目录
什么是bigkey?
bigkey引发的问题
如何查找bigkey
redis-cli --bigkeys
MEMORY USAGE
bigKey如何删除
渐进式删除
unlink
bigKey生产调优
什么是bigkey?
bigkey简单来说就是存储本身的key值空间太大,或者hash,list,set等存储中value值过多。
具体来衡量的话大key是:
- String 类型值大于10KB。
- Hash、List、Set、Zset类型元素个数超过5000个。
bigkey引发的问题
- 阻塞工作线程:如果我们使用del命令删除大key,会阻塞工作线程这样就没有办法处理其他客户端发过来的命令了。
bigkey的体积与删除耗时可参考下表:
key类型 field数量 耗时 Hash 100万 1000ms List 100万 1000ms Set 100万 1000ms ZSet 100万 1000ms
- 内存分布不均: 集群模型在slot分片均匀情况下会出现数据和查询倾斜的情况,部分有大key的Redis结点占用内存较多。
- 客户端超时阻塞: Redis的工作线程只有一个,操作这个大key会比较耗时会阻塞Redis在客户端看来就说很久很久没有响应。
- 引发网络阻塞: 每次获取大key产生的网络流量比较大,这对于网卡比较小的服务器是灾难性的。
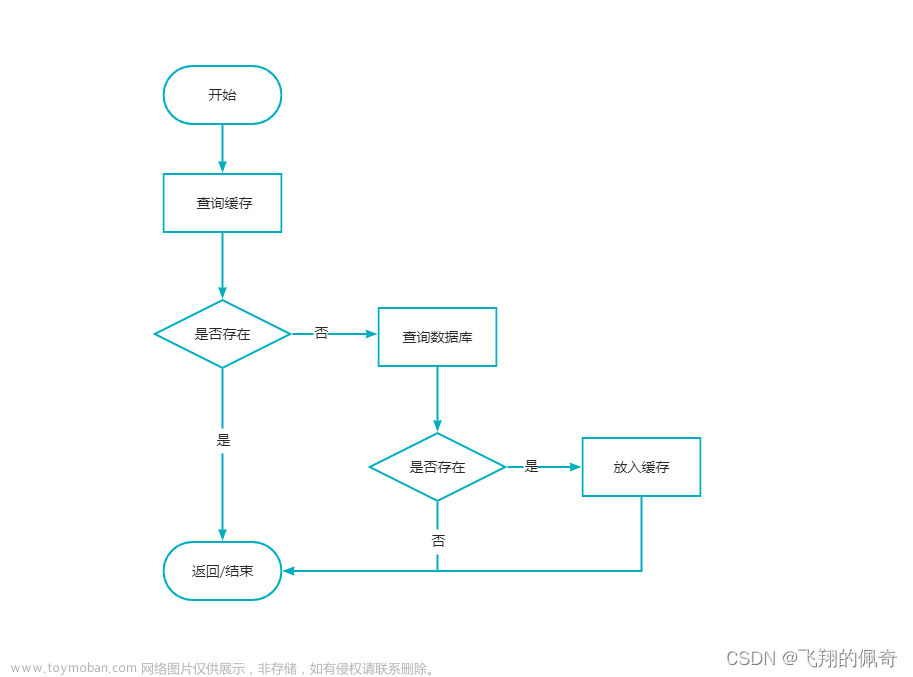
如何查找bigkey
redis-cli --bigkeys
可以通过redis客户端提供的命令 redis-cli --bigkeys来查看
$ redis-cli --bigkeys
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.01 to sleep 0.01 sec
# per SCAN command (not usually needed).
[00.00%] Biggest string found so far 'key-419' with 3 bytes
[05.14%] Biggest list found so far 'mylist' with 100004 items
[35.77%] Biggest string found so far 'counter:__rand_int__' with 6 bytes
[73.91%] Biggest hash found so far 'myobject' with 3 fields
-------- summary -------
Sampled 506 keys in the keyspace!
Total key length in bytes is 3452 (avg len 6.82)
Biggest string found 'counter:__rand_int__' has 6 bytes
Biggest list found 'mylist' has 100004 items
Biggest hash found 'myobject' has 3 fields
504 strings with 1403 bytes (99.60% of keys, avg size 2.78)
1 lists with 100004 items (00.20% of keys, avg size 100004.00)
0 sets with 0 members (00.00% of keys, avg size 0.00)
1 hashs with 3 fields (00.20% of keys, avg size 3.00)
0 zsets with 0 members (00.00% of keys, avg size 0.0好处:给出每种数据结构Top 1 bigkey,同时给出每种数据类型的键值个数+平均大小
不足:想查询大于10kb的所有key,–bigkeys参数就无能为力了,需要用到memory usage来计算每个键值的字节数
在使用这个命令来查询大key时,最好在从节点上执行。如果在主节点上执行会阻塞从节点。
MEMORY USAGE
MEMORY USAGE key [SAMPLES count]MEMORY USAGE 命令给出一个 key 和它的值在 RAM 中所占用的字节数。 返回的结果是 key 的值以及为管理该 key 分配的内存总字节数。
对于嵌套数据类型,可以使用选项 SAMPLES,其中 count 表示抽样的元素个数,默认值为 5 。当需要抽样所有元素时,使用 SAMPLES 0 。
> SET foo bar
OK
> MEMORY USAGE foo
(integer) 54
> SET cento 01234567890123456789012345678901234567890123
45678901234567890123456789012345678901234567890123456789
OK
127.0.0.1:6379> MEMORY USAGE cento
(integer) 153返回值: 整数( 使用的内存的字节数。)
bigKey如何删除
如果一下子释放大量的内存,空闲内存块链表操作时间会增加,相应地就会造成Redis主线程阻塞,如果redis主线程发生了阻塞其他客户端的请求可能会超时,如果超时的连接越来越多会造成各自异常问题。
因此我们删除大key这一个动作,一般有两种方法:
- 渐进式删除
- 异步删除(unlink)
渐进式删除
大key逐步拆解,一点一点删,直到没有。
- list: 使用ltrim渐进式逐步删除,直到全部删除完成
- set: 使用sscan每次获取部分元素,在使用srem命令删除每个元素
- zset: 使用zscan每次获取部分元素,在使用zremrangebyrank命令删除每个元素
- hash使用hscan每次获取少量field-value,再使用hdel删除每个field
unlink
对于string类型可以使用del也可以使用unlink
unlink命令是Redis提供的另一种删除键的命令。它的语法与del命令类似:
UNLINK key [key ...]其中,key是要删除的键名。可以指定多个键名,删除多个键。如果指定的键不存在,则会被忽略。
del命令是一种同步删除命令,会阻塞客户端,直到所有指定的键都被删除为止。而unlink命令是一种异步删除命令,会立即返回,不会阻塞客户端。
del命令返回被删除键的数量,而unlink命令不会返回被删除键的数量。这是因为unlink命令是异步执行的,Redis无法立即知道已经删除的键的数量。
bigKey生产调优
redis.conf配置文件LAZY FREEING相关说明:阻塞和非阻塞删除命令
Redis 有两个原语来删除键。一种称为 DEL,是对象的阻塞删除这意味着服务器停止处理新命令,以便以同步方式回收与对象关联的所有内存。如果删除的键与一个小对象相关联,则执行 DEL 命令所需的时间非常短,可与大多数其他命令相媲美Redis 中的 0(1)或 o(log_N) 命令。 但是,如果键与包含数百万个元素的聚合值相关联,则服务器可能会阻塞很长时间(甚至几秒钟) 才能完成操作。
基于上述原因,Redis 还提供了非阻塞删除原语,例如 UNLINK (非阻塞 DEL) 以及 FLUSHALL和 FLUSHDB 命令的 ASYNC 选项,以便在后台回收内存。 这些命令在恒定时间内执行。另一个线程将尽可能快地逐步释放后台中的对象。
FLUSHALL和 FLUSHDB 的 DEL、UNLINK 和 ASYNC 选项是用户控制的。这取决于应用程序的设计,以了解何时使用其中一个是个好主意。然而,作为其他操作的副作用,Redis 服务器有时不得不删除键或刷新整个数据库。 具体而言,Redis 在以下场景中独立于用户调用删除对象。
优化配置:我们可以将配置文件当中的这些参数设置为yes,也就是懒释放文章来源:https://www.toymoban.com/news/detail-699466.html
 文章来源地址https://www.toymoban.com/news/detail-699466.html
文章来源地址https://www.toymoban.com/news/detail-699466.html
到了这里,关于Redis之bigkey问题解读的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!