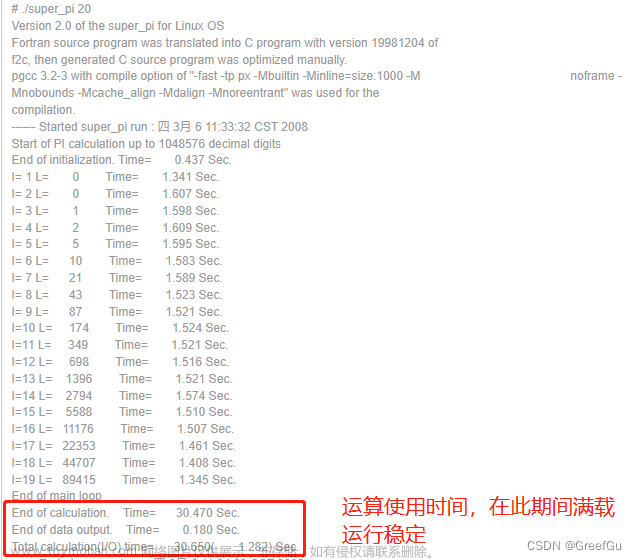
(1)查看端口 lsof -i:8080 / netstat
lsof -i:8080:查看8080端口占用
lsof abc.txt:显示开启文件abc.txt的进程
lsof -c abc:显示abc进程现在打开的文件
lsof -c -p 1234:列出进程号为1234的进程所打开的文件
lsof -g gid:显示归属gid的进程情况
lsof +d /usr/local/:显示目录下被进程开启的文件
lsof +D /usr/local/:同上,但是会搜索目录下的目录,时间较长
lsof -d 4:显示使用fd为4的进程
lsof -i -U:显示所有打开的端口和UNIX domain文件netstat -tunlp 用于显示 tcp,udp 的端口和进程等相关情况。
netstat 查看端口占用语法格式:
netstat -tunlp | grep 端口号
-t (tcp) 仅显示tcp相关选项
-u (udp)仅显示udp相关选项
-n 拒绝显示别名,能显示数字的全部转化为数字
-l 仅列出在Listen(监听)的服务状态
-p 显示建立相关链接的程序名(2)C++ string 底层实现方式
C++标准库中string的三种底层实现方式_c++ string底层实现_Yol_2626的博客-CSDN博客
三种方式深拷贝、写时复制、段字符串优先。
(3)线程模型
三种线程模型:
一对一模型:直接使用API或者系统调用,优点是用户线程和内核线程一致,但是由于内核线程数量有限,所以会限制用户线程数量,并且内核线程的切换上下文的切换开销大,导致用户线程执行效率下降。
多对一模型:一个内核线程对应多个用户线程,线程间的切换有用户代码进行,优点是多对一速度快,缺点是如果一个用户线程阻塞,其他的线程无法执行,另外一个好处是用户线程没有限制。
多对多模型:结合了一对一和多对一的优点。
(3)用C++实现String类(没写出来,哎,应该用vector写,会简单一点,而不是用指针写)
以下代码来源C++ STL String底层实现分析_517 pacifikal的博客-CSDN博客
进行了一点修改。
#ifndef __MYSTRING_H__
#define __MYSTRING_H__
#include <assert.h>
#include <memory.h>
#include <iostream>
using namespace std;
class MyString {
public:
MyString():m_size(0), m_ptr(nullptr),m_capacity(0) {
}
MyString(const MyString& s) {
m_ptr = new char[s.m_size+1];
strcpy(m_ptr, s.m_ptr);
m_size = s.m_size;
m_capacity = s.m_capacity;
}
MyString(const char* s):m_ptr(new char[strlen(s)+1]),m_size(0),m_capacity(0) {
strcpy(m_ptr, s);
m_size = strlen(s);
m_capacity = m_size;
}
// 赋值运算符
MyString& operator=(const MyString& str) {
// 此时对象自己的对象已经存在,直接进行赋值
strcpy(m_ptr, str.m_ptr);
m_size = strlen(str.m_ptr);
m_capacity = strlen(str.m_ptr);
return *this;
}
const char& operator[] (size_t index) const {
assert(index < m_size);
return m_ptr[index];
}
MyString& operator+=(const char& c) {
this->push_back(c);
return *this;
}
MyString& operator+=(const char* str) {
this->append(str);
return *this;
}
MyString& operator+=(const MyString& str) {
this->append(str.m_ptr);
return *this;
}
// 方法
size_t strlen (const char* str) {
size_t length = 0;
if (str == nullptr) return 0;
while (*str++ != '\0') length++;
return length;
}
char* strcpy(char* strDest, const char* strSrc) {
assert((strDest != nullptr) && (strSrc != nullptr));
char* addr = strDest;
while ((*strDest++ = *strSrc++) != '\0');
return addr;
}
void reserve(size_t newCapacity) {
if (newCapacity > m_capacity) {
char* str = new char[newCapacity + 1];
for (int i = 0; i < m_size; i++) {
str[i] = m_ptr[i];
}
delete[] m_ptr;
m_ptr = str;
m_capacity = newCapacity;
}
}
void resize(size_t newSize) {
if (newSize > m_capacity) {
reserve(newSize);
}
if (newSize > m_size) {
memset(m_ptr+m_size, '\0', newSize-m_size);
}
m_size = newSize;
m_ptr[m_size] = '\0';
}
void push_back(const char& c) {
int newCapacity;
if (m_size == m_capacity) {
if (m_capacity == 0) {
newCapacity = 32;
} else {
newCapacity = m_capacity * 2;
}
reserve(newCapacity);
}
m_ptr[m_size] = c;
m_size++;
m_ptr[m_size] = '\0';
}
size_t size() {
return m_size;
}
size_t capacity() {
return m_capacity;
}
void append(const char* str) {
int newLength = strlen(str);
if (newLength+m_size > m_capacity) {
reserve(newLength + m_size);
}
for (int i = 0; i <= newLength; i++) {
m_ptr[m_size+i] = str[i];
}
// 下面这句似乎可以不要
m_ptr[newLength+m_size] = '\0';
m_size += newLength;
}
void insert(size_t position, const char& c) {
assert(position <= m_size);
if (m_size == m_capacity) {
size_t newCapacity;
if (m_capacity == 0) {
newCapacity = 32;
} else {
newCapacity = m_capacity * 2;
}
reserve(newCapacity);
}
size_t endPosition = m_size;
while (endPosition-position) {
m_ptr[endPosition] = m_ptr[endPosition-1];
--endPosition;
}
m_ptr[endPosition] = c;
m_ptr[++m_size] = '\0';
}
void insert(size_t position, const char* str) {
int len = m_size + strlen(str);
if (len > m_capacity) {
reserve(len);
}
for (int i = position; i < strlen(str) + position; i++) {
m_ptr[i] = str[i-position];
}
m_ptr[m_size] = '\0';
}
void erase(size_t position, size_t length) {
assert(position < m_size && position >= 0);
if (position + length >= m_size) {
m_ptr[position] = '\0';
m_size = position;
return;
}
size_t start = position + length;
while (start <= m_size) {
m_ptr[position++] = m_ptr[start++];
}
m_size = position-1;
}
size_t find(const char& c, size_t position = 0) {
assert(position < m_size);
while (position < m_size) {
if (m_ptr[position] == c) {
return position;
}
position++;
}
return -1;
}
char* strstr(char* src, char* substr) {
assert(src != nullptr && substr != nullptr);
unsigned int size = strlen(src);
for (int i = 0; i < size; i++, ++src) {
char* p = src;
for (char* q = substr;;++p,++q) {
if (q == '\0'){
return src;
} else {
break;
}
}
}
return nullptr;
}
size_t find(char* str, size_t position=0) {
assert(position < m_size);
char* s = strstr(m_ptr+position, str);
if (s) {
return s-m_ptr;
}
return -1;
}
// 迭代器
typedef char* iterator;
typedef const char* const_iterator;
iterator begin() {
return m_ptr;
}
iterator end() {
return m_ptr + m_size;
}
const_iterator begin() const {
return m_ptr;
}
const_iterator end() const {
return m_ptr + m_size;
}
friend ostream& operator<<(ostream& out, const MyString& str);
friend istream& operator>>(istream& in, MyString& str);
~MyString() {
if (m_ptr) {
delete[] m_ptr;
m_ptr = nullptr;
m_size = 0;
m_capacity = 0;
}
}
private:
size_t m_size;
size_t m_capacity;
char* m_ptr;
};
ostream& operator<<(ostream& out, const MyString& str) {
// for (auto it = str.begin(); it != str.end(); it++) {
// out << *it;
// }
// out << endl;
// return out;
for (int i = 0; i < str.m_size; i++) {
out << str[i];
}
out << endl;
return out;
}
istream& operator>>(istream& in, MyString& str) {
char ch;
str.resize(0);
str.m_size = str.m_capacity = 0;
while ((ch=getchar())!=EOF) {
if (ch=='\n') {
return in;
}
str+=ch;
}
return in;
}
#endif
(4)导入表是什么?
记录了动态库的函数、以及库的路径
(5)PE、ELP文件有什么内容。
(6)stdcall,cdecl,fastcall,thiscall,naked call
C++:__stdcall详解 - 瘋子朱磊 - 博客园 (cnblogs.com)
(7)C++14, C++17, C++20新特性
(8)读写锁,线程创建方式
(9)lambda函数的底层如何实现。
编译器实现lambda表达式分为以下几个步骤:(参考C++进阶(八) :Lambda 表达式及底层实现原理【详解】_c++ lambda表达式原理_贺二公子的博客-CSDN博客)
- 创建 lambda匿名类,实现构造函数,使用 lambda 表达式的函数体重载 operator()(所以 lambda 表达式 也叫匿名函数对象)
- 创建 lambda 对象
- 通过对象调用 operator()
所以编译器将 lambda 表达式翻译后的代码:
class lambda_xxxx
{
private:
int a;
int b;
public:
lambda_xxxx(int _a, int _b) :a(_a), b(_b)
{
}
bool operator()(int x, int y) throw()
{
return a + b > x + y;
}
};
void LambdaDemo()
{
int a = 1;
int b = 2;
lambda_xxxx lambda = lambda_xxxx(a, b);
bool ret = lambda.operator()(3, 4);
}
- lambda 表达式中的捕获列表,对应 lambda_xxxx 类的 private 成员
- lambda 表达式中的形参列表,对应 lambda_xxxx 类成员函数 operator() 的形参列表
- lambda 表达式中的 mutable,表明 lambda_xxxx 类成员函数 operator() 的是否具有常属性 const,即是否是 常成员函数
- lambda 表达式中的返回类型,对应 lambda_xxxx 类成员函数 operator() 的返回类型
- lambda 表达式中的函数体,对应 lambda_xxxx 类成员函数 operator() 的函数体
(10)weak_ptr 如何使用
(11)虚析构函数如何实现释放子类的内存空间的。
(12)输入一个n和一个字符串,求组成的最小的新的字符串,使得原来的字符串至少出现n次,例如:n = 4, s = aaa ,则组成字符串为aaaaaa,输入n=2,s=abccab,则组成的字符串为abccabccab,(这里面主要是涉及到求next数组,利用s最后一个next数组的值,往后进行拓展)
#include <iostream>
#include <string>
#include <vector>
using namespace std;
int main() {
int n;
while (cin >> n) { // 注意 while 处理多个 case
string s;
cin >> s;
if (n==1) {
cout << s << endl;
} else {
vector<int> next;
next.push_back(0);
for (int i = 1, j = 0; i < s.size(); i++) {
while(j>0 && s[j]!=s[i]) {
j = next[j-1];
}
if (s[j] == s[i]) {
j++;
}
next.push_back(j);
}
n--;
string s1 = s;
while (n) {
int start = next.back();
// 每次添加的是原字符串从start之后的字符串
s += s1.substr(start);
n--;
}
cout << s << endl;
}
}
}(13)输入数字t,接下来2*t行,每行一个字符串分别为S,T(只含有小写字母) ,一次操作为将S的最后一个字符串放到最开始,问是否可以经过若干次操作,将S变为T。例如:S=kyoto,T=tokyo,输出为Yes
#include <iostream>
#include <string>
using namespace std;
int main() {
int t;
while (cin >> t) { // 注意 while 处理多个 case
string s1, s2;
for (int i = 0; i < t; i++) {
cin >> s1;
cin >> s2;
int len = s1.size();
bool flag = false;
for (int i = 0; i < len; i++) {
string str1 = "";
str1 += s1[len-1];
string str2 = s1.substr(0, len-1);
str2 = str1 + str2;
cout << str1 << "-" << str2 << endl;
string str = s1 + s2;
if (str2.compare(s2) == 0) {
cout << "Yes" << endl;
flag = true;
break;
}
s1 = str2;
}
if (!flag) {
cout << "No" << endl;
}
}
}
}(14)给定一个数组,含有n个元素,k表示要调出k个区间,t表示区间和为t的倍数。求k个区间和的最大值。例如:【2,3,5,2】k=3, t = 2, 区间[1,3] 和为10,题目忘了
下面是超时的算法
#include <iostream>
#include <vector>
#include <queue>
#include <map>
using namespace std;
static bool cmp(vector<int>& a, vector<int>& b) {
return a[2] < b[2];
}
// priority_queue<int, vector<vector<int>>, cmp> q;
priority_queue<int, vector<int>, greater<int>>q;
map<string, int> mp;
void backtrace(vector<int>& nums, int start, vector<int> path, int t, int k) {
if (path.size() == 2) {
int part_sum = nums[path[1]] - nums[path[0]-1];
string state = to_string(path[0]) + "-" + to_string(path[1]);
if (!mp[state]) {
if (part_sum%t == 0) {
if (q.size() < k) {
q.push(part_sum);
} else if (q.top() < part_sum) {
q.pop();
q.push(part_sum);
}
// cout << path[0] << " " << path[1] << " " << part_sum << endl;
mp[state]++;
}
}
return;
}
for (int i = start; i <= nums.size(); i++) {
path.push_back(i);
backtrace(nums, i+1, path, t, k);
path.pop_back();
backtrace(nums, i+1, path, t, k);
}
}
int main() {
int n, k, t;
while (cin >> n >> k >> t) { // 注意 while 处理多个 case
vector<int> nums(n+1);
for (int i = 1; i <= n; i++) {
int temp;
cin >> temp;
nums[i] = temp + nums[i-1];
}
vector<int> path;
backtrace(nums, 1, path, t);
int sum = 0;
while (k--) {
sum += q.top();
q.pop();
}
cout << sum << endl;
}
return 0;
}(15)给出n,m,k分别表示男生人数,女生人数,需要选出的总人数,其中至少选择2名女生和3名男生,问有多少种不同的选择方法,结果用1000000007取模。(富途科技)
#include <iostream>
using namespace std;
long getSum(int n, int k) {
long t1 = 1;
long t2 = 1;
for (int i = 1; i <= k; i++) {
t1 = t1 * i;
t2 = t2 * (n-i+1);
}
return t2 / t1;
}
int main() {
int n, m, k;
while (cin >> n >> m >> k) { // 注意 while 处理多个 case
int ans = 0;
bool first = true;
long girl_sum, man_sum;
for (int i = 2; i <= m; i++) {
int man = k - i;
if (man < 3) {
break;
}
if (man > n) continue;
girl_sum = getSum(m, i);
man_sum = getSum(n, man);
ans += (girl_sum * man_sum);
ans %= (1000000007);
}
cout << ans << endl;
}
}(16)VPN原理
(17)https为什么能够被抓包,http1,http2, http3区别
参考连接为什么如此安全的https协议却仍然可以被抓包呢?_guolin的博客-CSDN博客
写一篇最好懂的HTTPS讲解_郭霖 https_guolin的博客-CSDN博客
(18)Socket是哪一层的协议,如果缺失会怎么样?
(19)蜜罐技术
(20)TCP为什么需要三次握手、四次挥手
(21)https过程
(22)一个数组,找到数组中每个元素下一个比他大的数字、当为最后一个元素的时候,它的下一个为数组的第一个元素,如果不存在比它大的数字,则为-1;
面试过程中用的双重for循环。面试官说性能低下。文章来源:https://www.toymoban.com/news/detail-701955.html
#include <vector>
#include <iostream>
#include <stack>
using namespace std;
vector<int> nextGetgreaternums(vector<int>& nums) {
int len = nums.size();
vector<int> ans(2*len);
// 先将数组进行拓展
for (int i = 0; i < len-1; i++) {
nums.push_back(nums[i]);
}
int left = 0, right = 1;
stack<int> stk;
stk.push(0);
while (right < nums.size()) {
if (stk.size() && nums[right] > nums[stk.top()])
{
// 找到一个比栈顶元素大的
ans[stk.top()] = nums[right];
stk.pop();
} else {
stk.push(right);
right++;
}
}
while(stk.size()) {
ans[stk.top()] = -1;
stk.pop();
}
ans.resize(len);
return ans;
}
int main() {
vector<int> nums{2,1,2,4,3};
vector<int> ans = nextGetgreaternums(nums);
for (int i = 0; i < ans.size(); i++) {
cout << ans[i] << " ";
}
system("pause");
return 0;
}(23)lambda函数
#include <iostream>
using namespace std;
int main()
{
int a=9;
auto fun1=[=]{return a+1;};
auto fun2=[&]{return a+1;};
cout<<"fun1:"<<fun1()<<endl;
cout<<"fun2:"<<fun2()<<endl;
++a;
cout<<"++a执行之后的值"<<endl;
cout<<"fun1:"<<fun1()<<endl;
cout<<"fun2:"<<fun2()<<endl;
return 0;
}
标准输出:
fun1:10
fun2:10
++a执行之后的值
fun1:10
fun2:11这个题答错了,第二次func1执行时,还是会输出10,因为已经通过值捕获对类进行了成员变量的初始化,后期再输出的时候,不会重新捕获变量,而是使用之前初始化时候的值。文章来源地址https://www.toymoban.com/news/detail-701955.html
到了这里,关于面试问题回忆的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[1Panel]开源,现代化,新一代的 Linux 服务器运维管理面板](https://imgs.yssmx.com/Uploads/2024/02/722869-1.png)