论文:End-to-End Semi-Supervised Object Detection with Soft Teacher
代码:https://github.com/microsoft/SoftTeacher
出处:ICCV2021 | 华中科大 微软
一、背景
大量带标注信息的数据是深度计算机视觉高速发展的基础,但数据标注是耗时且昂贵的,所以催生了一些不需要标注信息或只需要少量标注数据的自监督和半监督学习。
对于半监督目标检测,本文只关注伪标签的方法,这也是目前效果最好的方法
[27,36] 中的方法进行了多阶段的训练:
- 第一阶段使用标记数据训练初始检测器
- 然后对未标记的数据进行伪标签处理,并基于伪标签再训练
虽然多阶段的方法效果也较好,但最终的性能很大程度上受到伪标签的质量的限制
[27] A simple semi-supervised learning framework for object detection
[36] Rethinking pre-training and self-training
故本文提出了一种端到端的基于伪标签的半监督目标检测网络,同时进行两件事情:
- 对无标签的图像生成伪标签
- 使用这些伪标签和一些带标签的数据一起来训练检测器
也就是对标记的和未标记的数据先预设一个随机采样比例,对这些图像同时使用两种模型:
- 一个模型进行检测器的训练,即学生模型
- 一个模型负责对未标记的数据进行标注,即教师模型(通过对学生模型进行指数移动平均来获得)
端到端训练的好处:
- 可以让伪标签和检测训练过程互相加强,随着训练越来越好
- 能够让教师模型更好的指导学生模型的训练,而不像上面那两种方法只生成一些伪标签
为什么本文中是 soft teacher:
- 本文中的教师模型是用来直接评估学生模型产生的 proposal,而不是直接提供伪边界框
- 直接评估 proposal 能够更好的监督学生模型训练
- 本文方法首先根据分类得分将 proposal 分为前景和背景,但这样也会导致很多正样本被分为负样本,所以,使用了一个 [可靠性度量] 来衡量每个背景 proposal 的损失,这里可以使用教师模型的检测得分来作为可靠性度量,这比前面直接进行正负样本的划分更好一些,故称为 soft teacher


二、方法
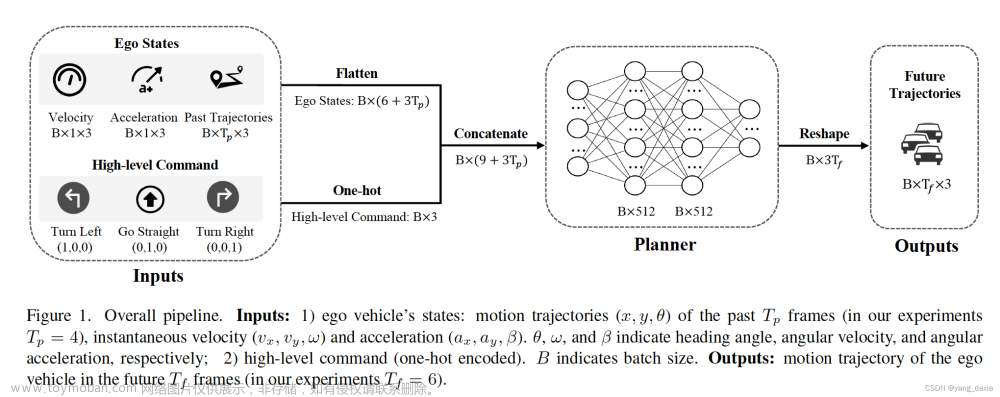
图 2 展示了整个端到端训练的网络结构
- 学生网络:通过学习带标签的图像和带伪标签的图像来训练
- 教师网络:是学生网络经过指数移动平均得到的
什么是指数移动平均(exponential moving average,EMA):
- 以指数式递减加权的移动平均
- 各数值的加权影响力随时间而指数式递减,越近期的数据加权影响力越重,但较旧的数据也给予一定的加权值
- v t = β v t − 1 + ( 1 − β ) θ t v_t = \beta v_{t-1} + (1-\beta) \theta_t vt=βvt−1+(1−β)θt, β \beta β 是可调节的参数,处于 0~1 之间
这里介绍一下自监督学习中的学生网络和教师网络:
- 教师网络和学生网络的模型结构是完全相同的,不分大小
- student model:当前模型,使用梯度下降法更新,损失函数包含有监督损失(训练有标签的数据)和无监督损失(使用教师网络生成的伪标签来训练)
- teacher model:不使用梯度下降法更新参数,而是对 student model 使用指数平均移动来更新,也就是会参考当前模型和之前模型的权重,得到一个新的模型: θ t ′ = α θ t − 1 ′ + ( 1 − α ) θ t \theta'_t = \alpha\ \theta'_{t-1} + (1-\alpha) \theta_t θt′=α θt−1′+(1−α)θt

2.1 End-to-End Pseudo-Labeling Framework
本文方法是基于 teacher-student 的方法,在每个训练 iter,会根据采样比例来随机采样带标签的数据和带伪标签的数据来组成一个 batch。
Teacher model:对无标签的数据生成伪标签
Student model:在带标签和带伪标签的数据上训练
两个模型的训练 loss 如下, L s L_s Ls 和 L u L_u Lu 分别是带标签的数据和不带标签的数据的 loss, α \alpha α 控制者无监督的 loss。

L s L_s Ls 和 L u L_u Lu 都会用 Batch size 进行归一化:

- 训练初期,teacher model 和 student model 都是随机初始化的
- 随着训练的进行,教师模型通过学生模型不断的进行更新,且更新机制是基于指数移动平均策略
教师模型怎么生成伪标签:
- 目标检测的伪标签需要包含类别和位置
- 教师模型首先检测到很多目标框,然后使用 NMS 进行过滤,并使用一个分类得分来过滤,保留高于阈值的框
- 为了提高生成的伪边界框的质量,作者还对学生模型了强数据增强,对教师模型使用了弱数据增强
注意:本文使用 Faster RCNN 作为基准检测网络
2.2 Soft teacher
学生网络的检测效果很大程度上依赖于教师网络生成的伪标签,而且使用高阈值过滤学生网络生成的 proposal 比低阈值过滤的效果更好。
如表 9 所示,最好的效果是阈值=0.9
虽然高阈值能保留更精确的伪边界框,但召回率非常低为 33%,如图 3a 所示
所以如果使用学生网络生成的 proposal 和教师网络产生的伪边界框的 IoU 来进行正负样本的分配的话,一些前景就会被误分为背景,拉低训练模型的效果
所以作者使用 soft teacher 的方法,来利用更多的教师模型的信息
- 首先,评估学生模型生成的每个 proposal 是真实背景的可靠性,作为背景分类 loss 的权重
- { b i f g } \{b_i^{fg}\} {bifg} 是将 proposal 分配为正样本
- { b i b g } \{b_i^{bg}\} {bibg} 是将 proposal 分配为负样本
未标记数据的带可靠性权重的分类 loss 如下, g c l s g_{cls} gcls 是教师模型生成的一系列伪边界框,用于分类:



2.3 Box Jittering
如图 3b,一个预测框的分类置信度和其定位准确性并没有很强的联系,也就是说只根据教师模型预测结果的分类置信度来保留伪标签是不太合适的。
本文作者通过度量回归结果的一致性来判断一个边界框的定位是否可靠:
-
给定一个教师网络生成的伪边界框 b i b_i bi,在其周围采样一个抖动的 box,并将抖动的盒子输入教师模型,得到精细化的边界框 b ^ i \widehat b_i b i:

-
重复进行上面的操作,就能够收集到一系列的经过精细化调整的框,作者定义定位可靠性就是这些框的方差:


-
如果方差越小,说明定位可靠性越高
-
为了减少计算量,作者只计算了分类得分大于 0.5 的框
图 3c 展示了定位准确性和框回归方差的关系,方差比分类得分更能衡量定位的准确性
这就能指导网络选择回归方差小的伪边界框作为无标签数据的伪标签。
训练伪标签的回归 loss 如下:

整体 loss 如下:

三、实验
使用 MS COCO,包括两个训练集:
- train2017,包含 118k 标注数据
- unlabeled2017,包含 123k 未标注数据
Partially Labeled Data:
- 随机选择 train2017 中的 1%,2%,5%,10% 作为标注数据,其他的作为未标注数据
- 在每个采样率下,对比了 5 种不同倍的均值和方法
Fully Labeled Data:
- 使用 train2017 作为带标签的训练数据,unlabeled2017 作为无标签的训练数据







 文章来源:https://www.toymoban.com/news/detail-700919.html
文章来源:https://www.toymoban.com/news/detail-700919.html
 文章来源地址https://www.toymoban.com/news/detail-700919.html
文章来源地址https://www.toymoban.com/news/detail-700919.html
到了这里,关于【半监督学习】2、Soft Teacher | 端到端半监督目标检测器的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!