参考书籍:https://zh-v2.d2l.ai/chapter_recurrent-modern/lstm.html
参考论文: https://colah.github.io/posts/2015-08-Understanding-LSTMs/
简介:
LSTM(长短期记忆网络)和GRU(门控循环单元)是两种常用的改进型循环神经网络(RNN),用于解决传统RNN中的长期依赖性和梯度消失/梯度爆炸等问题。
LSTM和GRU都通过引入门控机制和记忆单元来增强RNN的建模能力,并有效地捕捉长期依赖性。它们具有类似的结构,但在门控机制的设计和计算复杂度上有所不同。
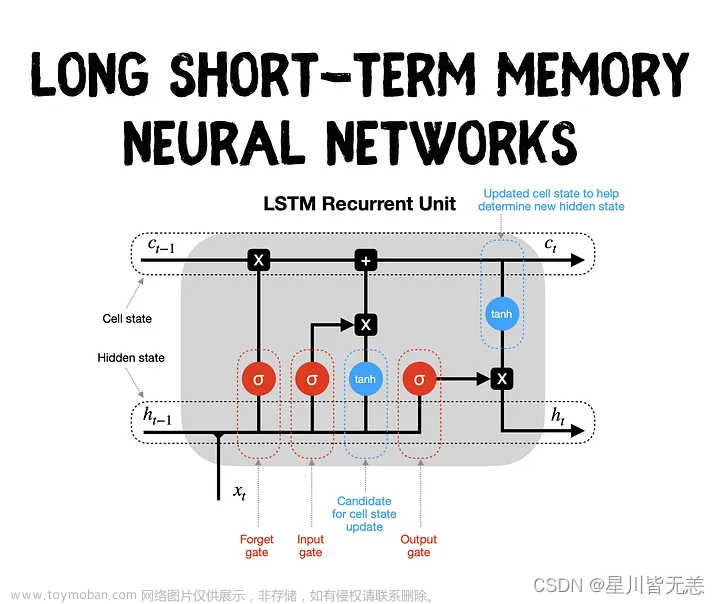
一.LSTM长短期记忆网络(long short-term memory)
LSTM(Long Short-Term Memory)是一种常用的循环神经网络(RNN)变体,旨在解决传统RNN在处理长期依赖性时容易出现的梯度消失或梯度爆炸问题。LSTM通过引入门控机制,有效地捕捉和记忆时间序列数据中的长期依赖关系。




LSTM的核心思想是使用称为"门"的结构来控制信息的流动和记忆的更新。下面是LSTM的主要组成部分
- 输入门(Input Gate):输入门决定哪些信息将被传递到细胞状态(Cell State)。它使用一个Sigmoid激活函数来控制输入的权重,以及一个tanh激活函数来处理输入的值。输入门的计算公式如下:
i_t = sigmoid(W_i * x_t + U_i * h_(t-1) + b_i) ``` ```` g_t = tanh(W_g * x_t + U_g * h_(t-1) + b_g) ```` -
遗忘门(Forget Gate):遗忘门决定元状态中哪些信息应该被遗忘。它通过一个Sigmoid激活函数来控制元状态中的旧信息的权重。遗忘门的计算公式如下:
f_t = sigmoid(W_f * x_t + U_f * h_(t-1) + b_f) -
元状态更新(Cell State Update):元状态通过将输入门和遗忘门的结果相乘,并添加新的候选值(由tanh激活函数计算得到)来更新。元状态更新的计算公式如下:
C_t = f_t * C_(t-1) + i_t * g_t -
输出门(Output Gate):输出门决定从元状态中输出的值。它使用一个Sigmoid激活函数来控制输出的权重,并使用tanh激活函数处理元状态。输出门的计算公式如下:
o_t = sigmoid(W_o * x_t + U_o * h_(t-1) + b_o)h_t = o_t * tanh(C_t)
在上述公式中,x_t表示当前时间步骤的输入,h_(t-1)表示上一个时间步骤的隐藏状态,i_t、f_t、o_t分别表示输入门、遗忘门和输出门的输出,g_t表示候选值,C_t表示元状态,h_t表示当前时间步骤的隐藏状态。
通过使用输入门、遗忘门和输出门,LSTM能够控制信息流动和记忆的更新,有效地捕捉和处理时间序列数据中的长期依赖关系。这使得LSTM在许多任务中表现出色,如语言模型、机器翻译、语音识别等。
二.GRU(Gate Recurrent Unit)门控循环单元
参考链接:人人都能看懂的GRU - 知乎
GRU(Gate Recurrent Unit)是循环神经网络(Recurrent Neural Network, RNN)的一种。和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。
GRU和LSTM在很多情况下实际表现上相差无几,那么为什么我们要使用新人GRU(2014年提出)而不是相对经受了更多考验的LSTM(1997提出)呢。
下图1-1引用论文中的一段话来说明GRU的优势所在。

简单译文:我们在我们的实验中选择GRU是因为它的实验效果与LSTM相似,但是更易于计算。
相比LSTM,使用GRU能够达到相当的效果,并且相比之下更容易进行训练,能够很大程度上提高训练效率,因此很多时候会更倾向于使用GRU。
OK,那么为什么说GRU更容易进行训练呢,下面开始介绍一下GRU的内部结构。
2.1GRU的输入和输出结构


2.2GRU的内部结构



 文章来源:https://www.toymoban.com/news/detail-702012.html
文章来源:https://www.toymoban.com/news/detail-702012.html
 文章来源地址https://www.toymoban.com/news/detail-702012.html
文章来源地址https://www.toymoban.com/news/detail-702012.html
到了这里,关于pytorch学习——LSTM和GRU的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!