响应是对哪个topic写入的响应
包含了每个topic的各个分区的响应,每个partition的写入响应,包括error_code错误码,base_offset是消息集合的起始offset,log_append_time是写入broker端的时间,log_start_offset是分区的起始offset
其实各种接口大体上来说就是如此,所以现在大家就知道了,协议就是一种规定,你发送过来的请求是什么格式的,他可能有请求头还有请求体,分别包含哪些字段,按什么格式放数据,响应也是一样的
然后大家就可以按一样的协议来发送请求和接收响应
7. 盘点一下在Broker内部有哪些不同场景下会有延时任务?
比如说acks=-1,那么必须等待leader和follower都写完才能返回响应,而且有一个超时时间,默认是30秒,也就是request.timeout.ms,那么在写入一条数据到leader磁盘之后,就必须有一个延时任务,到期时间是30秒
延时任务会被放到DelayedOperationPurgatory,延时操作管理器中
这个延时任务如果因为所有follower都写入副本到本地磁盘了,那么就会被自动触发苏醒,那么就可以返回响应结果给客户端了,否则的话,这个延时任务自己指定了最多是30秒到期,如果到了超时时间都没等到,那么就直接超时返回异常了
还有一种是延时拉取任务,也就是说follower往leader拉取消息的时候,如果发现是空的,那么此时会创建一个延时拉取任务,然后延时时间到了之后,就会再次读取一次消息,如果过程中leader写入了消息那么也会自动执行这个拉取任务
8. Kafka的时间轮延时调度机制(一):O(1)时间复杂度
Kafka内部有很多延时任务,没有基于JDK Timer来实现,那个插入和删除任务的时间复杂度是O(nlogn),而是基于了自己写的时间轮来实现的,时间复杂度是O(1),其实Netty、ZooKeeper、Quartz很多中间件都会实现时间轮
延时任务是很多很多的,大量的发送消息以及拉取消息,都会涉及到延时任务,任务数量很多,如果基于传统的JDK Timer把大量的延时任务频繁的插入和删除,时间复杂度是O(nlogn)性能比较低的
时间轮的机制,延时任务插入和删除,O(1)
简单来说,一个时间轮(TimerWheel)就是一个数组实现的存放定时任务的环形队列,数组每个元素都是一个定时任务列表(TimerTaskList),这个TimerTaskList是一个环形双向链表,链表里的每个元素都是定时任务(TimerTask)
时间轮是有很多个时间格的,一个时间格就是时间轮的时间跨度tickMs,wheelSize就是时间格的数量,时间轮的总时间跨度就是tickMs * wheelSize(interval),然后还有一个表盘指针(currentTime),就是时间轮当前所处的时间
currentTime指向的时间格就是到期,需要执行里面的定时任务
比如说tickMs = 1ms,wheelSize = 20,那么时间轮跨度(inetrval)就是20ms,刚开始currentTime = 0,这个时候如果有一个延时2ms之后执行的任务插入进来,就会基于数组的index直接定位到时间轮底层数组的第三个元素
因为tickMs = 1ms,所以第一个元素代表的是0ms,第二个元素代表的是1ms的地方,第三个元素代表的就是2ms的地方,直接基于数组来定位就是O(1)是吧,然后到数组之后把这个任务插入其中的双向链表,这个时间复杂度也是O(1)
所以这个插入定时任务的时间复杂度就是O(1)
然后currentTime会随着时间不断的推移,1ms之后会指向第二个时间格,2ms之后会指向第三个时间格,这个时候就会执行第三个时间格里刚才插入进来要在2ms之后执行的那个任务了
这个时候如果插入进来一个8ms之后要执行的任务,那么就会放到第11个时间格上去,相比于currentTime刚好是8ms之后,对吧,就是个意思,然后如果是插入一个19ms之后执行的呢?那就会放在第二个时间格
每个插入进来的任务,他都会依据当前的currentTime来放,最后正好要让currentTime转动这么多时间之后,正好可以执行那个时间格里的任务
9. Kafka的时间轮延时调度机制(二):多层级时间轮
接着上一讲的内容,那如果这个时候来一个350毫秒之后执行的定时任务呢?已经超出当前这个时间轮的范围了,那么就放到上层时间轮,上层时间轮的tickMs就是下层时间轮的interval,也就是20ms
wheelSize是固定的,都是20,那么上层时间轮的inetrval周期就是400ms,如果再上一层的时间轮他的tickMs是400ms,那么interval周期就是8000ms,也就是8s,再上一层时间轮的tickMs是8s,interval就是160s,也就是好几分钟了,以此类推即可
反正有很多层级的时间轮,一个时间轮不够,就往上开辟一个新的时间轮出来,每个时间轮的tickMs是下级时间轮的interval,而且currentTime就跟时钟的指针一样是不停的转动的,你只要根据定时周期把他放入对应的轮子即可
每个轮子插入的时候根据currentTime,放到对应时间之后的时间格即可
比如定时350ms后执行的任务,就可以放到interval位400ms的时间轮内,currentTime自然会转动到那个时间格来执行他
10. Kafka的时间轮延时调度机制(三):时间轮层级的下滑
接着上一讲的内容,那如果这个时候来一个350毫秒之后执行的定时任务呢?已经超出当前这个时间轮的范围了,那么就放到上层时间轮,上层时间轮的tickMs就是下层时间轮的interval,也就是20ms
wheelSize是固定的,都是20,那么上层时间轮的inetrval周期就是400ms,如果再上一层的时间轮他的tickMs是400ms,那么interval周期就是8000ms,也就是8s,再上一层时间轮的tickMs是8s,interval就是160s,也就是好几分钟了,以此类推即可
反正有很多层级的时间轮,一个时间轮不够,就往上开辟一个新的时间轮出来,每个时间轮的tickMs是下级时间轮的interval,而且currentTime就跟时钟的指针一样是不停的转动的,你只要根据定时周期把他放入对应的轮子即可
每个轮子插入的时候根据currentTime,放到对应时间之后的时间格即可
比如定时350ms后执行的任务,就可以放到interval位400ms的时间轮内,currentTime自然会转动到那个时间格来执行他
11. Kafka的时间轮延时调度机制(四):基于DelayQueue推动
基于数组和双向链表来O(1)时间度可以插入任务
但是推进时间轮怎么做呢?搞一个线程不停的空循环判断是否进入下一个时间格吗?那样很浪费CPU资源,所以采取的是DelayQueue
每个时间轮里的TimerTaskList作为这个时间格的任务列表,都会插入DelayQueue中,设置一个延时出队时间,DelayQueue会自动把过期时间最短的排在队头,然后专门有一个线程来从DelayQueue里获取到期任务列表文章来源:https://www.toymoban.com/news/detail-698776.html
某个时间格对应的TimerTaskList到期之后,就会被线程获取到,这种方式就可以实现时间轮推进的效果,推进时间轮基于DelayQueue,时间复杂度也是O(1),因为只要从队头获取即可
 文章来源地址https://www.toymoban.com/news/detail-698776.html
文章来源地址https://www.toymoban.com/news/detail-698776.html
到了这里,关于Kafka核心原理第二弹——更新中的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!