初学python爬虫学习笔记——爬取网页中小说标题
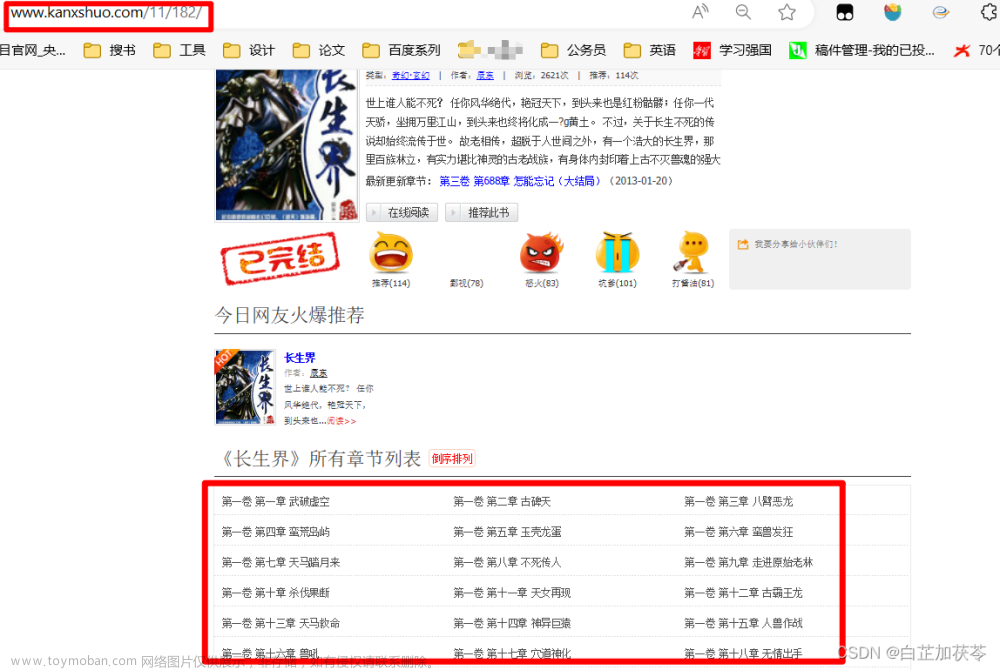
一、要爬取的网站小说如下图
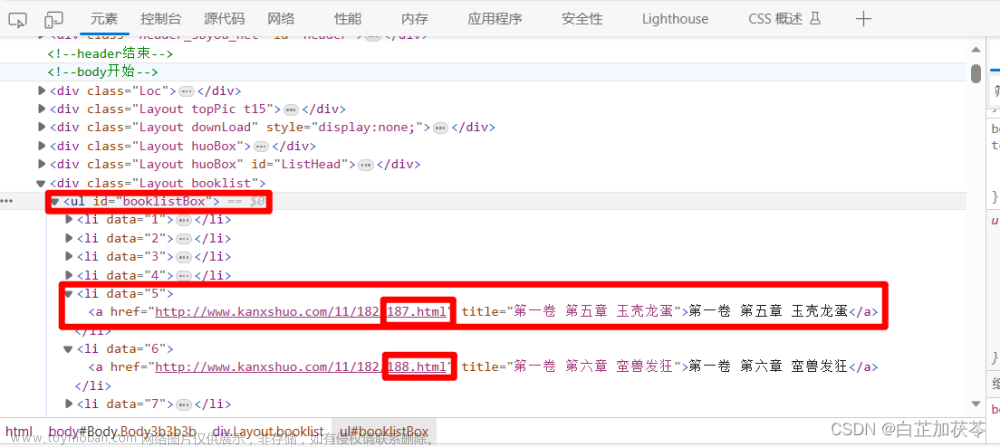
二、打开网页的“检查”,查看html页面
发现每个标题是列表下的一个个超链接,从183.html到869.html
可以使用for循环依次得到:
x = range(183,600)
for i in x:
print(soup.find('a', href="http://www.kanxshuo.com/11/182/"+str(i)+".html").get_text())
 文章来源:https://www.toymoban.com/news/detail-702007.html
文章来源:https://www.toymoban.com/news/detail-702007.html
三、具体代码如下:
import requests
import random
from bs4 import BeautifulSoup
# 要爬取的网站
url = "http://www.kanxshuo.com/11/182/"
# 发出访问请求,获得对应网页
response = requests.get(url)
print(response)
# 将获得的页面解析内容写入soup备用
soup = BeautifulSoup(response.content, 'lxml')
# 解析网站数据
# print(soup)
# 根据目标,首先要获得小说的标题和章节标题
# <a href="http://www.kanxshuo.com/11/182/211.html" title="第一卷 第二十九章 神祗遗闻">第一卷 第二十九章 神祗遗闻</a>
t1 = soup.find('a', href="http://www.kanxshuo.com/11/182/").get_text()
t2 = soup.find(id='booklistBox')
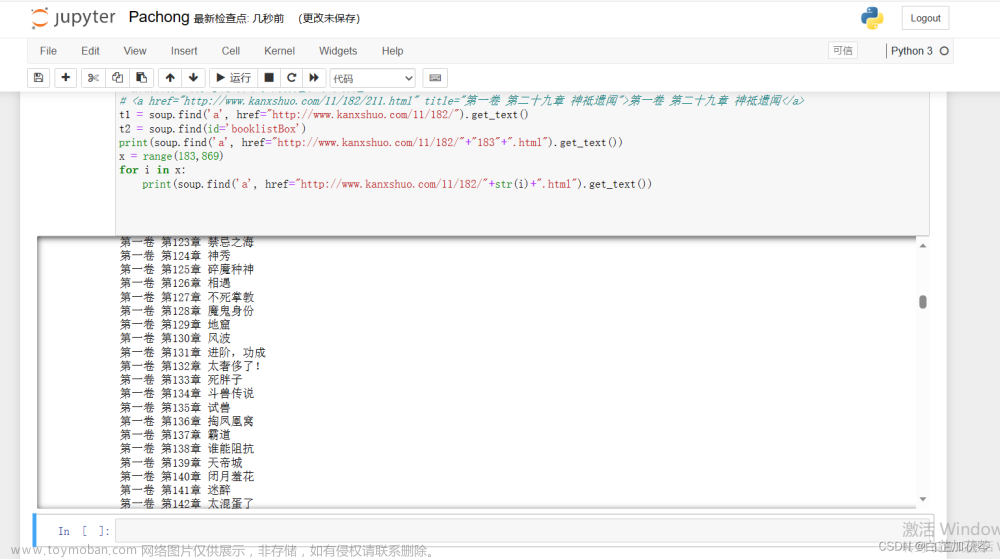
print(soup.find('a', href="http://www.kanxshuo.com/11/182/"+"183"+".html").get_text())
x = range(183,600)
for i in x:
print(soup.find('a', href="http://www.kanxshuo.com/11/182/"+str(i)+".html").get_text())
第一次学习爬虫,能得出查询结果,心中还是无限的高兴。
不过,还是发现的很多,比如for循环的多种使用掌握不熟练,soup.find()和soup.find_all()的使用存在较多问题。文章来源地址https://www.toymoban.com/news/detail-702007.html
到了这里,关于初学python爬虫学习笔记——爬取网页中小说标题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频](https://imgs.yssmx.com/Uploads/2024/04/855397-1.png)

![第一个Python程序_获取网页 HTML 信息[Python爬虫学习笔记]](https://imgs.yssmx.com/Uploads/2024/01/797744-1.png)