以下是能用KMP求解的算法题,KMP是用于字符串匹配的经典算法【至今没学懂………啊啊啊】
28. 找出字符串中第一个匹配项的下标
题目链接:28. 找出字符串中第一个匹配项的下标
题目内容:
题意还是很好理解的,要在字符串haystack中查找一个完整的needle,即字符串匹配。
暴力求解
暴力求解就是用两层循环:haystack从第i个字符开始,needle从第一个字符开始j = 0,之后依次判断needle[j]和haystack[j+i]是否相等。如果不相等,说明haystack中从第i位开始的子串和needle是不匹配的。之后j要回溯到j = 0,i向后移动一位。代码实现(C++):
class Solution {
public:
int strStr(string haystack, string needle) {
//haystack下标最大值
int n = haystack.size() - needle.size();
//外层是haystack从下标i开始和needle逐字符比较
for(int i = 0 ; i <= n; i++){
int j = 0;
//needle从j=0开始
while( j < needle.size()){
//如果有相等就退出循环,开启下一轮
if(haystack[j+i] != needle[j])
break;
j++;
}
//如果是遍历完needle都与从i开始的子串相同,就找到了
if(j == needle.size())
return i;
}
return -1;
}
};
KMP
暴力求解中,如果当前的needle[j]和haystack[j+i]不匹配,needle中j会回退到0,haystack中i+j回退到i+1,这里是可以优化的,KMP就是为了减少这样的回溯。
KMP是用于求解字符串匹配的算法,在当前needle[j]和haystack[j+i]不匹配时,能够快速找到j应该移动到的位置,而不是直接回溯到开头。比如下面图中s[i]和p[j]不匹配后,由于p[j]前面的子串的前缀ab和后缀ab相同,因此j不需要回溯到0,是移动到abc中c的位置,继续和s[i]比较。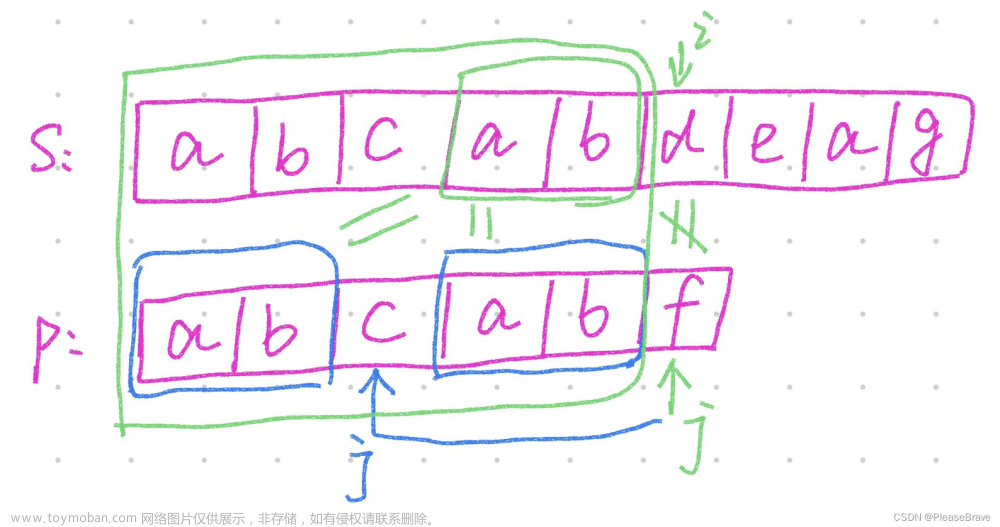
KMP中一个重点是最长相同前后缀长度。什么是前缀:一个字符串从第一个字符开始的,不包括最后一个字符的子串;什么是后缀:一个字符串中从最后一个字符开始的,不包括第一个字符的子串。
最长相同前后缀长度,就是一个字符串中相同的前后缀里面,最长的一组的长度。比如下图里对于ababa这个字符串,相同前后缀有两组,但是我们需要最长那组的长度。因为字符串匹配过程中,S[i]和P[j]不匹配时,j是要根据P[j]前面子串的前后缀长度来回退的,选择最长前后缀能够保证不遗漏答案。
KMP算法需要求模式串P的next数组,实际上这个next数组记录的就是P所有从第一个字符开始的子串的最长相同前后缀的长度:next[i]表示下标0到下标i这段子串的,最长相同前后缀的长度。假设有next[i-1]=m,那么next[i] <= next[i-1]+1,其中取等需要P[next[i-1]] == P[i]。【因为next[i-1]里面存的是长度,当作下标的时候就是最长相同前后缀里面那个前缀后面一个字符;而P[i]就是P[i-1]最长相同前后缀的后缀的后后面一个字符】。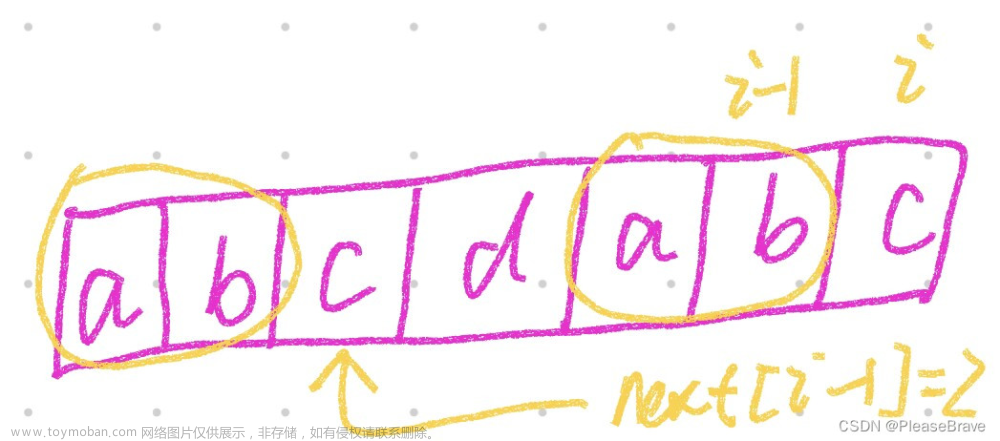
如果P[next[i-1]] != P[i],那么就要判断P[next[next[i-1]-1]]和P[i]的关系,直到下标回溯到0或者找到了和P[i]匹配的位置。
代码如下(C++):
ector<int> Kmp_Next(string s){
int n = s.size();
vector<int> next(n, 0);
//next数组中存的是对应下标处子串【包括下标位置】的最长前后缀的长度
next[0] = 0;
for(int i = 1; i < n; i++){
int j = next[i-1];
while(j>0 && s[j] != s[i]) //不匹配就循环回退
j = next[j-1];
if(s[i] == s[j]) //如果匹配,长度在j的基础上+1
j++;
next[i] = j;
}
return next;
}
KMP的匹配过程:首先求得了模式串P的next数组,即每个P[0]~P[i]这一段这串中最长的相同前后缀的长度;然后P中的字符从P[j=0]开始,S中的字符也从S[pos=0]开始,判断S[pos]和P[j]是否匹配,如果匹配就j++,pos++向后移动;如果不匹配,j就根据next[j-1]回退,并判断回退后新的下标j对应的P[j]和S[pos]是否匹配,如果不匹配继续回退,直到匹配或者j=0。实现过程如下:
- 要先找到P中哪个字符和当前的S[pos]匹配。因为如果P[j] != S[pos],j需要根据next数组循环回退j = next[j-1],那么就先找到能够匹配的j,才停止;
while(j>0 && haystack[pos] != needle[j])
j = next[j-1];
- 上面循环退出有两种情况,P[j] == S[pos]或者j == 0;如果是前者,自然pos++,j++;如果是后者,就只有pos++;
if(haystack[pos] == needle[j]){
pos++;
j++;
}
else
pos++;
- 最后停止要么是j遍历到了最后,要么是pos遍历到了最后。只有j遍历到最后才算完全匹配;
完整代码如下(C++):
class Solution {
public:
//先求needle的next数组
vector<int> Kmp_Next(string s){
int n = s.size();
vector<int> next(n, 0);
//next数组中存的是对应下标处子串【包括下标位置】的最长前后缀的长度
next[0] = 0;
for(int i = 1; i < n; i++){
int j = next[i-1];
while(j>0 && s[j] != s[i])
j = next[j-1];
if(s[i] == s[j])
j++;
next[i] = j;
}
return next;
}
int strStr(string haystack, string needle) {
vector<int> next = Kmp_Next(needle);
int pos = 0, j = 0;
//kmp匹配过程
while(j < needle.size() && pos < haystack.size()){
while(j>0 && haystack[pos] != needle[j])
j = next[j-1];
if(haystack[pos] == needle[j]){
pos++;
j++;
}
else
pos++;
}
//needle没有遍历完,pos已经遍历完haystack了,没有匹配的地方
if(j < needle.size())
return -1;
//needle遍历完,有匹配的地方
else
return pos - needle.size();
}
};
459. 重复的子字符串
题目链接:459. 重复的子字符串
题目内容:
暴力求解
题目要求我们判断字符串S是不是由其某个子串重复构成的。假设子串m能够重复构成S,那么S可以表示m/mm/m/……这样的形式,即由n个m组成【n≥2】。分析这样的子串有两个特点:
- 从第一个字符开始;
- 长度≤S.size()/2;
- S.size()一定能够被m.size()整除;
根据子串的这两个特点,我们可以去判断所有这样的子串,子串长度从1开始,最多有S.size()/2这么多个。针对每个子串,先判断其长度能否整除S的长度;再判断其能否重复构成S——将S分成和子串m一样长度的k个子串,所有的子串和m对比是否一样,如果有一个不一样就直接break。
代码如下(C++):
class Solution {
public:
bool repeatedSubstringPattern(string s) {
int size = s.size();
//end是子串m的长度
for(int end = 1; end <= size/2; end++ ){
//s长度能够被end整除才继续下面的判断
if(size % end == 0){
int i;
//剩下的子串和m对比
for(i = end ; i < size ; i += end ){
if(s.substr(0,end) != s.substr(i, end))
break;
}
if(i == size )
return true;
}
}
return false;
}
};
暴力求解的时间复杂度是O(n^2)。
在S+S中找S
假设S由n个子串m组成【n≥2】,那么S+S中有2n个m,将S+S去头去尾【删除第一个和最后一个元素就能实现去掉一个m和最后一个m】后还有2n-2个m,由于n≥2,2n-2≥n。那么如果S+S去头去尾后还能有至少一个完整的S,就能证明其是由m循环组成的。代码实现(C++)【就一句话】:
class Solution {
public:
bool repeatedSubstringPattern(string s) {
return (s+s).find(s,1) != s.size() ? true : false;
}
};
那么如果不是由子串m循环组成的字符串,S+S去头去尾以后一定找不到一个完整的S吗?【emm需要再研究一下】文章来源:https://www.toymoban.com/news/detail-700723.html
686. 重复叠加字符串匹配
题目链接:686. 重复叠加字符串匹配
题目内容:
理解题意,可以发现题目还是要求我们做字符串匹配。只是查询串不是简单的a,而是a的叠加,并且这个叠加次数是不确定的。
首先我们要明确方法,字符串匹配,首选KMP算法。a的叠加在匹配中可以用a[i % a.size()]来解决。 如果a的m次叠加后,能够查询到b,之后的m+1,m+2次叠加b也是其子串, 因此m就是最小的叠加次数。并且如果能够找到这样的m使得b成为a的m次叠加后的子串的话,kmp查询就能成功,b会被遍历完。但是如果不能的话,由于a的叠加用a[i % a.size()],a的下标永远不会越界,b也一直不会遍历结束,那么kmp中的循环该如何结束?
假设当前s和b开始匹配的位置是在第一个a之后,因为查询串s是a重复循环叠加的,那么说明在这之前和第一个a也是同样能够完成当前的部分匹配的。但是会从第一个a的匹配变到第二个,就说明在当前匹配的字符后有不能匹配的,那么就会继续变到第三个a,这样下去是永远也不能完全匹配的,即b不是a的循环叠加的子串。因此得出结论:s和b开始匹配的地方不是在第一个a中话,可以肯定b不是s的子串,只有b从第一个a中的字符开始匹配才有可能匹配成功。即a中下标i,b中下标 j,如果 **i - j >= a.size()**就说明匹配不上。
代码如下(C++):文章来源地址https://www.toymoban.com/news/detail-700723.html
class Solution {
public:
//KMP算法
int strStr(string haystack, string needle) {
int len_h = haystack.size();
int len_n = needle.size();
//求模式串的vector数组
vector<int> next(len_n, 0);
//next数组中存的是对应下标处子串【包括下标位置】的最长前后缀的长度
for(int i = 1; i < len_n; i++){
int j = next[i-1];
while(j>0 && needle[j] != needle[i])
j = next[j-1];
if(needle[i] == needle[j])
j++;
next[i] = j;
}
//开始匹配
int pos = 0, j = 0;
//结束条件
while(pos - j < len_h){
while(j>0 && haystack[pos % len_h] != needle[j])
j = next[j-1];
if(haystack[pos % len_h] == needle[j]){
pos++;
j++;
}
else
pos++;
//因为pos可以无限增加,当遍历完b的时候说明已经找到了
if(j == len_n)
return pos;
}
return -1;
}
int repeatedStringMatch(string a, string b) {
int idx = strStr(a, b);
if(idx == -1)
return -1;
//求m
return (idx-1) / a.size() + 1;
}
};
到了这里,关于【leetcode 力扣刷题】字符串匹配之经典的KMP!!!的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!