一、Selenium简介
Selenium是一个用于Web应用程序测试的工具,Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。模拟浏览器功能,自动执行网页中的js代码,实现动态加载。
二、环境配置
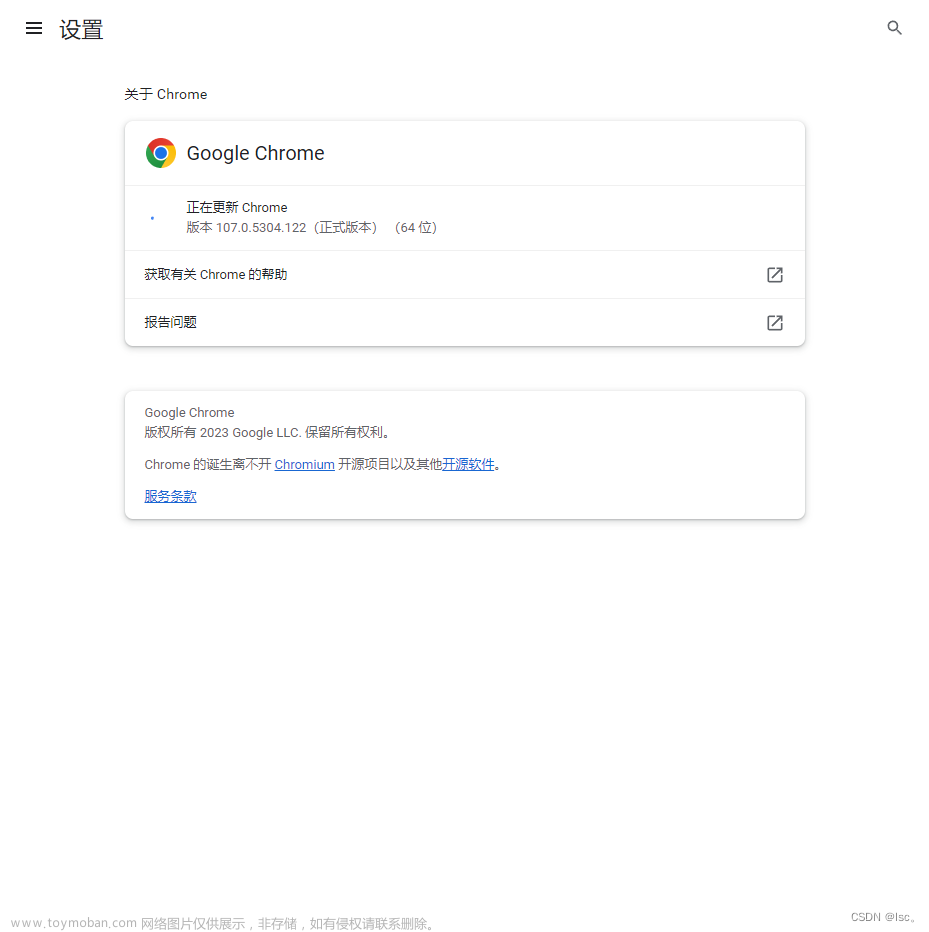
1、查看本机电脑谷歌浏览器的版本。
打开谷歌浏览器-->右上角三个点-->帮助-->关于

2、下载谷歌浏览器的驱动
下载地址:http://chromedriver.storage.googleapis.com/index.html
找到对应浏览器版本驱动文章来源:https://www.toymoban.com/news/detail-701948.html
 文章来源地址https://www.toymoban.com/news/detail-701948.html
文章来源地址https://www.toymoban.com/news/detail-701948.html
3、安装selenium
pip install selenium三、使用
1、旧版本使用
from selenium import webdriver
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'https://www.baidu.com'
browser.get(url)
# 元素定位
# 根据id来找到对象
button = browser.find_element_by_id('su')
print(button)
# 根据标签属性的属性值来获取对象的
button = browser.find_element_by_name('wd')
print(button)
# 根据xpath语句来获取对象
button = browser.find_elements_by_xpath('//input[@id="su"]')
print(button)
# 根据标签的名字来获取对象
button = browser.find_elements_by_tag_name('input')
print(button)
# 使用的bs4的语法来获取对象
button = browser.find_elements_by_css_selector('#su')
print(button)
button = browser.find_element_by_link_text('直播')
print(button)2、新版本使用
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# driver=webdriver.Chrome(executable_path='chromeselenium/chromedriver')
# 改为
service = Service(executable_path='chromedriver')
driver = webdriver.Chrome(service=service)
# inputTag = driver.find_element_by_id("value") # 利用ID查找
# 改为:
inputTag = driver.find_element(By.ID, "value")
# inputTags = driver.find_element_by_class_name("value") # 利用类名查找
# 改为:
inputTag = driver.find_element(By.CLASS_NAME, "value")
# inputTag = driver.find_element_by_name("value") # 利用name属性查找
# 改为:
inputTag = driver.find_element(By.NAME, "value")
# inputTag = driver.find_element_by_tag_name("value") # 利用标签名查找
# 改为:
inputTag = driver.find_element(By.TAG_NAME, "value")
# inputTag = driver.find_element_by_xpath("value") # 利用xpath查找
# 改为:
inputTag = driver.find_element(By.XPATH, "value")
# inputTag = driver.find_element_by_css_selector("value") # 利用CSS选择器查找
# 改为:
inputTag = driver.find_element(By.CSS_SELECTOR, "value")
四、交互案例
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 创建浏览器对象
path = 'chromedriver.exe'
service = Service(executable_path=path)
browser = webdriver.Chrome(service=service)
# url
url = 'https://www.baidu.com'
browser.get(url)
import time
time.sleep(2)
# 获取文本框的对象
# input = browser.find_element_by_id('kw')
input = browser.find_element(By.ID, 'kw')
# 在文本框中输入周杰伦
input.send_keys('周杰伦')
time.sleep(2)
# 获取百度一下的按钮
# button = browser.find_element_by_id('su')
button = browser.find_element(By.ID, 'su')
# 点击按钮
button.click()
time.sleep(2)
# 滑到底部
js_bottom = 'document.documentElement.scrollTop=100000'
browser.execute_script(js_bottom)
time.sleep(2)
# 获取下一页的按钮
# next = browser.find_element_by_xpath('//a[@class="n"]')
next = browser.find_element(By.XPATH, '//a[@class="n"]')
# 点击下一页
next.click()
time.sleep(2)
# 回到上一页
browser.back()
time.sleep(2)
# 回去
browser.forward()
time.sleep(3)
# 退出
browser.quit()到了这里,关于python爬虫-Selenium的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!