目录
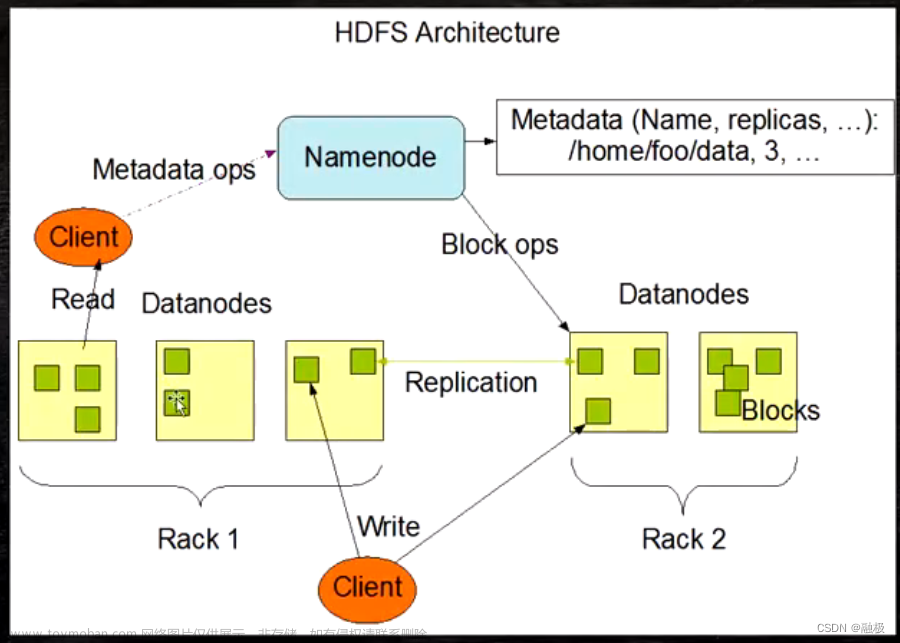
HDFS的基础架构
VMware虚拟机部署HDFS集群
HDFS集群启停命令
HDFS Shell操作
hadoop 命令体系:
创建文件夹 -mkdir
查看目录内容 -ls
上传文件到hdfs -put
查看HDFS文件内容 -cat
下载HDFS文件 -get
复制HDFS文件 -cp
追加数据到HDFS文件中 -appendToFile
HDFS文件移动 -mv
删除HDFS文件 -rm
HDFS存储原理
存储原理
修改副本数量
fsck检查文件副本状态
NameNode元数据
edits和fsimage文件
元数据合并参数
SecondaryNameNode的作用
HDFS数据的读写请求
HDFS的基础架构
Hadoop由三个部分组成,分别是HDFS、MapReduce和yarn:

HDFS由三个角色,主角色、从角色、主角色辅助角色:

NameNode:
- HDFS系统的主角色,是一个独立的进程
- 负责管理HDFS整个文件系统
- 负责管理DataNode
SecondaryNameNode:
- NameNode的辅助,是一个独立进程
- 主要帮助NameNode完成元数据整理工作
DataNode:
- HDFS系统的从角色,是一个独立进程
- 主要负责数据的存储,即存入数据和取出数据
VMware虚拟机部署HDFS集群
第二章-04-[实操]VMware虚拟机部署HDFS集群_哔哩哔哩_bilibili
HDFS集群启停命令
执行原理:
执行原理:
$HADOOP_HOME/sbin/hadoop-daemon.sh,此脚本可以单独控制所在机器的进程的启停
用法:hadoop-daemon.sh (start|status|stop) (namenode|secondarynamenode|datanode)
或者 hdfs --daemon (start|status|stop) (namenode|secondarynamenode|datanode)
HDFS Shell操作
hadoop 命令体系:
hadoop fs [generic options] 或者 hdfs dfs [generic options]
没有任何区别
创建文件夹 -mkdir
hdfs dfs -mkdir [-p] <path> 查看目录内容 -ls
清测-ll等是不可行的
hdfs dfs -ls [-h] [-R] [<path> ...] -h 人性化显示文件 -R 递归查看指定目录及其子目录
上传文件到hdfs -put
hdfs dfs -put [-f] [-p] <localsrc> ... <dst>
- -f 覆盖目标文件(已存在下)
- -p 保留访问和修改时间,所有权和权限
- localsrc 本地文件系统(客户端所在机器)
- dst 目标文件系统(HDFS)
-
查看HDFS文件内容 -cat
-
hdfs dfs -cat <src> ...当文件很大时,可以配合more翻页
-
hdfs dfs -cat <src> | more下载HDFS文件 -get
-
hdfs dfs -get [-f] [-p] <src> ... <localdst>下载文件到本地文件系统指定目录,localdst必须是目录
-f 覆盖目标文件(已存在下)
-p 保留访问和修改时间,所有权和权限。
-
复制HDFS文件 -cp
-
hdfs dfs -cp [-f] <src> ... <dst>src和dst都只能是hdfs的文件路径
-
追加数据到HDFS文件中 -appendToFile
-
HDFS的文件修改只支持追加和删除
-
hdfs dfs -appendToFile <localsrc> ... <dst>将localsrc的内容追加到dst
-
HDFS文件移动 -mv
-
hdfs dfs -mv <src> ... <dst>移动文件到指定文件夹下,可以使用该命令移动数据,重命名文件的名称
-
删除HDFS文件 -rm
-
hdfs dfs -rm -r [-skipTrash] URI [URI ...]删除指定路径的文件或文件夹 -skipTrash 跳过回收站,直接删除
-
回收站功能默认关闭,如果要开启需要在core-site.xml内配置:
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>120</value>
</property>
无需重启集群,在哪个机器配置的,在哪个机器执行命令就生效。
回收站默认位置在:/user/用户名(hadoop)/.Trash
-
其他的一些用法跟linux里面是基本一致的
-
HDFS存储原理
-
存储原理
- 将每个文件分成n(n个服务器)份,每一份又分成m个block(Block块,HDFS最小存储单位,每个256MB(可以修改))
- 分成block的目的是统一hdfs的存储单元,便于管理
-


但是这样如果丢了一个block,那么整个文件都会失效,那么 使用备份解决
将每个block备份n份,放入不同的服务器


修改副本数量
可以在hdfs-site.xml中配置属性以设置默认文件上传到HDFS中拥有的副本数量:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
一般不需要设置,默认是3
除了配置文件外,我们还可以在上传文件的时候,临时决定被上传文件以多少个副本存储。
hadoop fs -D dfs.replication=2 -put test.txt /tmp/如上命令,就可以在上传test.txt的时候,临时设置其副本数为2
对于已经存在HDFS的文件,修改dfs.replication属性不会生效,如果要修改已存在文件可以通过命令
hadoop fs -setrep [-R] 2 path如上命令,指定path的内容将会被修改为2个副本存储。-R选项可选,使用-R表示对子目录也生效。
fsck检查文件副本状态
hdfs fsck path [-files [-blocks [-locations]]]fsck可以检查指定路径是否正常
- -files可以列出路径内的文件状态
- -files -blocks 输出文件块报告(有几个块,多少副本)
- -files -blocks -locations 输出每一个block的详情

红色线表示副本数量(这里是总的数量,也就是总共3个block)
蓝色的是三个block存放的位置,可以看到是存放在了三个不同的服务器

0:hdfs系统的状态 1:有多少个副本 2:丢失了多少blocks
NameNode元数据
edits和fsimage文件
Hadoop是通过NameNode来记录和整理文件和block的关系
NameNode基于一批edits和一个fsimage文件的配合完成整个文件系统的管理和维护
edits文件,是一个流水账文件,记录了hdfs中的每一次操作,以及本次操作影响的文件其对应的block,会有多个edits文件

将全部的edits文件,合并为最终结果,即可得到一个Fsimage文件

对于存放的位置,在hdfs-site.xml文件中,配置了
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
那么此处的edits和fsimage就存放在了data/nn文件夹下的current文件夹
元数据合并参数
对于元数据合并成fsimage,是一个定时过程,基于两个参数
dfs.namenode.checkpoint.period,默认3600(秒)即1小时
dfs.namenode.checkpoint.txns,默认1000000,即100W次事务
只需要达到一个条件就需要合并
默认60秒检查一次是否符合条件,基于
dfs.namenode.checkpoint.check.period,默认60(秒),来决定
SecondaryNameNode的作用
SecondaryNameNode会通过http从NameNode拉取数据(edits和fsimage)然后合并完成后提供给NameNode使用文章来源:https://www.toymoban.com/news/detail-699356.html
HDFS数据的读写请求
数据写入流程文章来源地址https://www.toymoban.com/news/detail-699356.html
- 1. 客户端向NameNode发起请求
- 2. NameNode审核权限、剩余空间后,满足条件允许写入,并告知客户端写入的DataNode地址(一般来说会分配网络距离最近的datanode)
- 3. 客户端向指定的DataNode发送数据包
- 4. 被写入数据的DataNode同时完成数据副本的复制工作,将其接收的数据分发给其它DataNode
- 5. 写入完成客户端通知NameNode,NameNode做元数据记录工作
- 数据读取流程
- 1、客户端向NameNode申请读取某文件
- 2、 NameNode判断客户端权限等细节后,允许读取,并返回此文件的block列表
- 3、客户端拿到block列表后自行寻找DataNode读取即可(会去找最近的datanode)
到了这里,关于Hadoop:HDFS--分布式文件存储系统的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!