目录
一、HDFS 架构整体概述
二、HDFS 集群角色介绍
2.1 整体概述
2.2 主角色:namenode
2.3 从角色:datanode
2.4 主角色辅助角色: secondarynamenode
三、HDFS 重要特性
3.1 主从架构
3.2 分块存储机制
3.3 副本机制
3.4 namespace
3.5 元数据管理
3.6 数据块存储
一、HDFS 架构整体概述
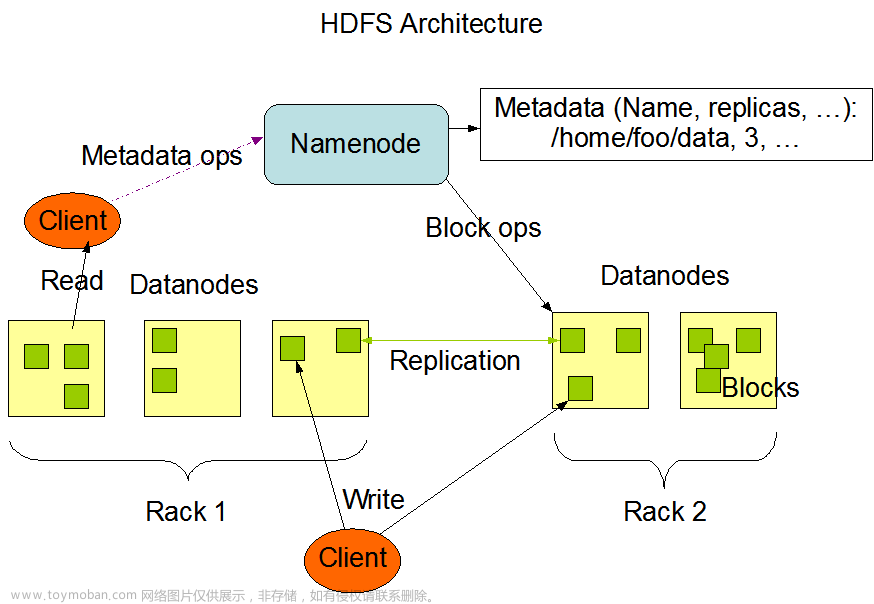
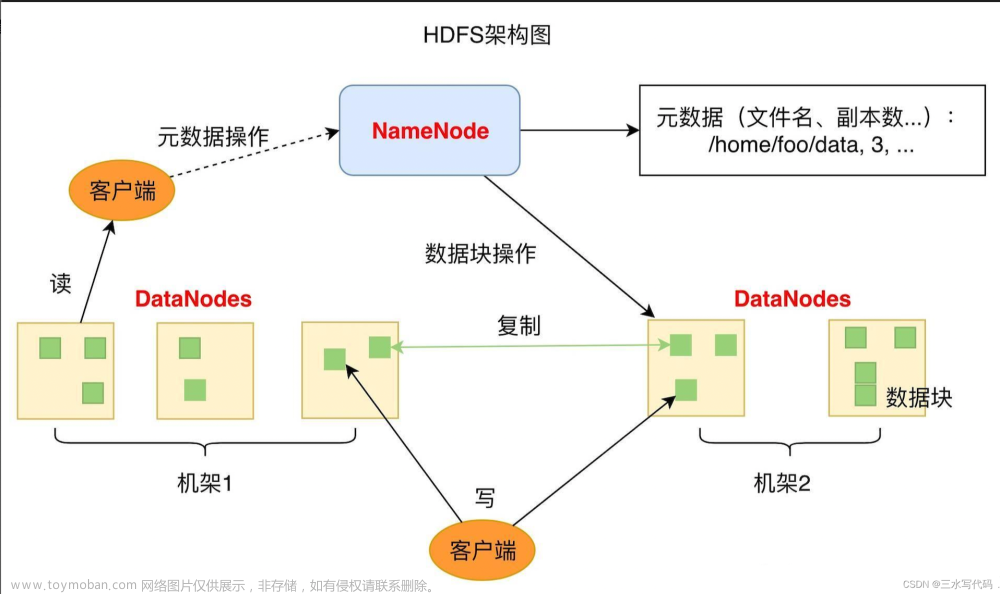
HDFS 是 Hadoop Distribute File System 的简称,意为:Hadoop 分布式文件系统。HDFS 是Hadoop 核心组件之一,作为大数据生态圈最底层的分布式存储服务而存在。HDFS 解决的问题就是大数据如何存储,它是横跨在多台计算机上的文件存储系统并且具有高度的容错能力。
 HDFS 集群遵循主从架构(master/slave)。通常包括一个主节点和多个从节点。在内部,文件分块存储,每个块根据复制因子存储在不同的从节点计算机上形成备份。主节点存储和管理文件系统 namespace,即有关文件块的信息,例如块位置,权限等;从节点存储文件的数据块。主从各司其职,互相配合,共同对外提供分布式文件存储服务。当然内部细节对于用户来说是透明的。
HDFS 集群遵循主从架构(master/slave)。通常包括一个主节点和多个从节点。在内部,文件分块存储,每个块根据复制因子存储在不同的从节点计算机上形成备份。主节点存储和管理文件系统 namespace,即有关文件块的信息,例如块位置,权限等;从节点存储文件的数据块。主从各司其职,互相配合,共同对外提供分布式文件存储服务。当然内部细节对于用户来说是透明的。

二、HDFS 集群角色介绍
2.1 整体概述
HDFS 遵循主从架构。NameNode 是主节点,负责存储和管理文件系统元数据信息,包括 namespace 目录结构、文件块位置信息等; DataNode 是从节点,负责存储文件具体的数据块。两种角色各司其职,共同协调完成分布式的文件存储服务。SecondaryNameNode 是主角色的辅助角色,帮助主角色进行元数据的合并。

2.2 主角色:namenode
NameNode 是 Hadoop 分布式文件系统的核心,架构中的主角色。NameNode 维护和管理文件系统元数据,包括名称空间目录树结构、文件和块的位置信息、访问权限等信息。基于此,NameNode 成为了访问 HDFS 的唯一入口。
NameNode 内部通过内存和磁盘文件两种方式管理元数据。其中磁盘上的元数据文件包括Fsimage 内存元数据镜像文件和 edits log(Journal)编辑日志。在 Hadoop2 之前,NameNode 是单点故障。Hadoop 2 中引入的高可用性。Hadoop 群集体系结构允许在群集中以热备配置运行两个或多个 NameNode。

2.3 从角色:datanode
DataNode 是 Hadoop HDFS 中的从角色,负责具体的数据块存储。DataNode 数量决定了HDFS 集群的整体数据存储能力。通过和 NameNode 配合维护着数据块。

2.4 主角色辅助角色: secondarynamenode
除了 DataNode 和 NameNode 之外,还有另一个守护进程,它称为 secondary NameNode。充当 NameNode 的辅助节点,但不能替代 NameNode。
当 NameNode 启动时,NameNode 合并 Fsimage 和 edits log 文件以还原当前文件系统名称空间。如果 edits log 过大不利于加载,Secondary NameNode 就辅助 NameNode 从NameNode 下载 Fsimage 文件和 edits log 文件进行合并。

三、HDFS 重要特性
3.1 主从架构
HDFS 采用 master/slave 架构。一般一个 HDFS 集群是有一个 Namenode 和一定数目的 Datanode 组成。Namenode 是 HDFS 主节点,Datanode 是 HDFS 从节点,两种角色各司其职,共同协调完成分布式的文件存储服务。

3.2 分块存储机制
HDFS 中的文件在物理上是分块存储(block)的,块的大小可以通过配置参数来规定,参数位于 hdfs-default.xml 中:dfs.blocksize。默认大小是 128M(134217728)。

3.3 副本机制
文件的所有 block 都会有副本。每个文件的 block 大小(dfs.blocksize)和副本系数(dfs.replication)都是可配置的。副本系数可以在文件创建的时候指定,也可以在之后通过命令改变。
默认 dfs.replication 的值是 3,也就是会额外再复制 2 份,连同本身总共 3 份副本。

3.4 namespace
HDFS 支持传统的层次型文件组织结构。用户可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。
Namenode 负责维护文件系统的 namespace 名称空间,任何对文件系统名称空间或属性的修改都将被 Namenode 记录下来。
HDFS 会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data。

3.5 元数据管理
在HDFS中,Namenode 管理的元数据具有两种类型:
- 文件自身属性信息
文件名称、权限,修改时间,文件大小,复制因子,数据块大小。
- 文件块位置映射信息
记录文件块和 DataNode 之间的映射信息,即哪个块位于哪个节点上。

3.6 数据块存储
文件的各个 block 的具体存储管理由 DataNode 节点承担。每一个 block 都可以在多个 DataNode 上存储。
 文章来源:https://www.toymoban.com/news/detail-702059.html
文章来源:https://www.toymoban.com/news/detail-702059.html
下一篇文章:Hadoop 3.2.4 集群搭建详细图文教程_Stars.Sky的博客-CSDN博客文章来源地址https://www.toymoban.com/news/detail-702059.html
到了这里,关于HDFS 架构剖析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!