本文承接上文的代码进行改造,上文链接:HTTP上
1. 实现网站跳转
在浏览器上 输入 w3school 进行搜索

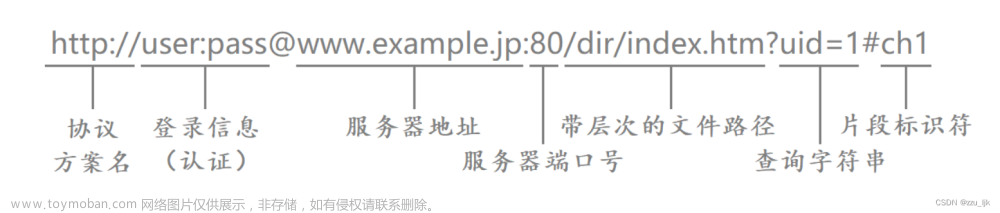
url 表示 链接
Link text 表示 文字/按钮
就可以跳转到指定的网站

在index.html 中,添加一行表示 百度链接,通过点击 Visit W3School 文字进入

运行可执行程序后,可点击Visit W3School 文字

在index.html中 粘贴为 百度的链接,所以点击直接跳转到百度网站
实现 自己的网站跳转

此时将百度的网址改为 自己实现的 file1与 file2文件

此时输入 主机IP + 端口号 ,可以看见 图片下方 有 file1 和file2 两个 链接

此时输入 主机IP + 端口号 ,可以看见 图片下方 有 file1 和file2 两个 链接
分别点击 file1 和file2都可进入不同的网站
2. 请求方法(get) && 响应方法(post)

其中最常用的是 GET和 POST方法
一般是由浏览器 客户端发起的 ,会构建一个 http request,携带的方法可能是GET/POST
促使浏览器 使用不同的方法 进行资源提交和请求
就提出了 HTML 表单的 概念
GET方法
点击查看:HTML表单

语法为form标签,以/form结束
形成输入框,允许用户把自己的个人信息进行直接提取,提交给服务器
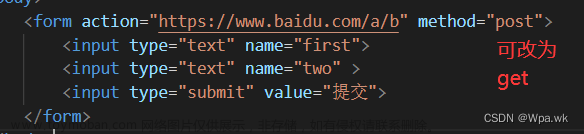
action表示 将表单提交给 /a/b/c.exe 对应方法 为 GET

通过GET方法,输入你的名字和密码,最终点击submit 提交

在输入名字 和密码后,点击提交,此时跳转页面的网址为http://101.43.252.143:8989/a/b/c.exe?myname=dname&mypasswd=123456
同时Linux上显示


浏览器在点击提交后,会自动构建HTTP请求
以?作为分隔符,左侧为要访问的资源,右侧为想要给资源的参数,参数为KV类型
GET也能进行提交参数,通过URL的方式提交参数
POST方法

将方法改为POST,其他不变

POST请求,提交数据时,通过正文部分提交参数的
GET与POST的应用场景
GET方法提交参数 不私密(不是安全的)
会把参数回显到 浏览器的URL上
POST方法提交参数比较私密一些
不会把参数回显到URL上
所以所有的登录 注册等行为,都要使用POST方法提参 (不是安全的)
url: http请求行的字符串,一般都会有大小的约束
正文 理论上可以非常大
建议 大数据使用POST,小数据 使用GET
3. HTTP状态码
为了告诉浏览器,返回的结果正确还是错误

在之前的代码中,直接告诉浏览器,它的状态码是200,即正确的

在HTTP服务器中,状态码分为五类,分别为1开头、2开头、3开头。4开头、5开头
1开头称为 信息性状态码
如:当前做了一个提交动作,但该动作比较耗费时间,为了尽快给客户端一点响应,返回一个1开头的状态码
表示当前请求已经被受理了,正在尽快处理
2开头称为 成功状态码
常用的如 200,表示这次请求是成功的,意味着给你的响应 可以正常去解释
3开头称为重定向状态码
如:301、302、307
重定向分为 永久性重定向 与 临时性重定向
4开头称为客户端错误状态码
如:404 403
如:在京东中 点击查看:京东官网

寻找 www.jd/a/b/c.html ,由于京东中并不存在这个页面,所以会报错
所以404报错,属于客户端报错,表示客户端属于非法请求
若客户端属于非法请求,服务器要告诉客户端,该请求是不合理的
在自己设计的代码中发现404
在自己设计的代码中,若访问的资源在网站中没有找到,则如何进行404
所以在wwwroot目录中, 创建一个文件 err_404.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>404 Not Found</title>
</head>
<body>
<h1>404 Not Found</h1>
<p>Sorry, the page you are looking for could not be found.</p>
</body>
</html>
在网上寻找到一个404 html网页源代码
在Main.cc的HandlerHttp回调函数中

若 ReadFile函数(功能为读取整个文件的内容)返回值 为 true,则表示读取文件成功

若ReadFile函数返回值为false,则表示读取文件失败,需添加404页面

创建一个 字符串 page_404,表示404页面的路径
文件打开失败,则将 404对应的路径 导入到 body(有效载荷) 中
在GetContentType函数(功能为判断某一种资源的后缀),直接判断为.html

当在可执行程序中输入 端口号8888时,就意味着浏览器只能输入 主机IP+端口号
当浏览器 输入 主机IP+端口号 后,又输入其他东西,则会导致 404 报错
5开头称为 服务器错误状态码
在服务器中创建进程或线程时,若创建进程或线程 处理失败了,则属于服务器错误
或者 在执行操作时,这个文件是存在的,但是打开/读取文件失败了,也属于服务器错误
一般来说,即便是服务器错误,也不会显示5开头的状态码,而会显示 1到4开头的状态码
3开头的状态码(重定向状态码)

主要看 301 302 307 三种 状态码
301表示 永久重定向
302与307 表示 临时重定向
永久重定向 和 临时重定向 的区别

服务器因为某些原因,如:将厂商从阿里云 变成 腾讯云
但是用户并不知道,用户可能还是向 老服务器进行请求
此时当前的主机并不会给客户端提供服务,而是告诉客户端 需要访问新的地址
所以客户端就会发起 第二次请求,去访问 新服务器
这种行为就叫做 重定向

如:在你们学校的东门,有一家XXX麻辣烫, 你和你的朋友在宿舍中,
在你们学校的东门,门口有一条路,这条路正在修路,但依旧可以走过去,所以你和你的朋友前往麻辣烫店吃了一次

又过了几个月,你俩又想吃麻辣烫
但此时麻辣烫门口贴了一张纸,因为门口修路,导致本店就餐环境不太好,所以本店迁移到西门
因为你俩非常想麻辣烫,所以就去了西门
这种行为就被称为 重定向
因为 XXX麻辣烫 是临时搬迁,所以并不了解什么时候搬回到东门,导致每次吃麻辣烫都要去东门看看,如果没在,再去西门吃麻辣烫
这种行为 称为 临时重定向
(每次都会去老地址,再由老地址跳转到新地址)
临时重定向不更改 浏览器的任何地址信息
后来麻辣烫店的老板发现西门的生意 比东门好,因为西门离学校宿舍最近,所以老板想把所有的老客户都拉拢到西门新店中
所以又重新在东门麻辣烫店粘贴一张告示
因为门口修路 本店就餐环境不好,以后想吃麻辣烫可以直接去西门,该店面就不经营了
此时你和你的朋友 依旧照常来到东门吃麻辣烫,但是发现告示后,还要去到西门
过了一段时间,你和你的朋友就直接去西门吃麻辣烫了
(重定向一次后,下次就会去新的地方了)
这种行为称为 永久重定向
永久重定向 会更改浏览器的本地书签
可以发现无论是 临时重定向(302) 还是 永久重定向(301),都会在东门麻辣烫店处留下一个新地址,
由客户端返回 301 302 307 这样的状态码 再加上 Location , Location后面可以跟上一个新店地址
Location:搭配3xx状态码 使用,告诉客户端接下来要去哪里访问
临时重定向的实操
在Main.cc的HandlerHttp回调函数中
只要用户发送请求,直接做重定向

定义一个字符串response,把302(临时重定向)添加到其中
并重定向到 https://www.qq.com/ 中

输入主机IP+端口号,就会直接跳转到qq官网中
永久重定向的实操

定义一个字符串response,把301(永久重定向)添加到其中
并重定向到 https://www.baidu.com/中

输入主机IP+端口号,就会直接跳转到百度官网中
之后就算是把该代码注释掉, 运行可执行程序 , 输入主机IP+8888,依旧还是百度官网
4. 关于Http的会话保持功能
http 本身是无状态的
如:访问了file1,过了一段时间,还想访问file1,http并不知道前段时间访问过file1,还会进行请求
在打开B站,并将用户登录后,发现 再次打开B站,用户已经处于登录状态了
所以就需要 cookie 与 session
Cookie:用于在客户端存储少量信息,通常用于实现会话(session)的功能

在登录时,服务器会向本地浏览器通过一些Http的选项,向本地写入一些cookie信息
所以当重新进入B站时,用户已经登录了

若将B站对应的cookie删除,则再次进入B站,就需要重新登录了
cookie的使用

服务器中有很多资源
当请求某种资源时,若服务器发现没有登录,就会要求客户端进行登录
在输入完账号密码后,服务器就会对账号密码进行认证
若认证通过了,就会返回认证成功的消息
服务器通过 Set-Cookie 把私人信息(用户名 密码等) 携带到 Http响应中
当浏览器收到携带 cookie的信息时,将response中响应的cookie信息在本地进行保存
浏览器对于本地 有两种保存方案:内存级、文件级
之后只要访问同样的网站时,请求中就会携带cookie信息(浏览器自动做的)
自动进行身份认证,就不需要用户输入 账号密码了

当你点了 一些由黑客发出的不该点的链接,就会导致 黑客把 所有的cookie信息盗取过来
若黑客 也去访问你曾经访问的网站, 该网站上的登录用户依旧是你
session id 的提出
上一个方案是有明显的缺点的,黑客可以获取到对应的账号密码等信息
所以使用当前方案

当前服务器中存在很多资源
当请求某种资源时,若服务器发现没有登录,就会要求客户端进行登录
当登录时 需要使用 POST方法 ,输入账号密码
在输入完账号密码后,服务器就会对账号密码进行认证
若认证通过后,新方案就会在服务器形成一个session对象 (用当前用户的基本信息 填充)
以及 seesion id (以10/16进制形成的序列 保证是唯一的)
把session id 通过http 响应 传给 客户端
之后访问时,Http 请求 都会携带 session id,就可以通过session id 去确认是否存在,若存在则可以访问这个资源文章来源:https://www.toymoban.com/news/detail-701674.html
就算是黑客再次盗取你的信息,也只会盗取session id ,虽然还是会存在使用你的身份去访问资源
但是不用担心 用户的账号密码泄露了文章来源地址https://www.toymoban.com/news/detail-701674.html
到了这里,关于【计算机网络】HTTP(下)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!