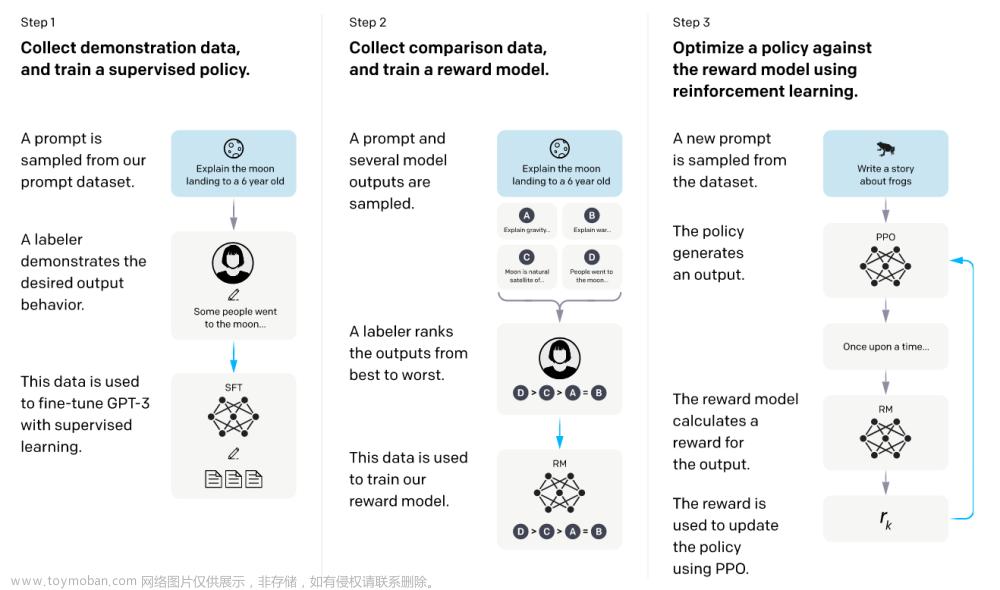
Apache HBase 为什么快?
Apache HBase 之所以快速,主要归功于其设计和实现的几个关键特性和优化。
下面是一些重要的原因:
分布式架构:HBase是一个分布式数据库,数据存储在多个节点上,可以水平扩展。这使得HBase能够处理大规模数据,并且能够通过添加更多的服务器节点来提高性能。
列式存储:HBase采用了列式存储模型,将数据按列存储在一起,而不是按行存储。这种设计使得读取特定列的数据变得非常高效,因为只需要检索所需列的数据而不必读取整行。
压缩技术:HBase支持多种压缩算法,可以有效地减小数据的存储空间,减少磁盘的IO操作,从而提高了数据的读取和写入性能。
内存缓存:HBase使用了多层次的缓存机制,包括块缓存(Block Cache)和内存缓存(MemStore)等,这些缓存可以加速数据的访问,减少了对磁盘的依赖。
快速的写入:HBase的写入操作非常高效,数据首先被写入内存中的MemStore,然后在后台异步刷写到磁盘。这种设计可以提高写入性能,同时保持数据的持久性。
分布式一致性:HBase采用了ZooKeeper来维护分布式的协调和一致性,确保数据的一致性和可靠性。
水平扩展性:HBase可以轻松地扩展到成百上千台服务器,这使得它能够处理非常大规模的数据,并且能够应对不断增长的数据量。
支持多种查询方式:HBase支持基于行键(Row Key)的快速点查和范围查询,同时还支持基于列的过滤和条件查询,这使得它非常适合大规模数据的多种查询需求。
总之,Apache HBase的快速性能得益于其分布式、列式、压缩、缓存等多种技术和设计优化,使其成为处理大规模数据的强大工具。文章来源:https://www.toymoban.com/news/detail-702688.html
但需要注意的是,HBase的性能也受到配置、硬件、数据模型等多种因素的影响,因此在实际使用中需要根据具体需求进行合适的调优和配置。文章来源地址https://www.toymoban.com/news/detail-702688.html
到了这里,关于3. Apache HBase 为什么快?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![《让云落地 云计算服务模式》第一章 [为什么是云计算,为什么是现在] 学习](https://imgs.yssmx.com/Uploads/2024/04/861311-1.png)