论文地址:https://arxiv.org/abs/2012.15712
论文代码:https://github.com/djiajunustc/Voxel-R-CNN
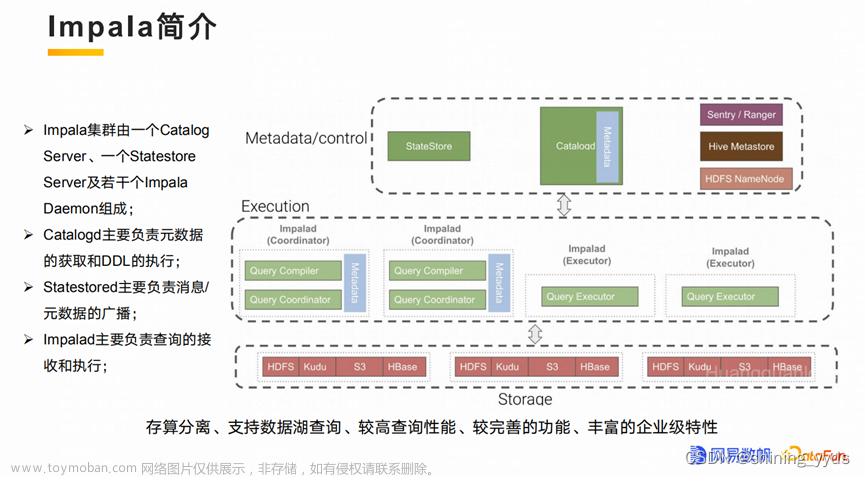
论文背景
基于点的方法具有较高的检测精度,但基于点的方法通常效率较低,因为对于点集抽象来说,使用点表示来搜索最近邻的代价更高。
相比于基于点,更高效,基于体素的结构更适合于特征提取,但由于输入点云被划分为规则的网格,因此往往产生较低的准确性(体素化经常导致精确位置信息的丢失)。
基于点的方法一样准确,与基于Voxels的方法一样快速的方法?
首先,论文认为精确定位原始点云是不错的,但没有必要。基于体素的方法通常会对 bird-eye-view (BEV)表示执行目标检测,即使输入数据是 3D 体素。相比之下,基于点的方法通常依赖于抽象的点表示来恢复 3D 结构上下文,并基于点方向的特征进行进一步的细化。
通过仔细观察底层机制,发现现有的基于体素的方法的关键缺点在于,它们将3D特征体转换为BEV表示,而从未恢复3D结构上下文。
 SECOND:将体素化数据馈送到三维骨干网进行特征提取。 然后将3D特征体转换为BEV表示。 最后,利用一个二维主干网和一个区域建议网络(RPN)进行检测。
SECOND:将体素化数据馈送到三维骨干网进行特征提取。 然后将3D特征体转换为BEV表示。 最后,利用一个二维主干网和一个区域建议网络(RPN)进行检测。
PV-RCNN:通过添加 Keypoints 分支来保存3D结构信息来扩展 SECOND。 引入体素集抽象(VSA)将多尺度三维体素特征集成到关键点中。 通过 ROI-grid-pooling 从关键点中进一步提取每个三维区域 proposals 的特征,进行 box refinement
SECOND 和 PV-RCNN 在检测性能(即准确性和效率)上存在较大差距:
1.SECOND 是 one-stage 方法,PV-RCNN 提取检测头进行 box refinement;
2.PV-RCNN 中的关键点保留了三维结构信息,SECOND 直接对BEV表示进行检测。
3.PV-RCNN 比 SECOND 慢得多;
3.SECOND AP 不如 PV-RCNN。
通过对比得到:
1.三维结构对于三维目标检测器具有重要的意义,因为单凭BEV表示不足以精确预测三维空间中的 bounding boxes;
2.点-体素特征交互耗时且影响检测器效率。
论文内容

基于体素的 3D 目标检测的两阶段框架。
a)一个 3D backbone;
b)一个 2D backbone,后面跟着 RPN;
c)一个 Voxel ROI pooling 和 一个用于 box refinement 的检测子网。
首先将原始点云划分为规则体素,并利用 3D backbone 进行特征提取。然后将稀疏的3D体素转化为BEV表示,在BEV表示上应用 2D backbone 和 RPN 生成 3D 区域建议。随后,使用 Voxel ROI pooling 提取 RoI 特征,并将这些特征输入检测子网进行 box refinement。
Voxel ROI pooling

为了直接从三维体素特征体集合空间上下文,论文提出了 Voxel ROI pooling。
Voxel Volumes as Points。 将稀疏 3D volumes 表示为一组非空体素中心点 { v i = ( x i , y i , z i ) } i = 1 N \{v_i=(x_i,y_i,z_i)\}^N_{i=1} {vi=(xi,yi,zi)}i=1N及其对应的特征向量{φi}ni=1。 具体而言,利用指数、体素大小和点云边界计算体素中心的三维坐标。
体素查询
从 3D feature volumes 中查找相邻体素。 与无序点云相比,体素在量化空间中有规律地排列,便于邻居访问。 例如,体素查询的 26-neighbor voxels 可以通过在体素索引
(
i
,
j
,
k
)
(i,j,k)
(i,j,k)上添加一个三重偏移量
(
Δ
i
,
Δ
j
,
Δ
k
)
,
Δ
i
,
Δ
j
,
Δ
k
∈
{
−
1
,
0
,
1
}
(Δ_i,Δ_j,Δ_k),Δi,Δj,Δk∈\{-1,0,1\}
(Δi,Δj,Δk),Δi,Δj,Δk∈{−1,0,1} 来计算。 利用这一特性,论文设计了体素查询来有效地对体素进行分组。
首先将查询点量化为一个体素,然后通过 indices translation 转换获取相邻体素。在体素查询中利用曼哈顿距离,在一个距离阈值内采样多达
K
K
K 个体素。具体来说,体素
α
=
(
i
α
,
j
α
,
k
α
)
α=(i_α,j_α,k_α)
α=(iα,jα,kα) 和
β
=
(
i
β
,
j
β
,
k
β
)
β=(i_β,j_β,k_β)
β=(iβ,jβ,kβ) 之间的曼哈顿距离
D
(
α
,
β
)
D(α,β)
D(α,β) 计算如下:
D
m
(
α
,
β
)
=
∣
i
α
−
i
β
∣
+
∣
j
α
−
j
β
∣
+
∣
k
α
−
k
β
∣
.
(1)
\tag1 D_m(\alpha , \beta) = |i_\alpha - i_\beta|+|j_\alpha - j_\beta|+ |k_\alpha - k_\beta|.
Dm(α,β)=∣iα−iβ∣+∣jα−jβ∣+∣kα−kβ∣.(1)具体地,计算体素
α
=
(
i
α
,
j
α
,
k
α
)
α=(i_α,j_α,k_α)
α=(iα,jα,kα) 与
β
=
(
i
β
,
j
β
,
k
β
)
β=(i_β,j_β,k_β)
β=(iβ,jβ,kβ) 之间的曼哈顿距离
D
(
α
,
β
)
D(α,β)
D(α,β) 为:假设三维特征体中有
n
n
n 个非空体素,利用球查询来查找给定查询点的相邻体素,时间复杂度为
O
(
n
)
O(n)
O(n)。然而,进行体素查询的时间复杂度只有
O
(
K
)
O(K)
O(K),其中
K
K
K 为邻居数。邻居感知属性使得使用体素查询对邻居体素特征进行分组比使用球体查询对邻居点特征进行分组更有效。
体素 ROI Pooling 层
首先将一个 region proposal 划分为
G
×
G
×
G
G×G×G
G×G×G 的规则 sub-voxel。 中心点作为相应子体素的网格点。 由于3D特征量非常稀疏(非空体素占小于3%的空间),不能直接利用最大池化每个 sub-voxel 的特征。取而代之的是,论文将相邻体素的特征集成到网格点中进行特征提取。具体来说,给定一个网格点
g
i
g_i
gi,首先利用体素查询对一组相邻的体素进行分组
Γ
i
=
{
v
i
1
,
v
i
2
,
.
.
.
,
v
i
K
}
Γ_i = \{ v^1_i, v^2_ i,...,v^K_i\}
Γi={vi1,vi2,...,viK}。 然后,使用 PointNet 模块聚合相邻的体素特征:
η
i
=
max
k
=
1
,
2
,
.
.
.
,
K
{
Ψ
(
[
v
i
k
−
g
i
;
ϕ
i
k
]
)
}
,
(2)
\tag2 \eta_i = \max_{k=1,2,...,K}\{ \Psi ([v_i^k - g_i;\phi_i^k]) \},
ηi=k=1,2,...,Kmax{Ψ([vik−gi;ϕik])},(2)其中
v
i
−
g
i
v_i-g_i
vi−gi 表示相对坐标,
ϕ
i
k
\phi ^k_i
ϕik 是
v
i
k
v^k_i
vik 的体素特征,
Ψ
(
⋅
)
\Psi(·)
Ψ(⋅) 表示MLP。沿着通道进 max pooling 操作
max
(
⋅
)
\max(·)
max(⋅) 以获得聚合的特征向量
η
i
η_i
ηi。特别是,利用体素 RoI Pooling 从 3D backbone network 的最后两个阶段的 3D 特征体素特征中提取体素特征。对于每个阶段,设置了两个曼哈顿距离阈值,以用多个尺度对体素进行分组。然后,将不同阶段、不同规模的特征聚合在一起,得到 RoI 特征。
加速局部聚合
即使使用论文提出的体素查询,在体素 RoI pooling 中的局部聚合操作(即 PointNet)模块仍然涉及很大的计算复杂度即使使用论文提出的体素查询。
如图所示,总共有
M
M
M 个网格点(
M
=
r
×
G
3
M=r×G^3
M=r×G3,其中
r
r
r 为ROI个数,
G
G
G为网格大小),每个网格点分组
K
K
K 个体素。 分组特征向量的维数为
C
+
3
C+3
C+3,包括
C
−
d
i
m
C-dim
C−dim 体素特征和
3
−
d
i
m
3-dim
3−dim 相对坐标。 在应用FC层时,分组体素占用了大量的内存,并导致了较大的计算 FLOPs
(
O
(
M
×
K
×
(
C
+
3
)
×
C
′
)
)
(O(M×K×(C+3)×C^{'}))
(O(M×K×(C+3)×C′))。
论文另外引入了一个加速的 PointNet 模块,以进一步降低 Voxel Query 的计算复杂度。
将体素特征和相对坐标分解为两个流。 给定权重为
W
∈
R
C
′
,
C
+
3
W∈\R^{C^{'},C+3}
W∈RC′,C+3 的 FC 层,将其划分为
W
F
∈
R
C
′
,
C
W_F∈\R^{C^{'},C}
WF∈RC′,C 和
W
C
∈
R
C
′
,
3
W_C∈\R^{C^{'},3}
WC∈RC′,3。 由于体素特征与网格点无关,在进行体素查询之前,在体素特征上应用了一个带
W
F
W_F
WF 的 FC 层。 然后,在体素查询后,只将分组的相对坐标乘以
W
C
W_C
WC 得到相对位置特征,并将其添加到分组的体素特征中。加速的 PointNet 模块的 Flop 为
O
(
N
×
C
×
C
′
+
M
×
K
×
3
×
C
′
)
O(N×C×C^{'}+M×K×3×C^{'})
O(N×C×C′+M×K×3×C′)。 由于分组体素的个数
(
M
×
K
)
(M×K)
(M×K) 比
N
N
N 高出一个数量级,加速的 PointNet 模块比原来的的 PointNet 模块效率更高。
Backbone 和 RPN
3D backbone network 逐渐将体素化输入转换成 feature volumes。然后,将输出张量沿 Z 轴叠加生成 BEV 特征图。
2D backbone network 由两个部分组成:一个自顶向下的特征提取子网络和一个多尺度的特征融合子网络,该子网络由两个标准的3×3卷积层组成,该子网络对自顶向下的特征进行上采样和级联。
最后,将 2D backbone network 的输出与两个 1×1 卷积层进行卷积,生成3D RPN。
检测头
检测头以 ROI 特征作为输入进行 box refinement。 具体来说,共享的2层 MLP 首先将 ROI 特征转换为特征向量。 然后,将扁平化特征注入两个 sibling 分支:一个用于 bounding box 回归,另一个用于置信度预测。bounding box 回归分支预测从3D RPN 到地面真值 box 的残差,而置信度分支预测与 IOU 相关的置信度得分。
Training Objectives
RPN损失
将RPN的损失设计为分类损失和 box 回归损失的组合,如下:
L
R
P
N
=
1
N
f
g
[
∑
i
L
c
l
s
(
p
i
a
,
c
i
∗
)
+
L
(
c
i
∗
≥
1
)
∑
i
L
r
e
g
(
δ
i
a
,
t
i
∗
)
]
(3)
\tag3 \mathcal L_{RPN} = \frac{1}{N_{fg}}[\sum_i \mathcal L_{cls}(p_i^{a},c_i^{*})+ \mathbb L(c_i^{*} \geq 1)\sum_i \mathcal L_{reg}(\delta_{i}^{a},t_{i}^{*})]
LRPN=Nfg1[i∑Lcls(pia,ci∗)+L(ci∗≥1)i∑Lreg(δia,ti∗)](3)其中,
N
f
g
N_{fg}
Nfg 表示前景锚点的数量,
p
i
a
p^a_i
pia 和
δ
i
a
δ^a_i
δia 为分类分支和框回归分支的输出,
c
i
∗
c^∗_i
ci∗ 和
t
i
∗
t^∗_i
ti∗ 分别为分类标签和回归目标。
L
(
c
i
∗
≥
1
)
\mathbb L(c_i^{*} \geq 1)
L(ci∗≥1) )表示仅使用前景锚点计算的回归损失。在这里,利用 Focal 损失进行分类,利用 Huber 损失进行 box regression。
检测头损失
分配给 confidence 分支的目标是与IOU相关的值:
l
i
∗
(
IoU
i
)
=
{
0
IoU
i
<
θ
L
,
IoU
i
−
θ
L
θ
H
−
θ
L
θ
L
≤
IoU
i
<
θ
H
,
1
IoU
i
>
θ
H
,
(4)
\tag4 l_i^* (\text{IoU}_i) = \begin{cases} 0 &\text{IoU}_i < \theta_L, \\ \frac{\text{IoU}_i - \theta_L}{\theta_H - \theta _ L} & \theta_L \leq \text{IoU}_i < \theta_H,\\ 1 &\text{IoU}_i > \theta_H, \end{cases}
li∗(IoUi)=⎩
⎨
⎧0θH−θLIoUi−θL1IoUi<θL,θL≤IoUi<θH,IoUi>θH,(4) 其中,
IoU
i
\text{IoU}_i
IoUi 是第
i
i
i 个 proposal 和相应的地面真值 box 之间的
I
o
U
IoU
IoU,
θ
H
θ_H
θH 和
θ
L
θ_L
θL 是前景和背景
I
o
U
IoU
IoU 阈值 。论文利用二元交叉熵损失进行置信度预测。 与RPN一样,Box回归分支也使用Huber损失。 探测头的损失计算如下:
L
h
e
a
d
=
1
N
s
[
∑
i
L
c
l
s
(
p
i
,
l
i
∗
(IoU
i
)
)
+
L
(
c
i
∗
≥
1
)
]
(5)
\tag5 \mathcal L_{head} = \frac{1}{N_s}[\sum_i \mathcal L_{cls}(p_i,l_i^*\text{(IoU}_i))+\mathbb L(c_i^{*} \geq 1)]
Lhead=Ns1[i∑Lcls(pi,li∗(IoUi))+L(ci∗≥1)](5) 其中
N
s
N_s
Ns 是训练阶段的抽样区域 proposal 数,
L
(
IoU
i
≥
θ
r
e
g
)
\mathbb L(\text{IoU}_i≥θ_{reg})
L(IoUi≥θreg) 表示只有
IoU
>
θ
r
e
g
\text{IoU}>θ_{reg}
IoU>θreg 的区域 proposals 才会导致回归损失。文章来源:https://www.toymoban.com/news/detail-701678.html
论文总结
论文提出了一种基于体素表示的新型 3D 目标检测器——Voxel R-CNN。以体素为输入,Voxel R-CNN首先从鸟瞰视图的特征表示中生成密集区域 proposals,然后利用 voxel RoI pooling 从3D体素特征中提取区域特征,进一步细化。通过充分利用体素表示,Voxel R-CNN在准确性和效率之间取得了平衡。文章来源地址https://www.toymoban.com/news/detail-701678.html
到了这里,关于Voxel R-CNN:基于体素的高性能 3D 目标检测的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!