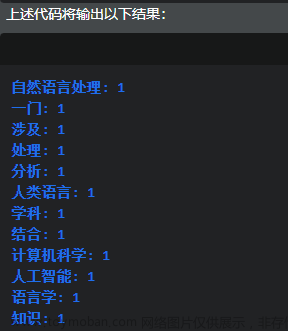
将关于地铁的留言文本进行自动分类。
不要着急,一步步来。
导入需要的库。
import numpy as np
import pandas as pd
import jieba # 分词
import re # 正则
from fnmatch import fnmatch # 通配符
from sklearn.preprocessing import LabelEncoder
from sklearn.feature_extraction.text import CountVectorizer # 文本向量化
from sklearn.feature_extraction.text import TfidfTransformer # 文本向量化
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
from sklearn import svm # 支持向量机模型定义函数,加载用来分词的自定义词典。
# 可根据实际需要,手动调整自定义词典路径和自定义词汇
def jieba_fenci():
# 在jieba中加载自定义的地铁线路名、地铁站点名词典
jieba.load_userdict("mydict_line.csv")
jieba.load_userdict("mydict_station.csv")
# 一些在市民留言中常见的高频的词,发现了就手动添加进去
myaddword_ls = ["公共自行车", "金溪园"]
for w in myaddword_ls:
jieba.add_word(w)定义函数,生成自己的停用词词典,得到一个文件。
我找的4个停用词词典下载地址:https://gitcode.net/mirrors/goto456/stopwords/-/tree/master
后面我会把自己整合好的停用词词典上传。
# 这段代码只用跑一次,以后可以直接用这个文件
# 自己给停用词文件起好名字(路径),作为投入函数的参数
def get_mystopwords_file(mystopwords_file_name):
stopwords_path_ls = ["baidu_stopwords.txt", "cn_stopwords.txt", "hit_stopwords.txt", "scu_stopwords.txt"]
stopwords_set = set() # 集合可以自动去重
for p in stopwords_path_ls:
with open(p, 'r', encoding = 'utf-8') as stopwords_file:
for stopword in stopwords_file:
if u'\u4e00'<= stopword[0] <= u'\u9fff': # 只放中文的停用词
stopwords_set.add(stopword.strip('\n'))
with open(mystopwords_file_name, 'w') as mystopwords_file:
for stopword in stopwords_set:
mystopwords_file.write(stopword + '\n')定义函数,读取停用词词典文件,得到一个停用词列表。
# 可以根据实际需要,手动添加或删除停用词
def get_mystopwords_list(mystopwords_file_name):
mystopwords_ls = []
with open(mystopwords_file_name, 'r') as mystopwords_file:
for stopword in mystopwords_file:
mystopwords_ls.append(stopword.strip('\n'))
# 对于一些高频出现的、但对于分类没什么特征帮助的词,可以手动加进停用词列表
zdy_stopword = ["建议", "信访", "杭州"]
for w in zdy_stopword:
mystopwords_ls.append(w)
# 对于一些停用词表里有的、但认为对后面分析有用的词,可以手动从停用词列表剔除
zdy_not_stopword = [] # 目前还没想好剔除什么词,所以列表是空的
for w in zdy_not_stopword:
mystopwords_ls.remove(w)
return mystopwords_ls定义函数,统一地铁线路名称格式。
# 投入参数是一个已经分好词的列表,返回一个处理好的列表
def unify_line_name(mylist):
num_dict = {1:'一', 2:'二', 3:'三', 4:'四', 5:'五', 6:'六', 7:'七', 8:'八', 9:'九', \
10:'十', 11:'十一', 12:'十二', 13:'十三', 14:'十四', 15:'十五', 16:'十六', 17:'十七', \
18:'十八', 19:'十九', 20:'二十', 21:'二十一', 22:'二十二', 23:'二十三'}
for i in range(len(mylist)):
if fnmatch(mylist[i], "*号线") or fnmatch(mylist[i], "*号地铁"):
for j in range(len(num_dict),0,-1):
if str(j) in mylist[i] or num_dict[j] in mylist[i]:
mylist[i] = "地铁" + str(j) + "号线"
break
if mylist[i] in ["机场快线", "机场轨道快线"]:
mylist[i] = "地铁19号线"
return mylist定义文本预处理的函数,作用:去除无用字符、去除停用词、统一地铁线路名。
# 投入的参数是一个原始字符串,返回一个处理好的字符串(分好的词之间空格连接)
# 要在使用这个函数之前弄好停用词列表,列表名称是mystopwords_ls
def mychuli(x):
# 仅保留汉字、英文字母、阿拉伯数字
mystr = ''.join(re.findall('[a-zA-Z0-9\u4e00-\u9fa5]',x))
# 分词,每个字符串变成一个列表
mylist = jieba.lcut(mystr, cut_all = False)
# 统一线路名称
mylist = unify_line_name(mylist)
# 去除停用词
for word in mylist:
if word in mystopwords_ls:
mylist.remove(word)
return ' '.join(mylist)定义模型实际应用的函数,输入文本,输出分类结果。
# 输入一条文本,经预处理后投进支持向量机模型进行预测
def mypre():
lebel_dict = dict(zip([0,1,2,3,4,5,6,7,8,9], le.inverse_transform([0,1,2,3,4,5,6,7,8,9])))
mytext = input("输入要预测的文本:")
mytext_yichuli = mychuli(mytext)
print("文本预处理结果:{}".format(mytext_yichuli))
X_new = []
X_new.append(mytext_yichuli)
X_new_vec = tf.fit_transform(cv_new.fit_transform(X_new)).toarray()
y_new_pre = SVM.predict(X_new_vec)
print("模型预测的分类编号为:{}".format(y_new_pre[0]))
print("对应的分类名称为:{}".format(lebel_dict[y_new_pre[0]]))读取文本,去重。
# 读取语料文件
df = pd.read_csv("xxx.csv")
print("去重前:")
print(df.info())
# 去除重复数据
df1 = df.drop_duplicates()
print("去重后:")
print(df1.info())
print(df1.head())
jieba_fenci() # 加载自定义的分词词典
get_mystopwords_file("mystopwords.txt") # 得到一个整合好的停用词文件,只用跑一次
mystopwords_ls = get_mystopwords_list("mystopwords.txt") # 得到停用词列表
# 新建一列yichuli_title,放已经处理好的文本数据
df1['yichuli_title'] = df1['title'].apply(mychuli)
# 给类别进行编号
le = LabelEncoder()
le.fit(df1['class1'])
df1['yichuli_label'] = le.transform(df1['class1'])
# 把处理好的结果写入一个新的csv文件,方便以后使用
# 用gb18030编码可实现外面打开这个文件看显示正常中文,而不是乱码
df1.to_csv("test0908_result.csv", columns = ['yichuli_title', 'yichuli_label', 'class1'], encoding = "gb18030")构建训练集、测试集。
# 读取已经处理好的csv文件
df1 = pd.read_csv("test0908_result.csv", encoding = "gb18030")
# 构建训练集、测试集
cv = CountVectorizer()
tf = TfidfTransformer()
X = df1['yichuli_title']
y = df1['yichuli_label']
X = tf.fit_transform(cv.fit_transform(X)).toarray()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
print(X_train.shape)
print(X_test.shape)训练模型。文章来源:https://www.toymoban.com/news/detail-700523.html
SVM = svm.LinearSVC() #支持向量机分类器LinearSVC
SVM.fit(X_train, y_train)
y_pre = SVM.predict(X_test)
print("支持向量机模型结果:")
print(classification_report(y_test, y_pre))
# 支持向量机的混淆矩阵
svm_confuse = pd.DataFrame(confusion_matrix(y_test, y_pre))
print(svm_confuse)预测新数据。文章来源地址https://www.toymoban.com/news/detail-700523.html
cv_new = CountVectorizer(vocabulary = cv.vocabulary_) # vocabulary参数保证向量维度与训练集一致
mypre()到了这里,关于Python 自然语言处理 文本分类 地铁方面留言文本的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!