1.Lookup join
概念:Lookup join是针对于由作业流表触发,关联右侧维表来补全数据的场景 。
默认情况下,在流表有数据变更,都会触发维表查询(可以通过设置维表是否缓存,来减轻查询压力),由于不保存状态,因此对内存占用较小。(以上来自网络)
具体配置如下:
SET execution.checkpointing.interval=5000;
SET state.checkpoints.dir=hdfs://hadoop01:9000/flink/checkpoints/2023090510549999;
SET execution.runtime-mode=streaming;
// 定义维表,维表 可以有主键,不能有水位线字段
CREATE TEMPORARY TABLE source_dim_dept (
`id` BIGINT,
`dept` STRING,
PRIMARY KEY(id) NOT ENFORCED
) WITH (
'connector'='jdbc',
'url'='jdbc:mysql://1.1.1.1:3306/data_storage?autoReconnect=true&useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&serverTimezone=Asia/Shanghai',
'username'='data_manage',
'password'='xxxxxx',
'table-name'='source_dim_dept ',
'lookup.cache'='PARTIAL',
'lookup.partial-cache.expire-after-write'='30s',
'lookup.cache.ttl' = '30s',
'lookup.cache.max-rows'='5',
'lookup.partial-cache.max-rows'='5'
);
// 流表 -流表必须要有 PROCTIME(),和 水位线字段
CREATE TABLE source_kafka_stream_data(
`id` BIGINT,
`ts` BIGINT,
`price` FLOAT,
proc_time AS PROCTIME(),
`auto_row_time` AS cast(CURRENT_TIMESTAMP as timestamp(3)),
WATERMARK FOR `auto_row_time` AS `auto_row_time` - INTERVAL '0' SECONDS
) WITH (
'connector'='kafka',
'properties.group.id'='data_processing_producer',
'scan.startup.mode'='group-offsets',
'properties.auto.offset.reset'='latest',
'topic'='data-paimon-test',
'properties.bootstrap.servers'='1.1.1.1:9192',
'format'='json'
);
CREATE VIEW transform_tableJoin_XeH7VK1o2U AS
select `status`,`id`,`ts`,`price`, PROCTIME() as auto_row_time from (
select c.`dept` as `status`,c.`id` as `id`,O.`ts` as `ts`,O.`price` as `price`
from source_kafka_stream_data AS O
JOIN source_dim_dept FOR SYSTEM_TIME AS OF O.proc_time AS c
on O.id=c.id ) ;
*注意坑在这里:上述的 连接中流表的时间字段一定要用 PROCTIME() 类型的 AS OF O.proc_time,如果 用水位线字段则Flink 会转为TemperalJoin
而不是Lookup join
// 以下是输出,无特殊配置
CREATE CATALOG paimon WITH (
'type' = 'paimon',
'warehouse' = 'hdfs://hadoop01:9000/painmon/data-processing/paimon_ods'
);
USE CATALOG paimon;
create database if not exists paimon.paimon_ods_db;
drop table if exists paimon_ods_db.paimon_test_stream_join;
CREATE TABLE if not exists paimon_ods_db.paimon_test_stream_join(
`uuid` STRING,
`status` STRING,
`id` BIGINT,
`ts` BIGINT,
`price` DOUBLE
) WITH (
'sink.parallelism'='8',
'bucket'='8',
'bucket-key'='uuid',
'write-mode'='append-only',
'sink.use-managed-memory-allocator'='true',
'sink.managed.writer-buffer-memory'='512MB',
'num-sorted-run.compaction-trigger'='20',
'write-buffer-size'='1024MB',
'write-buffer-spillable'='true'
);
INSERT INTO paimon_ods_db.paimon_test_stream_join select uuid(),`status`,`id`,`ts`,`price` from default_catalog.default_database.transform_tableJoin_XeH7VK1o2U;文章来源地址https://www.toymoban.com/news/detail-699996.html
2.Temporal join 时态表连接
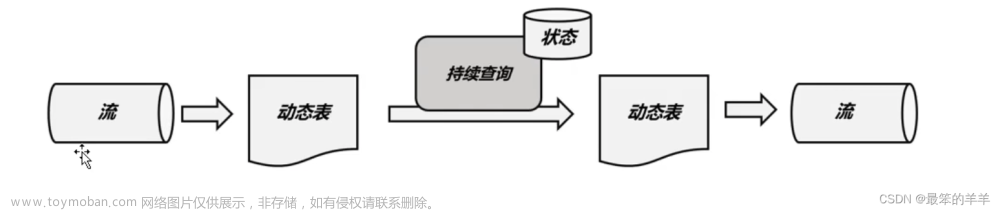
时态表是一个随时间演变的表,在Flink中也称为动态表。
时态表中的行与一个或多个时态周期相关联,并且所有Flink表都是时态的(动态的)。时态表包含一个或多个版本化的表快照,它可以是跟踪更改的更改历史表(例如数据库更改日志,包含所有快照),也可以是具体化更改的维表(例如包含最新快照的数据库表)。
时态表可以分为版本表和普通表。
版本表:如果时态表中的记录可以追踪和并访问它的历史版本,这种表我们称之为版本表,来自数据库的 changelog (如mysql binlog)可以定义成版本表,版本表内的数据始终不会自动清理,只能通过upsert触发。
普通表:如果时态表中的记录仅仅可以追踪并和它的最新版本,这种表我们称之为普通表,来自数据库 或 HBase 、redis的表可以定义成普通表。
(以上来自网络)
SET execution.checkpointing.interval=5000;
SET state.checkpoints.dir=hdfs://hadoop01:9000/flink/checkpoints/2023090510549999;
SET execution.runtime-mode=streaming;
// 定义维表,维表一定要有主键和水位线字段
CREATE TEMPORARY TABLE source_dim_dept (
`id` BIGINT,
`dept` STRING,
`auto_row_time` AS cast(CURRENT_TIMESTAMP as timestamp(3)),
WATERMARK FOR `auto_row_time` AS `auto_row_time` - INTERVAL '0' SECONDS
PRIMARY KEY(id) NOT ENFORCED
) WITH (
'connector'='jdbc',
'url'='jdbc:mysql://1.1.1.1:3306/data_storage?autoReconnect=true&useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&serverTimezone=Asia/Shanghai',
'username'='data_manage',
'password'='xxxxx',
'table-name'='source_dim_dept ',
'lookup.cache'='PARTIAL',
'lookup.partial-cache.expire-after-write'='30s',
'lookup.cache.ttl' = '30s',
'lookup.cache.max-rows'='5',
'lookup.partial-cache.max-rows'='5'
);
// 流表 -流表要有 水位线字段
CREATE TABLE source_kafka_stream_data(
`id` BIGINT,
`ts` BIGINT,
`price` FLOAT,
proc_time AS PROCTIME(),
`auto_row_time` AS cast(CURRENT_TIMESTAMP as timestamp(3)),
WATERMARK FOR `auto_row_time` AS `auto_row_time` - INTERVAL '0' SECONDS
) WITH (
'connector'='kafka',
'properties.group.id'='data_processing_producer',
'scan.startup.mode'='group-offsets',
'properties.auto.offset.reset'='latest',
'topic'='data-paimon-test',
'properties.bootstrap.servers'='1.1.1.1:9192',
'format'='json'
);
CREATE VIEW transform_tableJoin_XeH7VK1o2U AS
select `status`,`id`,`ts`,`price`, PROCTIME() as auto_row_time from (
select c.`dept` as `status`,c.`id` as `id`,O.`ts` as `ts`,O.`price` as `price`
from source_kafka_stream_data AS O
JOIN source_dim_dept FOR SYSTEM_TIME AS OF O.auto_row_timeAS c
on O.id=c.id ) ;
*注意坑在这里:上面的Lookup Join 区别也在这里,连接中流表的时间字段一定要用 水位线字段 类型的 AS OF O.auto_row_time文章来源:https://www.toymoban.com/news/detail-699996.html
// 以下是输出,无特殊配置
CREATE CATALOG paimon WITH (
'type' = 'paimon',
'warehouse' = 'hdfs://hadoop01:9000/painmon/data-processing/paimon_ods'
);
USE CATALOG paimon;
create database if not exists paimon.paimon_ods_db;
drop table if exists paimon_ods_db.paimon_test_stream_join;
CREATE TABLE if not exists paimon_ods_db.paimon_test_stream_join(
`uuid` STRING,
`status` STRING,
`id` BIGINT,
`ts` BIGINT,
`price` DOUBLE
) WITH (
'sink.parallelism'='8',
'bucket'='8',
'bucket-key'='uuid',
'write-mode'='append-only',
'sink.use-managed-memory-allocator'='true',
'sink.managed.writer-buffer-memory'='512MB',
'num-sorted-run.compaction-trigger'='20',
'write-buffer-size'='1024MB',
'write-buffer-spillable'='true'
);
INSERT INTO paimon_ods_db.paimon_test_stream_join select uuid(),`status`,`id`,`ts`,`price` from default_catalog.default_database.transform_tableJoin_XeH7VK1o2U;
到了这里,关于Flink动态更新维表的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!