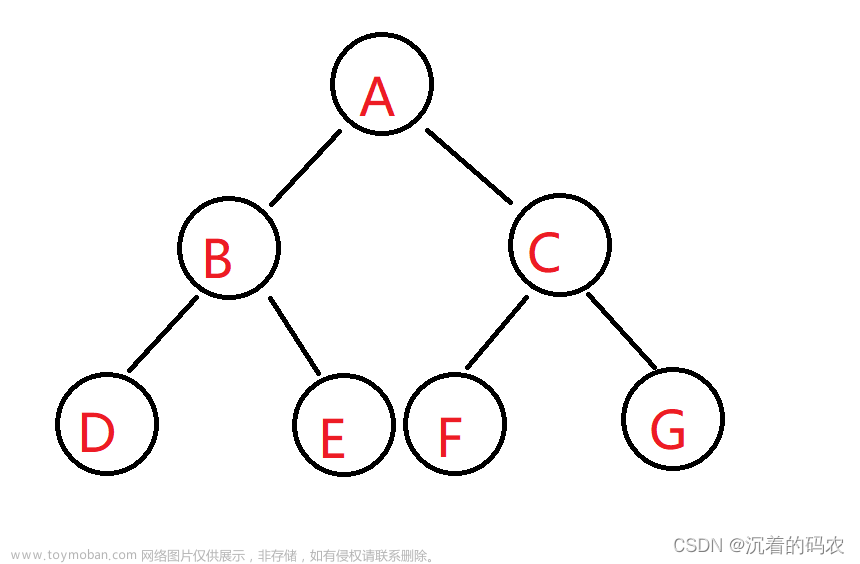
二叉树线索化
线索化概念:
为什么要转换为线索化
二叉树线索化是一种将普通二叉树转换为具有特殊线索(指向前驱和后继节点)的二叉树的过程。这种线索化的目的是为了提高对二叉树的遍历效率,特别是在不使用递归或栈的情况下进行遍历。
将二叉树线索化的主要目的是为了提高对二叉树的遍历效率以及节省存储空间。线索化使得在不使用递归或栈的情况下可以更快速地进行遍历,特别是在特定顺序的遍历时,如前序、中序或后序遍历。
提高遍历效率:线索化后,可以在常量时间内找到节点的前驱和后继节点,从而实现更高效的遍历。这对于需要频繁遍历大型二叉树或需要在树的中间部分执行插入和删除操作时特别有用。
无需递归或栈:线索化的二叉树允许你在遍历时省去递归或栈的开销,因为你可以沿着线索直接访问节点的前驱和后继,从而降低了内存和时间复杂度。
节省存储空间:线索化可以用较少的额外存储空间来实现。通常,只需为每个节点添加一个或两个指针来存储线索信息,而不需要额外的数据结构(如堆栈)来辅助遍历。
支持双向遍历:线索化的二叉树可以支持双向遍历,即可以在给定节点的前向和后向方向上遍历树。这在某些应用中很有用,例如双向链表的操作。
节省计算资源:在某些特定的应用场景中,通过线索化可以避免重复计算,因为可以直接访问前驱和后继节点,而无需再次搜索或遍历
树的遍历
先给定一棵树,然后对他进行每种遍历:
前序遍历:
前序遍历,就是先遍历根节点在遍历左子树,在遍历右子树;
他的顺序就是:根节点->左子树->右子树
根据递归先遍历了根节点,然后递归左子树,回溯后在进行遍历右子树的一个过程;
例如上图开始前序遍历:
遍历根节点50,然后递归左子树,34,现在把34看为根节点继续递归左子树,28,然后把28看作根节点,继续遍历左子树,19,然后把19看为根节点继续遍历,然后左子树为空,开始回溯,回溯到19,遍历右子树也为空,继续回溯到结点28,遍历右子树,31;然后通过这种思想一直进行遍历最总遍历完整棵子树;
前序遍历结果:50,34,28,19,31,41,81,72,95
中序遍历:
顺序是:左子树->根节点->右子树
其实在理解了前序遍历后,中序遍历也差不多的,刚才是先记录了根节点,现在开始,先一直递归遍历左子树,递归到没有左子树的时开始记录,比如上图递归到19,然后回溯,28,遍历右子树31,回溯34,遍历右子树41,回溯50,遍历右子树;然后最终的结果就是:
19,28,31,34,41,50,72,81,95;
中序遍历就是,找到子树的最左边的那个结点,然后回溯到它的父节点,然后遍历他父节点的右子树,然后到右子树中又去找它的最左的结点,这样一直经过这样的操作,最终完成中序遍历。
后序遍历:
顺序是:左子树->右子树->根节点
先是左子树,那就先找到左子树中的最左边的结点,19,然后回溯,遍历右子树,然后再右子树中找最左边的结点,31,回溯28,然后在回溯;这样的一个过程;
最终结果就是:
19,31,28,41,34,72,95,81,50
后序遍历,看着比中序和后序遍历难理解,其实只要懂得了递归回溯的那个过程,就思路回非常的清晰;然后大概的过程就是先遍历左子树,找到左子树中最左边的结点,回溯,然后遍历右子树,遍历右子树的过程也是先遍历右子树中的左子树,然后再进行遍历右子树的右子树,最后来遍历他们的根节点;
3种遍历的代码实现:
void pre_orderNode(Node *root) {前序 if (!root) return ; printf("%d ", root->data);//先输出根节点 pre_orderNode(root->lchild);//遍历左子树 pre_orderNode(root->rchild);//遍历右子树 return ; } void in_orderNode(Node *root) {中序 if (!root) return ; in_orderNode(root->lchild);//先遍历左子树 printf("%d ", root->data);//在打印根节点的值 in_orderNode(root->rchild);//在遍历右子树 return ; } void post_orderNode(Node *root) {后序 if (!root) return ; post_orderNode(root->lchild);//先遍历左子树 post_orderNode(root->rchild);//在遍历右子树 printf("%d ", root->data);//最终打印根节点值 return ; }可以去理解一下代码,尝试在纸上或者脑子里执行以下代码,模拟运行以下;

二叉树前序线索化:
如图上图一个简单的二叉树,现在是将这个二叉树进行前序线索化,那么前序遍历的顺序是根节点->左子树->右子树;
那么根节点就应该在条线的头部,然后再去遍历左子树和右子树,那么这个数的前序遍历结果是50,34,79;
那么就可以将二叉树样来看,50是34的前驱,79是34的后继,前驱就是在遍历在他前面的,后继就是在他后面遍历的;
现在我们将每个结点的指向两个子孩子指针改变为指向他的前驱和后继:
通过这样的转换,那这棵树就转换为一条双向链表了:
其中会发下50和79的会右一颗子树指向NULL,那么就需要用一个变量来记录,他是否右前驱或者后继;
就是这样的一个转换,也证明了概念种的节省空间,不用递归遍历,可以双向遍历,提高了遍历效率;
下面是代码实现:
#include <stdio.h> #include <stdlib.h> #include <time.h> #define NORMAL 0 #define THRENA 1 //这里左儿子记录前驱,右儿子记录后继 typedef struct Node { int val, ltag, rtag;//val结点的值,ltag记录是否有前驱,rtag记录是否有后继 struct Node *lchild, *rchild; } Node; Node *getNewNode(int val) {//获取新的结点 Node *root = (Node *)malloc(sizeof(Node)); root->lchild = root->rchild = NULL; root->rtag = root->ltag = NORMAL;//NORMAL表示还未有前驱或后继 root->val = val; return root; } Node *insert(Node *root, int val) {//添加结点,组成普通的二叉树 if (!root) return getNewNode(val); if (root->val == val) return root; if (root->val > val) root->lchild = insert(root->lchild, val); else root->rchild = insert(root->rchild, val); return root; } void build_Thread(Node *root) {//建立线索化 if (!root) return ; static Node *pre = NULL;//使用静态变量使得pre值不随程序递归而改变 Node *left = root->lchild;//记录当前结点左右儿子 Node *right = root->rchild; if (root->ltag == NORMAL) {//当前结点没有前驱结点 root->lchild = pre;//给当前结点赋值前驱结点 root->ltag = THRENA;//标记有前驱结点 } if (pre && pre->rtag == NORMAL) {//如果它的前驱结点没有后继,并且前驱结点不为NULL pre->rchild = root;//将前驱结点的后继附上当前结点 pre->rtag = THRENA;//标记前驱结点有后继了 } pre = root;//pre等于当前递归的结点 build_Thread(left);//递归左子树 build_Thread(right);//在递归右子树 return ; } void output(Node *root) {//遍历线索化二叉树 if (!root) return ; Node *p = root; while (p) { printf("%d ", p->val); if (p->rtag == THRENA) p = p->rchild;//说明当前结点有后继直接往右节点也就是后继结点继续遍历 else if (p->rtag == NORMAL) break;//如果当前结点没有后继结束遍历 } return ; } void preface(Node *root) {//普通前序递归遍历 if (!root) return ; printf("%d ", root->val); if (root->ltag == NORMAL) preface(root->lchild); if (root->rtag == NORMAL) preface(root->rchild); return ; } void clearNode(Node *root) {//回收空间 if (!root) return ; if (root->ltag == NORMAL) clearNode(root->lchild); if (root->rtag == NORMAL) clearNode(root->rchild); free(root); return ; } int main() { srand(time(0));//获取当期计算时间,获取随机数 Node *root = NULL; for (int i = 0; i < 10; i++) { int val = rand() % 100; root = insert(root, val); } preface(root);//先打印普通前序遍历 putchar(10);//换行 build_Thread(root);//建立线索化 output(root);//输出前序线索化 putchar(10); clearNode(root); return 0; }二叉树中序线索化:
中序遍历顺序:左子树->根节点->右子树
那么结果借是34,50,79
转换线索化,那么34就是50的前驱,50就是34的后继;和前序遍历的是一样的;
直接来看代码实现:文章来源:https://www.toymoban.com/news/detail-699847.html
#include <stdio.h> #include <stdlib.h> #include <time.h> #define NORMAL 0 //表示没有 #define THRENA 1 //表示有 //这里左儿子记录前驱,右儿子记录后继 typedef struct Node { int val, ltag, rtag;///val结点的值,ltag记录是否有前驱,rtag记录是否有后继 struct Node *lchild, *rchild; } Node; Node *getNewNode(int val) {///获取新的结点 Node *p = (Node *)malloc(sizeof(Node)); p->val = val; p->lchild = p->rchild = NULL; p->ltag = p->rtag = NORMAL;//NORMAL表示还未有前驱或后继 return p; } Node *insert(Node *root, int val) {//添加结点,组成普通的二叉树 if (!root) return getNewNode(val); if (root->val == val) return root; if (root->val > val) root->lchild = insert(root->lchild, val); else root->rchild = insert(root->rchild, val); return root; } void in_order(Node *root) {//普通递归中序遍历 if (!root) return ; if (root->ltag == NORMAL) in_order(root->lchild); printf("%d ", root->val); if (root->rtag == NORMAL) in_order(root->rchild); return ; } void build_Thread(Node *root) {//建立线索化 if (!root) return ; static Node *pre = NULL;//使用静态变量使得pre值不随函数递归过程改变而改变 build_Thread(root->lchild);//由于是中序遍历,先递归到最左结点 //中间过程就是想当于根节点 if (root->ltag = NORMAL) { root->lchild = pre; root->ltag = THRENA; } if (pre && pre->rchild == NORMAL) { pre->rchild = root; pre->rtag = THRENA; } pre = root; build_Thread(root->rchild);//然后再遍历右子树 return ; } Node *most_left(Node *root) {//找到最左结点 Node *temp = root; while (temp && temp->ltag == NORMAL && temp->lchild != NULL) temp = temp->lchild; return temp; } void output(Node *root) { if (!root) ; Node *p = most_left(root);//从最左结点开始遍历 while (p) { printf("%d ", p->val); if (p->rtag == THRENA) p = p->rchild;//如果后继存在进行遍历后继 else p = most_left(p->rchild);//找到右子树的最左结点继续遍历 } return ; } void clear(Node *root) { if (!root) return ; if (root->ltag == NORMAL) clear(root->lchild); if (root->rtag == NORMAL) clear(root->rchild); free(root); return ; } int main() { srand(time(0)); Node *root = NULL; for (int i = 0; i < 10; i++) { int val = rand() % 100; root = insert(root, val); } in_order(root); putchar(10); build_Thread(root); output(root); putchar(10); clear(root); return 0; }二叉树后序线索化:
直接上代码演示,如果前面两种你都弄懂了那么,后序理解起来也非常容易:文章来源地址https://www.toymoban.com/news/detail-699847.html
#include <stdio.h> #include <stdlib.h> #include <time.h> #define NORMAL 0 #define THRENA 1 typedef struct Node { int val, ltag, rtag; struct Node *lchild, *rchild; } Node; Node *getNewNode(int val) { Node *root = (Node *)malloc(sizeof(Node)); root->lchild = root->rchild = NULL; root->rtag = root->ltag = NORMAL; root->val = val; return root; } Node *insert(Node *root, int val) { if (!root) return getNewNode(val); if (root->val == val) return root; if (root->val > val) root->lchild = insert(root->lchild, val); else root->rchild = insert(root->rchild, val); return root; } void build_Thread(Node *root) { if (!root) return ; static Node *pre = NULL; build_Thread(root->lchild); build_Thread(root->rchild); if (root->ltag == NORMAL) { root->lchild = pre; root->ltag = THRENA; } if (pre && root->rtag == NORMAL) { pre->rchild = root; pre->rtag = THRENA; } pre = root; return ; } Node *most_left(Node *root) { while (root && root->ltag == THRENA && root->lchild) root = root->lchild; return root; } void output(Node *root) { if (!root) return ; Node *p = most_left(root); while (p) { printf("%d ", p->val); if (p->rtag == THRENA) p = p->rchild; else if (p->rtag == NORMAL) break; } return ; } void back_order(Node *root) { if (!root) return ; if (root->ltag == NORMAL) back_order(root->lchild); if (root->rtag == NORMAL) back_order(root->rchild); printf("%d ", root->val); return ; } void preface(Node *root) { if (!root) return ; printf("%d(", root->val); if (root->ltag == NORMAL) preface(root->lchild); printf(","); if (root->rtag == NORMAL) preface(root->rchild); printf(")"); return ; } void clearNode(Node *root) { if (!root) return ; if (root->ltag == NORMAL) clearNode(root->lchild); if (root->rtag == NORMAL) clearNode(root->rchild); free(root); return ; } int main() { srand(time(0)); Node *root = NULL; for (int i = 0; i < 10; i++) { int val = rand() % 100; root = insert(root, val); } preface(root); putchar(10); back_order(root); putchar(10); build_Thread(root); output(root); putchar(10); clearNode(root); return 0; }




到了这里,关于数据结构——二叉树线索化遍历(前中后序遍历)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!