最近工作中经常用到正则表达式处理数据,慢慢发现了正则表达式的强大功能,尤其在数据处理工作中,记录下来分享给大家。
一、 正则表达式语法介绍
正则表达式(或 RE)指定了一组与之匹配的字符串;模块内的函数可以检查某个字符串是否与给定的正则表达式匹配(或者正则表达式是否匹配到字符串,这两种说法含义相同)。
正则表达式可以拼接;如果 A 和 B 都是正则表达式,则 AB 也是正则表达式。通常,如果字符串 p 匹配 A,并且另一个字符串 q 匹配 B,那么 pq 可以匹配 AB。
除非 A 或者 B 包含低优先级操作,A 和 B 存在边界条件;或者命名组引用。所以,复杂表达式可以很容易的从这里描述的简单源语表达式构建。
正则表达式可以包含普通或者特殊字符。绝大部分普通字符,比如 'A', 'a', 或者 '0',都是最简单的正则表达式。它们就匹配自身。
你可以拼接普通字符,所以 last 匹配字符串 'last'。通常正则表达式都会用到特殊字符匹配规则。
正则表达式,查找匹配字符串常用于以下几种场景:
1,去除匹配数据。
2,提取匹配数据。
3,替换匹配数据。
4,检测匹配数据。
二、 正则表达式常用方法
Python 基于正则表达式提供了不同的原始操作:
--这3个方法更多用于检测判断
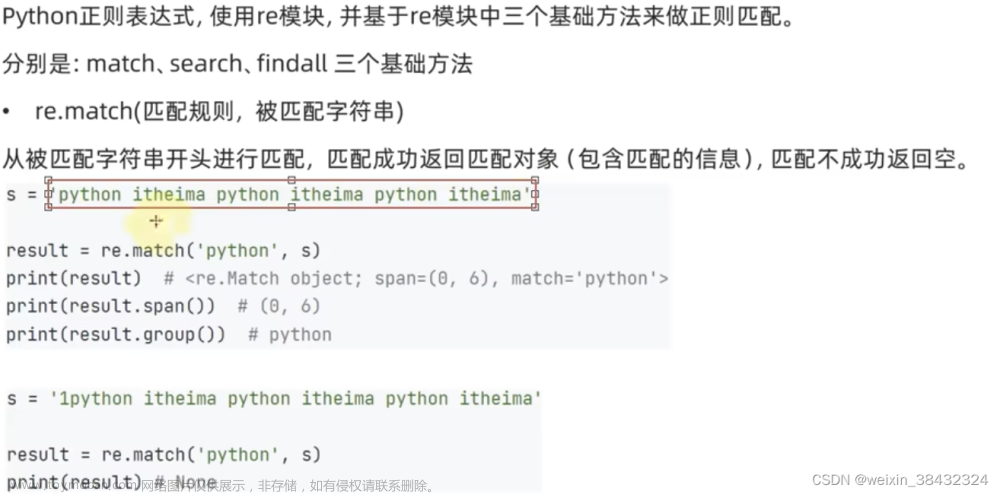
re.match(pattern, string) 只在字符串的开头位置检测匹配。
re.search(pattern, string) 在字符串中的任何位置检测匹配。
re.fullmatch(pattern, string) 检测整个字符串是否匹配。
--这2个方法更多用于查找匹配数据,提取或替换获取目标结果数据。
re.findall(pattern, string) 在字符串中的任何位置检测匹配的字符并返回匹配的字符列表。
re.sub(pattern, repl, string) 在字符串中的任何位置匹配替换的字符并返回结果字符串。
print('============================')
rst1 = re.match("c", "abcdef") # No match
print(rst1)
rst2 = re.search("c", "abcdef") # Match
print(rst2)
# <re.Match object; span=(2, 3), match='c'>
rst3 = re.fullmatch("p.*n", "python") # Match
print(rst3)
# <re.Match object; span=(0, 6), match='python'>
rst4 = re.fullmatch("r.*n", "python") # No match
print(rst4)
rst5 = re.findall(r"\d+", "12pyt34hon56")
print(rst5)
# ['12', '34', '56']
rst6 = re.sub(r"\d+", "", "12pyt34hon56")
print(rst6)
# python
print('============================')三、 正则表达式常用特殊字符
.
(点) 在默认模式,匹配除了换行的任意字符。如果指定了标签 DOTALL ,它将匹配包括换行符的任意字符。
print('============================')
# 全部替换成统一数据
str_list1 = ['万安县', '万方县', '万在县', '万义县']
for i in range(len(str_list1)):
# 匹配替换的字符
str_list1[i] = re.sub("万.县", "万安县", str_list1[i])
print(str_list1)
# ['万安县', '万安县', '万安县', '万安县']
print('============================')^
(插入符号) 匹配字符串的开头, 并且在 MULTILINE 模式也匹配换行后的首个符号。
$
匹配字符串尾或者在字符串尾的换行符的前一个字符,在 MULTILINE 模式下也会匹配换行符之前的文本。
foo 匹配 'foo' 和 'foobar',但正则表达式 foo$ 只匹配 'foo'。
更有趣的是,在 'foo1\nfoo2\n' 中搜索 foo.$,通常匹配 'foo2',
但在 MULTILINE 模式下可以匹配到 'foo1';在 'foo\n' 中搜索 $ 会找到两个(空的)匹配:
一个在换行符之前,一个在字符串的末尾。
*
对它前面的正则式匹配0到任意次重复, 尽量多的匹配字符串。
ab* 会匹配 'a','ab',或者 'a' 后面跟随任意个 'b'。
ab* 会匹配 : 'a','ab','abb','abbb' 等等.
+
对它前面的正则式匹配1到任意次重复, 尽量多的匹配字符串。
ab+ 会匹配 'a' 后面跟随1个以上到任意个 'b',它不会匹配 'a'。
ab+ 会匹配 : 'ab','abb','abbb' 等等.
?
对它前面的正则式匹配0到1次重复。
ab? 会匹配 'a' 或者 'ab'。
\
转义特殊字符(允许你匹配 '*', '?', 或者此类其他),或者表示一个特殊序列.
print('============================')
# 保留数字 和 ¥数字 的金额格式数据,其他数据排除
str_list2 = ['5005', '200.85', '¥12450', '¥100.50', '张三', '2023.08.09']
get_list2 = []
for ss in str_list2:
# 查找匹配的字符,下面3个方法等价匹配
if re.search(r'(^¥?\d+\.?\d*$)', ss):
# if re.search(r'^¥?\d+\.?\d*$', ss):
# if re.fullmatch(r'¥?\d+\.?\d*', ss):
print('保留')
get_list2.append(ss)
else:
print('去除')
continue
print(get_list2)
# ['5005', '200.85', '¥12450', '¥100.50']
print('============================'){m}
对其之前的正则式指定匹配 m 个重复;少于 m 的话就会导致匹配失败。
比如, a{6} 将匹配6个 'a' , 但是不能是5个。
{m,n}
对正则式进行 m 到 n 次匹配,在 m 和 n 之间取尽量多。
比如,a{3,5} 将匹配 3 到 5个 'a'。忽略 m 意为指定下界为0,忽略 n 指定上界为无限次。
比如,a{4,}b 将匹配 'aaaab' 或者1000个 'a' 尾随一个 'b',但不能匹配 'aaab'。
逗号不能省略,否则无法辨别修饰符应该忽略哪个边界。
print('============================')
# 保留8位带符号格式的日期数据,其他数据排除
str_list3 = ['2023年08月09日', '2023-08-09', '2023/08/09', '20230809', '2023/8/9']
get_list3 = []
for ss in str_list3:
# 查找匹配的字符,下面3个方法等价匹配
if re.search(r'[\d年月日]{11}', ss) or re.search(r'[\d\-\/]{9,10}', ss):
print('保留')
get_list3.append(ss)
else:
print('去除')
continue
print(get_list3)
# ['2023年08月09日', '2023-08-09', '2023/08/09']
print('============================')[]
用于表示一个字符集合。在一个集合中:
1, 字符可以单独列出,比如 [amk] 匹配 'a', 'm', 或者 'k'。
2, 可以表示字符范围,通过用 '-' 将两个字符连起来。
比如 [a-z] 将匹配任何小写ASCII字符,
[0-9] 将匹配从 0到9 的1位数字,
[0-5][0-9] 将匹配从 00 到 59 的两位数字,
[0-9A-Fa-f] 将匹配任何十六进制数位。
如果-进行了转义(比如 [a\-z])或者它的位置在首位或者末尾(如 [-a] 或 [a-]),它就只表示普通字符 '-'。
3, 特殊字符在集合中会失去其特殊意义。比如 [(+*)] 只会匹配这几个字面字符之一 '(', '+', '*', or ')'。
4, 字符类如 \w 或者 \S (如下定义) 在集合内可以接受,它们可以匹配的字符由 ASCII 或者 LOCALE 模式决定。
5, 不在集合范围内的字符可以通过'取反'来进行匹配。
如果集合首字符是 '^' ,所有 不 在集合内的字符将会被匹配,
比如 [^5] 将匹配所有字符,除了 '5',
[^^] 将匹配所有字符,除了 '^'. ^ 如果不在集合首位,就没有特殊含义。
6, 要在集合内匹配一个 ']' 字面值,可以在它前面加上反斜杠,或是将它放到集合的开头。
例如,[()[\]{}] 和 []()[{}] 都可以匹配右方括号,以及左方括号,花括号和圆括号。
|
A|B, A 和 B 可以是任意正则表达式,创建一个正则表达式,匹配 A 或者 B. 任意个正则表达式可以用 '|' 连接。
它也可以在组合(见下列)内使用。扫描目标字符串时, '|' 分隔开的正则样式从左到右进行匹配。
当一个样式完全匹配时,这个分支就被接受。意思就是,一旦 A 匹配成功, B 就不再进行匹配,即便它能产生一个更好的匹配。
或者说,'|' 操作符绝不贪婪。 如果要匹配 '|' 字符,使用 \|, 或者把它包含在字符集里,比如 [|].文章来源:https://www.toymoban.com/news/detail-701634.html
(...)
(组合),匹配括号内的任意正则表达式,并标识出组合的开始和结尾。
匹配完成后,组合的内容可以被获取,并可以在之后用 \number 转义序列进行再次匹配,之后进行详细说明。
要匹配字符 '(' 或者 ')', 用 \( 或 \), 或者把它们包含在字符集合里: [(], [)].文章来源地址https://www.toymoban.com/news/detail-701634.html
print('============================')
# 保留8位带符号格式的日期数据,其他数据排除
str_list3 = ['2023年08月09日', '2023-08-09', '2023/08/09', '20230809', '2023/8/9']
get_list3 = []
for ss in str_list3:
# 查找匹配的字符,下面3个方法等价匹配
if re.search(r'[\d年月日]{11}|[0-9\-\/]{9,10}', ss):
print('保留')
get_list3.append(ss)
else:
print('去除')
continue
print(get_list3)
# ['2023年08月09日', '2023-08-09', '2023/08/09']
print(re.search(r'(¥\d+)', '¥12450'))
# <re.Match object; span=(0, 6), match='¥12450'>
print('============================')到了这里,关于python正则表达式笔记1的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!