💕💕作者:计算机源码社
💕💕个人简介:本人七年开发经验,擅长Java、Python、PHP、.NET、微信小程序、爬虫、大数据等,大家有这一块的问题可以一起交流!
💕💕学习资料、程序开发、技术解答、文档报告
💕💕JavaWeb项目
💕💕微信小程序项目
💕💕Python项目
💕💕Android项目
开发背景
随着数字媒体和在线娱乐行业的蓬勃发展,电影产业也日益繁荣。观众们对电影数据的需求不断增长,不仅仅是观影体验,还包括对影片评价、票房表现、演员阵容等方面的关注。因此,为了满足这一增长的需求,以及电影制片方、影院和媒体等行业参与者的需求,决定开发Python影片数据爬取与数据分析系统。
数据爬取部分的开发是为了收集广泛的电影相关信息,包括电影名称、导演、演员、上映日期、评分、评论等。这些信息来自各种在线电影数据库、社交媒体平台以及电影院的官方网站。通过自动化的网络爬虫技术,我们能够实现大规模的数据采集,确保数据的准确性和及时性。这不仅有助于普通观众了解最新电影信息,还为电影制片方提供了市场反馈和竞争情报,有助于他们做出更明智的决策。
其次,数据分析部分的开发是为了利用收集到的电影数据进行深入的分析和可视化。通过使用Python编程语言以及各种数据分析工具和库,我们能够从海量数据中提取有价值的信息。这些信息包括观众对不同电影的评价趋势、不同导演或演员的影响力、票房表现的趋势分析等。这些分析结果对电影行业的参与者具有重要的决策价值。例如,制片方可以根据观众反馈来改进电影制作,电影院可以根据数据来制定上映计划,投资者可以根据趋势来做出投资决策。
最后,系统的可视化大屏展示部分是为了将分析结果以直观的方式呈现给用户。通过设计精美的数据可视化图表和大屏幕展示界面,用户可以快速理解电影行业的动态,掌握市场趋势。这也有助于提高决策的效率和准确性,使用户能够更好地规划他们的电影业务。
项目功能演示
影片数据爬取与数据分析系统演示视频文章来源:https://www.toymoban.com/news/detail-701650.html
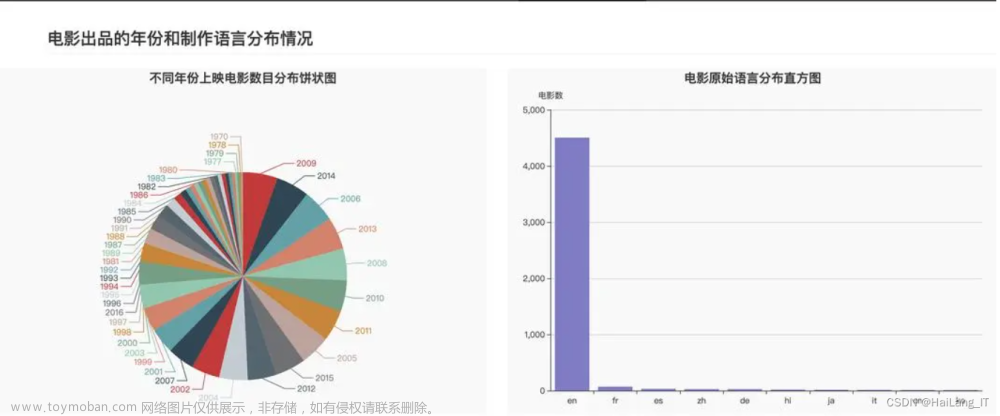
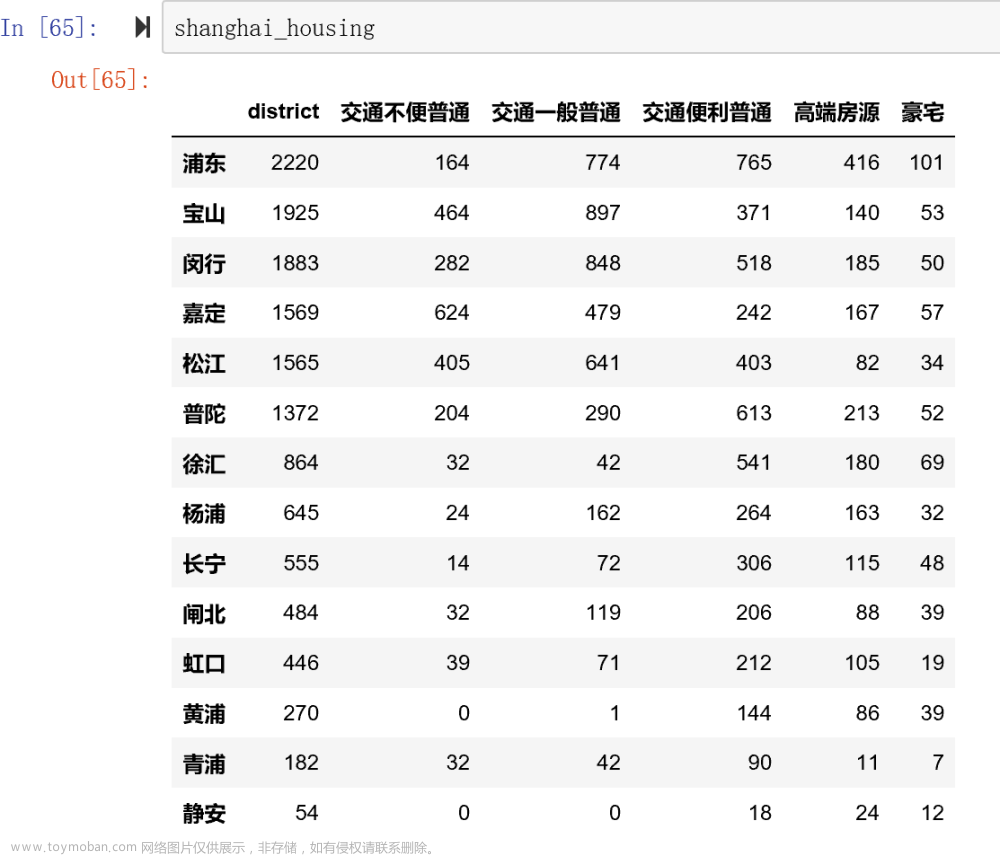
精彩页面设计



 文章来源地址https://www.toymoban.com/news/detail-701650.html
文章来源地址https://www.toymoban.com/news/detail-701650.html
4、 核心代码
# 导入所需的库和模块
import requests
from bs4 import BeautifulSoup
import pandas as pd
import matplotlib.pyplot as plt
# 定义一个函数来爬取电影数据
def scrape_movie_data(movie_url):
# 发起HTTP请求获取页面内容
response = requests.get(movie_url)
# 使用BeautifulSoup解析页面内容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取电影信息
title = soup.find('h1', {'class': 'movie-title'}).text
director = soup.find('div', {'class': 'director'}).text
actors = [actor.text for actor in soup.find_all('span', {'class': 'actor-name'})]
release_date = soup.find('span', {'class': 'release-date'}).text
rating = soup.find('span', {'class': 'rating'}).text
# 返回电影信息
return {
'Title': title,
'Director': director,
'Actors': ', '.join(actors),
'Release Date': release_date,
'Rating': rating
}
# 定义一个函数来可视化电影数据
def visualize_movie_data(movie_data):
# 创建一个DataFrame来存储电影数据
df = pd.DataFrame(movie_data)
# 绘制电影评分的直方图
plt.figure(figsize=(8, 6))
plt.hist(df['Rating'], bins=10, edgecolor='k')
plt.xlabel('Rating')
plt.ylabel('Frequency')
plt.title('Distribution of Movie Ratings')
plt.show()
# 主程序
if __name__ == '__main__':
# 输入电影网页的URL
movie_url = 'https://www.example.com/movies/movie1'
# 爬取电影数据
movie_data = scrape_movie_data(movie_url)
# 可视化电影数据
visualize_movie_data([movie_data])
到了这里,关于分享一个Python Django影片数据爬取与数据分析系统源码的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!