一、背景
1.1 物理机时代、虚拟机时代、容器化时代
在介绍K8S之前,先来看看服务器的演变过程:物理机时代、虚拟机时代、容器化时代。
物理机时代的缺点:
- 部署慢 :每台服务器都要安装操作系统、相关的应用程序所需要的环境,各种配置
- 成本高:物理服务器的价格十分昂贵
- 资源浪费:硬件资源不能充分利用
- 扩展和迁移成本高:扩展和迁移需要重新配置一模一样的环境

虚拟机时代很好的解决了物理机时代的缺点,虚拟机时代的特点是:
- 易部署:每台物理机可部署多台虚拟机,且可以通过模板,部署快,成本低
- 资源池:开出来的虚拟机可作为资源池备用,充分压榨服务器性能
- 资源隔离:每个虚拟机都有独立分配的内存磁盘等硬件资源,虚拟机之间不会互相影响
- 易扩展:随时都能在一个物理机上创建或销毁虚拟机
虚拟机的缺点是:每台虚拟机都需要安装操作系统

容器化时代解决了虚拟机时代的缺点,容器化时代在继承了虚拟机时代优点的基础之上,还有以下优势:
- 更高效的利用硬件资源:所有容器共享主机操作系统内核,不需要安装操作系统。
- 一致的运行环境:相同的镜像产生相同的行为
- 更小:较虚拟机而言,容器镜像更小,因为不需要打包操作系统
- 更快:容器能达到秒级启动,其本质是主机上的一个进程

1.2 容器编排的需要
容器技术的代表就是docker,docker在单机上使用方便快捷,但在集群中表现如何呢?假设现在有5个节点,每个节点中都装有docker,现在要部署一个应用,要求要10个副本,有如下做法:
- 在5个节点上随机分配
- 平均分配,每台节点分配2个
- 根据不同节点的负载状态分配,负载低的优先分配
无论选择哪种方法都需要执行相同docker run命令10遍,如果是最后一种做法还需要挨个检查每个节点的负载,这种问题叫做不利于自动装箱。
如果以后增加了1个副本还需要再重复上面的动作,如果增加10个呢?增加100个呢?人为去操作那就有点难受了,这种问题叫做不利于水平扩容与缩容,简称水平扩缩。
如果现在要变更版本,更新或者回滚,需要停止容器,然后替换新版本镜像,再启动,这样的操作每个副本都要来一次,如果副本太多,简直是噩梦,这种问题叫做不利于自动化上线和回滚。
如果现在一个容器停止运行了,docker的重启策略会将它拉起来继续运行,这没什么问题,如果节点宕机了呢?上面的所有容器都停止了,docker重启策略就没用了,这样副本的数量就会减少,这个问题叫做不能自我修复。
假设需要负载均衡,那么得新增一个节点安装负载均衡器,并且配置5个节点的IP和端口,前提是容器的端口要映射到主机端口,而且容器之前网络是隔离的,不能相互访问,维护成本高,这个问题叫不利于服务发现与负载均衡。
上面的这些操作,就是容器编排,既然存在如上问题,那么就需要一个技术进行自动化编排,这个技术就是K8S,K8S即kubernetes /kjubɚ’nɛtɪs/
Kubernetes,是一个工业级的容器编排平台。Kubernetes 这个单词是希腊语,它的中文翻译是“舵手”或者“飞行员”。在一些常见的资料中也会看到“ks”这个词,也就是“K8s”,它是通过将 8 个字母“ubernete ”替换为“8”而成为的一个缩写。
K8S官网:https://kubernetes.io/zh-cn/
根据官网描述,它有如下功能:
二、K8S架构
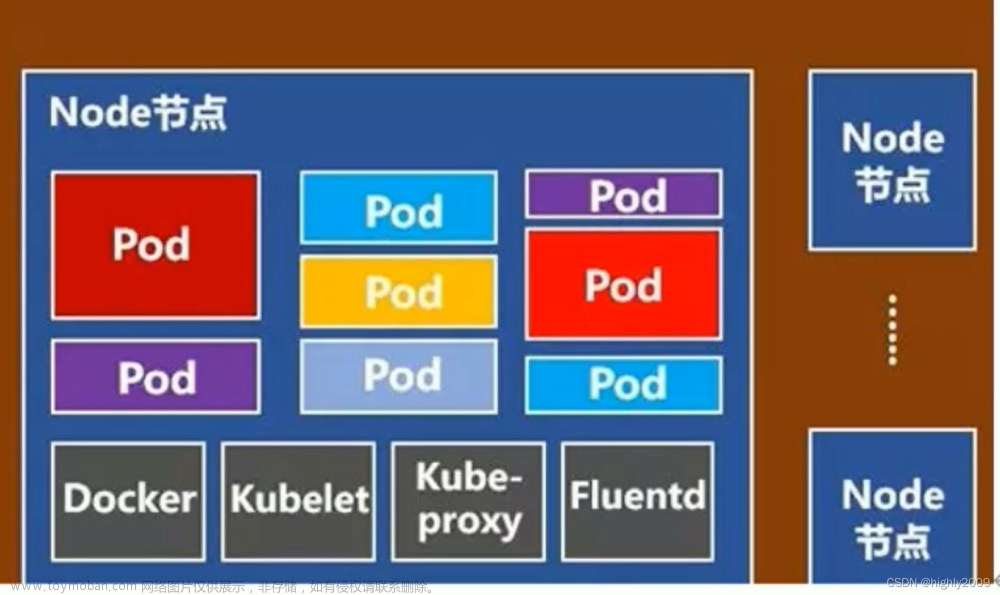
在K8S中,由Master控制节点和Worker节点共同构成一个集群,总体架构如下图所示:


- etcd:分布式KV数据库,使用Raft协议,用于保存集群中的相关数据,项目地址:https://github.com/etcd-io/etcd
- API Server:集群统一入口,以restful风格进行操作,同时交给etcd存储(是唯一能访问etcd的组件);提供认证、授权、访问控制、API注册和发现等机制,可以通过kubectl命令行工具,dashboard可视化面板,或者sdk等访问。
- Scheduler:节点的调度,选择node节点应用部署。
- Controller Manager:处理集群中常规后台任务,一个资源对应一个控制器,同时监控集群的状态,确保实际状态和最终状态一致。
2.2 Worker节点

- kubelet:相当于Master派到node节点代表,管理本机容器,上报数据给API Server
- Container Runtime:容器运行时,K8S支持多个容器运行环境:Docker、Containerd、CRI-O、Rktlet以及任何实现- Kubernetes CRI (容器运行环境接口) 的软件
- kube-proxy:实现服务(Service)抽象组件,屏蔽PodIP的变化和负载均衡
三、核心概念
3.1 Pod
- Pod是最小调度单元
- Pod里面会包含一个或多个容器(Container)
- Pod内的容器共享存储及网络,可通过localhost通信

Pod本意是豌豆荚的意思,此处指的是K8S中资源调度的最小单位,豌豆荚里面的小豆子就像是Container,豌豆荚本身就像是一个Pod。
3.2 Deployment
Deployment 是在 Pod 这个抽象上更为上层的一个抽象,它可以定义一组 Pod 的副本数目、以及这个 Pod 的版本。一般大家用 Deployment 这个抽象来做应用的真正的管理,而 Pod 是组成 Deployment 最小的单元。
- 定义一组Pod的副本数量,版本等
- 通过控制器维护Pod的数目
- 自动恢复失败的Pod
- 通过控制器以指定的策略控制版本

3.3 Service
Pod是不稳定的,IP是会变化的,所以需要一层抽象来屏蔽这种变化,这层抽象叫做Service
- 提供访问一个或者多个Pod实例稳定的访问地址
- 支持多种访问方式ClusterIP(对集群内部访问)NodePort(对集群外部访问)LoadBalancer(集群外部负载均衡)

3.4 Volume
Volume就是存储卷,在Pod中可以声明卷来问访问文件系统,同时Volume也是一个抽象层,其具体的后端存储可以是本地存储、NFS网络存储、云存储(阿里云盘、AWS云盘、Google云盘等)、分布式存储(比如说像 ceph、GlusterFS )
- 声明在Pod中容器可以访问的文件系统
- 可以被挂载在Pod中一个或多个容器的指定路径下
- 支持多种后端储存

3.5 Namespace
Namespace(命令空间)是用来做资源的逻辑隔离的,比如上面的Pod、Deployment、Service都属于资源,不同Namespace下资源可以重名。同一Namespace下资源名需唯一
- 一个集群内部的逻辑隔离机制(鉴权、资源等)
- 每个资源都属于一个Namespace
- 同一个Namespace中资源命名唯一
- 不同Namespace中资源可重名

四、K8S安装
具体的安装教程可以参考:https://kuboard.cn/install/install-k8s.html
里面写的很详细了,此处不再赘述,简化过程如下
- 创建虚拟机,2个或者2个以上
- 操作系统为 CentOS 7.8 或者 CentOS Stream 8
- 每个节点CPU 内核数量大于等于 2,且内存大于等于 4G(实测2G也可以)
- 修改网络配置文件:/etc/sysconfig/network-scripts/ifcfg-ens33 改成固定IP
- 安装containerd/kubelet/kubeadm/kubectl,注意教程中使用的容器运行时为containerd,如果需要使用docker,可以先安装docker然后跳过脚本中安装containerd的部分
- 初始化-master-节点
- 初始化-worker节点
- 验证:在Master节点上执行kubectl get nodes -o wide,能看到添加的worker节点即安装成功
我的环境情况如下:
NAME STATUS ROLES AGE VERSION INTERNAL-IP
my-master Ready control-plane,master 27h v1.21.0 192.168.108.101
my-node Ready <none> 27h v1.21.0 192.168.108.102
192.168.108.101是Master角色,名字为my-master;192.168.108.102是Worker角色,名字为my-node
五、kubectl常用命令
kubectl 则是 Kubernetes 的命令行工具,用于管理 Kubernetes 集群。
kubectl controls the Kubernetes cluster manager.
意为K8S集群管理的控制器,kubectl --help可以打印帮助命令。
(1)查看集群信息:
kubectl cluster-info # 显示集群信息。
(2)查看资源状态:
kubectl get pods # 查看所有Pod的状态
kubectl get deployments # 查看所有部署的状态
kubectl get services # 查看所有服务的状态
kubectl get nodes # 查看所有节点的状态
kubectl get namespaces # 查看所有命名空间的状态
kubectl describe pod <pod-name> # 显示特定Pod的详细信息
kubectl describe node <node-IP/name> # 显示特定Node的详细信息
(3)创建和管理资源:
kubectl create -f <filename> # 根据YAML文件创建资源
kubectl apply -f <filename> # 根据YAML文件创建或更新资源
kubectl delete -f <filename> # 根据YAML文件删除资源
kubectl scale deployment <deployment-name> --replicas=<replica-count> # 扩展或缩减部署的副本数
kubectl expose deployment <deployment-name> --port=<port> --type=<service-type> # 创建一个服务来公开部署
(4)执行操作:
kubectl exec -it <pod-name> -- <command> # 在Pod中执行特定命令
kubectl logs <pod-name> # 查看Pod的日志
kubectl port-forward <pod-name> <local-port>:<pod-port> # 将本地端口与Pod的端口进行转发
(5)删除资源:
kubectl delete deployment <deployment-name> # 删除部署
kubectl delete pod <pod-name> # 删除Pod
kubectl delete service <service-name> # 删除服务
六、K8S实战
6.1 水平扩容
为什么先实战水平扩容?因为这个最简单,首先来部署一个喜闻乐见的nginx
kubectl create deployment web --image=nginx:1.14
这句话表示创建一个资源,啥资源呢?是一个deployment(可以简写为deploy),取名叫web,指定了镜像为nginx的1.14版本,但是先别执行这句话,我们一般不这么部署应用,因为不好复用,一般通过yaml文件来部署,如下:
kubectl create deployment web --image=nginx:1.14 --dry-run -o yaml > web.yaml
- –dry-run表示试运行,试一下看行不行,但是不运行
- -o yaml表示以yaml格式输出
- web.yaml表示将输出的内容重定向到web.yaml文件中
执行之后看看web.yaml文件里面有些什么:
apiVersion: apps/v1 # 表示资源版本号为apps/v1
kind: Deployment # 表示这是一个Deployment
metadata: # 一些元数据信息
creationTimestamp: null
labels: # 标签,可以随便定义
app: web
name: web # 这个资源的名字
spec: # 资源的描述或者规格
replicas: 1 # 副本数量
selector: # 选择器
matchLabels: # 需要匹配的标签
app: web # 标签的具体键值对
strategy: {}
template: # 模板。表示Pod的生成规则
metadata:
creationTimestamp: null
labels:
app: web
spec:
containers:
- image: nginx:1.14 #指定镜像文件
name: nginx
resources: {}
status: {}
用下面的命令应用web.yaml,web.yaml声明了一个Deployment和一个Pod
kubectl apply -f web.yaml
执行完后以后可以通过以下命令查看Deployment和Pod:
kubectl get deploy,po -o wide
结果如下:
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
deployment.apps/web 1/1 1 1 2m40s nginx nginx:1.14 app=web
NAME READY STATUS RESTARTS AGE IP NODE ...
pod/web-5bb6fd4c98-lg555 1/1 Running 0 2m40s 10.100.255.120 my-node ...
可以看到资源已经建立起来了,运行在Worker节点中,尝试访问一下Pod的IP:
curl 10.100.255.120
有如下nginx的标准返回说明应用已经部署完毕:
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...
</html>
有没有感觉这一路下来挺麻烦的,yaml文件还那么长,还不如无脑docker run呢,别急,在后面扩缩容的时候就可以看到它的威力了,当然也可以用最开始的命令来执行kubectl create deployment web --image=nginx:1.14,测试可以,在生产环境中强烈不建议这么做。
【扩容实战】:假设现在扩容需求来了,需要部署同样的nginx副本10个,该怎么做?在K8S中很简单,直接告诉K8S我要10个副本即可,其他的细节不用关心。
具体的做法是修改上面的web.yaml文件,将replicas: 1声明成replicas: 10,最后再应用一下
kubectl apply -f web.yaml
此时快速的执行kubectl get po,可以看到一些容器已经开始运行了,一些在创建中,一些还在挂起:
NAME READY STATUS RESTARTS AGE
pod/web-5bb6fd4c98-52qmf 0/1 ContainerCreating 0 1s
pod/web-5bb6fd4c98-5sp5l 0/1 Pending 0 1s
pod/web-5bb6fd4c98-9t2hm 0/1 ContainerCreating 0 1s
pod/web-5bb6fd4c98-lg555 1/1 Running 0 11m
...
稍等片刻可以看到所有Pod都是Running状态了!当然也可以偷懒一键扩容:
kubectl scale deploy web --replicas=10
6.2 自动装箱
根据资源需求和其他约束自动放置容器,同时避免影响可用性。将关键性工作负载和尽力而为性质的服务工作负载进行混合放置,以提高资源利用率并节省更多资源。
K8S支持多种策略,包括:节点污点、节点标签、Pod调度策略等。目的是提供最大的灵活性,最终提高整体资源利用率,这就是自动装箱。
6.2.1 节点污点
Taint 污点:节点不做普通分配调度,是节点属性,属性值有三个
- NoSchedule:一定不被调度
- PreferNoSchedule:尽量不被调度(也有被调度的几率)
- NoExecute:不会调度,并且还会驱逐Node已有Pod
也就是说,给节点打上污点,那么调度的时候就会根据上面的属性来进行调度,一般来说Master节点的污点值是NoSchedule,查看Master污点值
kubectl describe node my-master | grep Taints
可以看到如下输出
Taints: node-role.kubernetes.io/master:NoSchedule
6.2.2 Pod调度策略
Pod调度策略会影响到Pod最终被调度到哪个节点上,Pod调度策略有三类
- Pod声明的requests和limits,前者就是Pod需要多少资源,后者表示Pod最多用多少资源,资源比如CPU内存等
- 节点标签选择器,会选择符合标签的节点进行调度
- 节点亲和性,分为硬亲和和软亲和,前者必须满足,后者尝试满足,不强制
6.3 Secret
Secret意为秘密,那在K8S中是啥意思呢?在K8S中表示一个存储在etcd中的配置,这个配置是秘密的,是安全的,通常用Base64编码,此配置可以通过挂载卷或者环境变量的方式供Pod访问,首先定义一个Secret:
# 首先将明文转换成base64编码
echo -n 'root' | base64 # 结果是cm9vdA==
echo -n '123456' | base64 # 结果是MTIzNDU2
通过下面的secret.yaml声明创建一个Secret,通过kubectl get secret可以查看刚才创建的Secret:
apiVersion: v1
kind: Secret
metadata:
name: test-secret
data:
username: cm9vdA==
password: MTIzNDU2
6.3.1 挂载卷的方式
声明文件如下:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
spec:
replicas: 1
selector:
matchLabels:
app: web
strategy: {}
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx:1.14
name: nginx
# 挂载到容器内
volumeMounts:
- name: secret-volume
mountPath: /etc/secret-volume
# 卷声明
volumes:
- name: secret-volume
secret:
secretName: test-secret
status: {}
创建之后进入容器,下面是进入容器命令,和docker一致,你创建出来的Pod不一定是这个名web-66d9b4684b-dvwtm,根据实际情况进入:
kubectl exec -it web-66d9b4684b-dvwtm bash
查看一下挂载的内容:
cat /etc/secret-volume/username # 显示root
cat /etc/secret-volume/password # 显示123456
6.3.2 环境变量的方式
声明文件如下:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
spec:
replicas: 1
selector:
matchLabels:
app: web
strategy: {}
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx:1.14
name: nginx
# 环境变量声明
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: test-secret
key: username
status: {}
执行后再容器内部查看该环境变量是否符合预期值,打印出来的值应该是root,即我们设置的Secret
kubectl exec -it web-848bb777bc-x5mh4 -- /bin/sh -c 'echo $SECRET_USERNAME'
这里有一个疑问,既然是Base64的编码方式(不是加密方式),为什么说Secret是安全的呢?此处的安全是K8S提供的,主要是以前几点:
- 传输安全(K8S中与API Server的交互都是HTTPS的)
- 存储安全(Secret被挂载到容器时存储在tmpfs中,只存在于内存中而不是磁盘中,Pod销毁Secret随之消失)
- 访问安全(Pod间的Secret是隔离的,一个Pod不能访问另一个Pod的Secret)
6.4 ConfigMap
ConfigMap可以看做是不需要加密,不需要安全属性的Secret,也是和配置相关的,创建ConfigMap的过程如下,首先创建一个配置文件,比如redis.properties,包含如下内容
redis.port=127.0.0.1
redis.port=6379
redis.password=123456
以下命令从文件redis.properties创建了一个名为redis-config的ConfigMap
kubectl create configmap redis-config --from-file=redis.properties
使用命令kubectl get configmap可以查看刚才创建的ConfigMap,当然ConfigMap也有挂载卷和设置环境变量的方式供Pod调用,此处不再赘述。
6.5 存储编排
存储编排可实现自动挂载所选存储系统,包括本地存储、诸如 GCP 或 AWS 之类公有云提供商所提供的存储或者诸如 NFS、iSCSI、Gluster、Ceph、Cinder 或 Flocker 这类网络存储系统。
提到存储就不得不说K8S中的PV和PVC了,解释如下:
- PV:PersistentVolume,持久化卷
- PVC:PersistentVolumeClaim,持久化卷声明
PV说白了就是一层存储的抽象,底层的存储可以是本地磁盘,也可以是网络磁盘比如NFS、Ceph之类,既然有了PV那为什么又要搞一个PVC呢?
PVC其实在Pod和PV之前又增加了一层抽象,这样做的目的在于将Pod的存储行为于具体的存储设备解耦,试想一下,假设哪天NFS网络存储的IP地址变化了,如果没有PVC,就需要每个Pod都改一下IP的声明,那得多累,有PVC来屏蔽这些细节之后只用改PV即可!
6.6 服务发现与负载均衡
服务发现与负载均衡可实现:无需修改你的应用程序即可使用陌生的服务发现机制。Kubernetes 为容器提供了自己的 IP 地址和一个 DNS 名称,并且可以在它们之间实现负载均衡。
到目前为止,我们的Pod已经可以实现水平扩缩、自动装箱、配置管理、存储编排了,但是访问还是个大问题,扩容后这么多Pod应该访问哪一个?如果能够自动将流量分配到不同的Pod上(负载均衡);并且当扩容或者缩容的时候能够动态的将Pod添加或者剔除出负载均衡的范围,简而言之就是服务发现。
那么在K8S中有没有东西可以做到服务发现和负载均衡呢?答案是有,这就是Service(还记得前面提到过的核心概念吗),Service有三种类型:
- ClusterIp:集群内部访问(默认)
- NodePort:集群外部访问(包含了ClusterIp)
- LoadBalancer:对外访问应用使用,公有云
6.7 自我修复
自我修复可实现:重新启动失败的容器,在节点死亡时替换并重新调度容器,杀死不响应用户定义的健康检查的容器,并且在它们准备好服务之前不会将它们公布给客户端。
6.7.1 Pod重启机制
当Pod异常停止时,就会触发Pod的重启机制,根据重启策略会表现出不同的行为。
重启策略主要分为以下三种
- Always:当容器终止退出后,总是重启容器,默认策略
- OnFailure:当容器异常退出(退出状态码非0)时,才重启
- Never:当容器终止退出,从不重启容器
6.7.2 Pod健康检查
健康检查顾名思义就是检查Pod是否健康,怎么来定义健康呢?假设这么一种情况,当程序内部发生了错误已经不能对外提供服务了,但此时主程序仍在运行,这种情况就是不健康的,或者当容器主进程已经启动了,但是服务还没有准备好,这种情况也是不健康的,这就需要从应用层面来检查,K8S中定义了两种检查机制
- livenessProbe:存活检查,如果检查失败,将杀死容器,根据Pod的restartPolicy来操作
- readinessProbe:就绪检查,如果检查失败,Kubernetes会把Pod从Service endpoints中剔除,也就是让客户流量不打到readinessProbe检查失败的Pod上
具体的检查方式支持三种文章来源:https://www.toymoban.com/news/detail-702099.html
- http Get:发送HTTP请求,返回200 - 400 范围状态码为成功
- exec:执行Shell命令返回状态码是0为成功
- tcpSocket:发起TCP Socket建立成功
6.8 自动化上线与回滚
Kubernetes 会分步骤地将针对应用或其配置的更改上线,同时监视应用程序运行状况以确保你不会同时终止所有实例。如果出现问题,Kubernetes 会为你回滚所作更改。你应该充分利用不断成长的部署方案生态系统。文章来源地址https://www.toymoban.com/news/detail-702099.html
参考资料
- K8S原理架构与实战(基础篇)
到了这里,关于K8S原理架构与实战教程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!