一:排序引入
我们通常从哪几个方面来分析一个排序算法?
1.时间效率:决定了算法运行多久,O(1)
2.空间复杂度:
3.比较次数&交换次数:排序肯定会牵涉到两个操作,一个比较是肯定的。交换。
4.稳定性:这是什么? 1 9 3 5 3
第一种:1 3 3 5 9
第二种:1 3 3 5 9 哪一种是稳定的?相同的两个数排完序后,相对位置不变。
稳定排序有什么意义?应用在哪里呢?
1.电商里面订单排序:首先会按金额从小到大排,金额相同的按下单时间。我从订单中心过来的时候已经按照时间排好序了。我选择排序算法:如果我选择不稳定的排序算法 那我还要比较两次的,如果我选择稳定的排序算法 那我就只要比较一个字段。
二 核心思想:
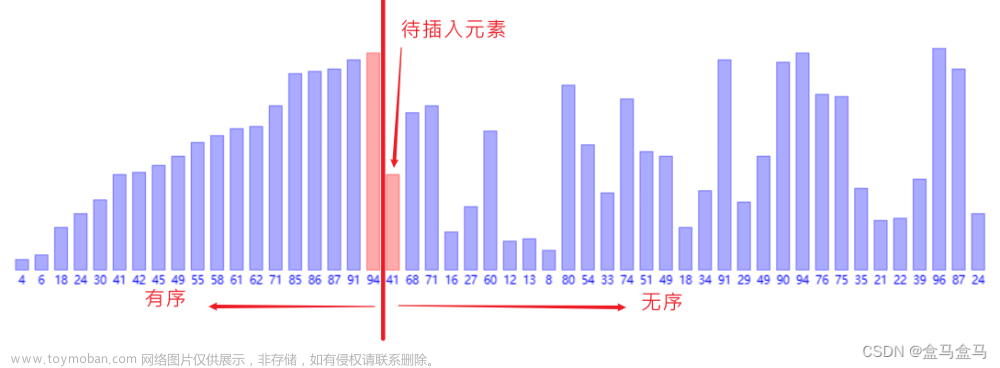
假设有个这样的问题:打扑克。分成两部分:一部分是你手里的牌(已经排好序),一部分是要拿的牌(无序)。
把一个无序的数列一个个插入到有序数列中。 一个有序的数组,我们往里面添加一个新的数据后,如何继续保持数据有序呢?我们只要遍历数组,找到数据应该插入的位置将其插入即可。
三: 具体步骤
1.将数组分成已排序段和未排序段。初始化时已排序端只有一个元素
2.到未排序段取元素插入到已排序段,并保证插入后仍然有序
3.重复执行上述操作,直到未排序段元素全部加完。
四:举例:
看以下这个例子:对7 8 9 0 4 3进行插入排序
7 8 9 0 4 3
7 8 9 0 4 3
7 8 9 0 4 3
0 7 8 9 4 3
0 4 7 8 9 3
0 3 4 7 8 9
从以上操作中我们看到插入排序会经历一个元素的比较以及元素的移动。当我们从待排序列中取一个数插入到已排序区间时,需要拿它与已排序区间的数依次进行比较,直到找到合适的位置,然后还要将插入点之后的元素进行往后移动。
五:插入排序代码实现、
package sort;
/**
* 插入排序
*/
public class InsertionSort {
/**
*
1.将数组分成已排序段和未排序段。初始化时已排序端只有一个元素
2.到未排序段取元素插入到已排序段,并保证插入后仍然有序
3.重复执行上述操作,直到未排序段元素全部加完。
*
* @param args
*/
public static void main(String[] args) {
int a[] = { 9, 8, 7, 0, 1, 3, 2 };
int n = a.length;
//这里面会有几层循环 2
//时间复杂度:n^2
//最好的情况:什么情况下:O(n); O(1)
//for(){ //分段
for(int i = 1 ; i < n;i++){ //为什么i要从1开始? 第一个不用排序,我们就把数组从i分开,0~I的认为已经排好序
int data = a[i];
int j = i -1;
for(;j>=0;j--){//从尾到头 1+2+3+4+5+...+n=>
if(a[j] > data){
a[j+1] = a[j]; // 数据往后移动
}else{ //因为前面已经是排好序的 那么找到一个比他小的就不用找了,因为前面的肯定更小
break; //O(1) 如果这个break执行的越多 那么我是不是效率就越高?
}
}
a[j+1] = data;
System.out.print("第" +i +"次的排序结果为:");
for(j = 0 ; j < n;j++){
System.out.print(a[j]+" ");
}
System.out.println();
}
}
}
六:优化 (希尔排序==>插入排序改进版)
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
先取一个小于n的整数d1作为第一个增量,把文件的全部记录分组。所有距离为d1的倍数的记录放在同一个组中。先在各组内进行直接插入排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量 =1( < …<d2<d1),即所有记录放在同一组中进行直接插入排序为止。
来看一个具体的过程: 按照一个增量分段:add=n/2 n=10 =>5,2,1 7 8 9 0 4 3 1 2 5 10 我们取的这个增量分别就是5 2 1 7 8 9 0 4 3 1 2 5 10:分出来的数组元素都是一样的 完成一次排序: 3 1 2 0 4 7 8 9 5 3 2 4 8 5:取增量为2的分为一组了 最后一次我们就取增量为1的分组: 就是一个完整的序列,但是时间复杂度还是O(n^2)
七:归并排序 (核心思想:递归+分治)
主要分析时间复杂度:nlogn

文章来源:https://www.toymoban.com/news/detail-701322.html
package sort;
import java.util.Arrays;
public class MegrSort {
public static void main(String[] args) {
int data[] = { 9, 5, 6, 8, 0, 3, 7, 1 };
//拆分
megerSort(data, 0, data.length - 1);
System.out.println(Arrays.toString(data));
//JDK里面的排序源码
}
public static void megerSort(int data[], int left, int right) { // 数组的两端
if (left < right) { // 相等了就表示只有一个数了 不用再拆了
int mid = (left + right) / 2;
//拆分从最左边到中间
megerSort(data, left, mid);
//拆分右边从中间+1到最右边
megerSort(data, mid + 1, right);
// 分完了 接下来就要进行合并,也就是我们递归里面归的过程
meger(data, left, mid, right);
}
}
public static void meger(int data[], int left, int mid, int right) {
int temp[] = new int[data.length]; //借助一个临时数组用来保存合并的数据
int point1 = left; //表示的是左边的第一个数的位置
int point2 = mid + 1; //表示的是右边的第一个数的位置
int loc = left; //表示的是我们当前已经到了哪个位置了
while(point1 <= mid && point2 <= right){
if(data[point1] < data[point2]){
temp[loc] = data[point1];
point1 ++ ;
loc ++ ;
}else{
temp[loc] = data[point2];
point2 ++;
loc ++ ;
}
}
//接下来要干嘛呢?合并排序完成 了吗?
while(point1 <= mid){
temp[loc ++] = data[point1 ++];
}
while(point2 <= right){
temp[loc ++] = data[point2 ++];
}
for(int i = left ; i <= right ; i++){
data[i] = temp[i];
}
}
}
这段代码实现了归并排序算法。归并排序是一种分治算法,它将一个数组分成两个子数组,分别对其进行递归排序,然后将两个有序的子数组合并成一个有序的数组。 代码中的
megerSort方法是归并排序的主要方法,它接受一个数组和两个索引值作为参数,表示需要排序的数组和需要排序的范围。如果左索引小于右索引,则将数组分为两半,分别对左半部分和右半部分进行递归调用megerSort方法。递归调用结束后,再调用meger方法将两个有序的子数组合并成一个有序的数组。meger方法创建了一个临时数组temp,用来保存合并的结果。变量point1和point2分别表示左半部分和右半部分的起始位置。变量loc表示当前合并的位置。在循环中,比较左右两个子数组的元素大小,将较小的放入临时数组中,并将对应的指针向后移动。循环结束后,将剩余的元素依次放入临时数组中。最后,将临时数组的元素复制回原数组的对应位置。 整个归并排序的过程是递归的,每一次递归都会将数组分为两半,直到只有一个元素为止。然后通过合并两个有序的子数组来实现整个数组的排序。最后,通过递归调用megerSort方法将整个数组排序完成。文章来源地址https://www.toymoban.com/news/detail-701322.html
到了这里,关于数据结构与算法-插入&希尔&归并的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!