个人主页:金鳞踏雨
个人简介:大家好,我是金鳞,一个初出茅庐的Java小白
目前状况:22届普通本科毕业生,几经波折了,现在任职于一家国内大型知名日化公司,从事Java开发工作
我的博客:这里是CSDN,是我学习技术,总结知识的地方。希望和各位大佬交流,共同进步 ~
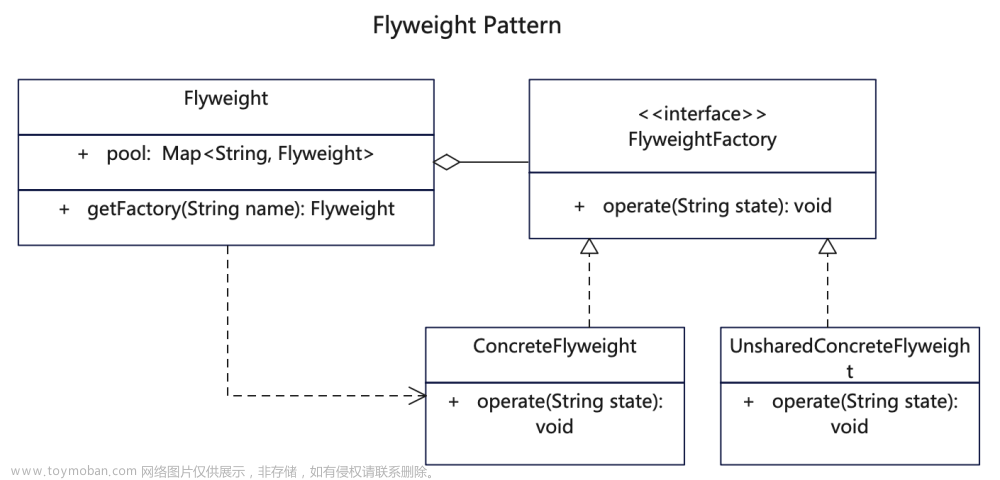
把相同、相似的一些对象和属性拿来复用,以至于节省内存;由于这些对象将会被共享,所以它们最好是不可变的(不要又set() 方法)!
主要是通过工厂模式,在工厂类中,通过一个 Map 来缓存已经创建过的享元对象,来达到复用的目的。
本篇博客来自IT楠老师的视频教程,结合个人理解后输出~
一、享元模式原理与实现
所谓“享元”,顾名思义就是被共享的单元。他也是一个不怎么常用的设计模式,享元模式的意图是复用对象,节省内存,前提是享元对象是不可变对象。
具体来讲,当一个系统中存在大量重复对象的时候,如果这些重复的对象是不可变对象,我们就可以利用享元模式将对象设计成享元,在内存中只保留一份实例,供多处代码引用。这样可以减少内存中对象的数量,起到节省内存的目的。实际上,不仅仅相同对象可以设计成享元,对于相似对象,我们也可以将这些对象中相同的部分(字段)提取出来,设计成享元,让这些大量相似对象引用这些享元。
这里定义中的“不可变对象”指的是,一旦通过构造函数初始化完成之后,它的状态(对象的成员变量或者属性)就不会再被修改了。所以,不可变对象不能暴露任何 set() 等修改内部状态的方法。之所以要求享元是不可变对象,那是因为它会被多处代码共享使用,避免一处代码对享元进行了修改,影响到其他使用它的代码。
接下来,我们通过一个简单的例子解释一下享元模式。
假设我们在开发一个棋牌游戏(比如象棋)。一个游戏厅中有成千上万个“房间”,每个房间对应一个棋局。棋局要保存每个棋子的数据,比如:棋子类型(将、相、士、炮等)、棋子颜色(红方、黑方)、棋子在棋局中的位置。利用这些数据,我们就能显示一个完整的棋盘给玩家。具体的代码如下所示。其中,ChessPiece 类表示棋子,ChessBoard 类表示一个棋局,里面保存了象棋中 30 个棋子的信息。
public class ChessPiece {//棋子
private int id;
private String text;
private Color color;
public ChessPiece(int id, String text, Color color, int positionX, int positionY) {
this.id = id;
this.text = text;
this.color = color;
this.positionX = positionX;
this.positionY = positionX;
}
public static enum Color {
RED, BLACK
}
// ...省略其他属性和getter/setter方法...
}
public class ChessBoard {//棋局
private Map<Integer, ChessPiece> chessPieces = new HashMap<>();
public ChessBoard() {
init();
}
private void init() {
chessPieces.put(1, new ChessPiece(1, "車", ChessPiece.Color.BLACK, 0, 0));
chessPieces.put(2, new ChessPiece(2,"馬", ChessPiece.Color.BLACK, 0, 1));
//...省略摆放其他棋子的代码...
}
public void move(int chessPieceId, int toPositionX, int toPositionY) {
//...省略...
}
}为了记录每个房间当前的棋局情况,我们需要给每个房间都创建一个 ChessBoard 棋局对象。因为游戏大厅中有成千上万的房间(实际上,百万人同时在线的游戏大厅也有很多),那保存这么多棋局对象就会消耗大量的内存。有没有什么办法来节省内存呢?
这个时候,享元模式就可以派上用场了。
上述案例,在内存中会有大量的相似对象。这些相似对象的 id、text、color 都是相同的,唯独 positionX、positionY 不同。实际上,我们可以将棋子的 id、text、color 属性拆分出来,设计成独立的类,并且作为享元供多个棋盘复用。这样,棋盘只需要记录每个棋子的位置信息就可以了。具体的代码实现如下所示:
// 享元类
@ToString
public class ChessUnit {
private Long id;
private String text;
private Color Color;
public ChessUnit(Long id, String text, ChessUnit.Color color) {
this.id = id;
this.text = text;
Color = color;
}
// 枚举(红、黑)
public enum Color{
RED,BLACK
}
}
// 享元工厂
public class ChessUnitFactory {
private static Map<Long,ChessUnit> chessUnitMap = new HashMap<>(64);
static {
chessUnitMap.put(1L,new ChessUnit(1L,"兵",ChessUnit.Color.RED));
chessUnitMap.put(2L,new ChessUnit(2L,"马",ChessUnit.Color.RED));
chessUnitMap.put(3L,new ChessUnit(3L,"炮",ChessUnit.Color.RED));
chessUnitMap.put(4L,new ChessUnit(4L,"将",ChessUnit.Color.RED));
chessUnitMap.put(5L,new ChessUnit(5L,"将",ChessUnit.Color.BLACK));
}
/**
* 暴露一个工厂方法,用来获取棋子
* @param id 棋子的id
* @return 棋子
*/
public static ChessUnit getChessUnit(Long id){
return chessUnitMap.get(id);
}
}
// 注意一定需要将其hashCode重写,否则它不能作为key使用(@EqualsAndHashCode)
@Data
@AllArgsConstructor
@NoArgsConstructor
@EqualsAndHashCode
public class Position {
private int positionX;
private int positionY;
}
// 棋子
@Data
@AllArgsConstructor
public class ChessPiece {
private ChessUnit chessUnit;
private Position position;
}
// 棋盘
public class ChessBoard {
// 应该持有一个套棋子(有具体的坐标)
private Map<Position, ChessPiece> chessPieceMap;
public ChessBoard() {
// 构造棋牌
this.chessPieceMap = new HashMap<>(64);
// 初始化棋牌
Position position1 = new Position(1, 2);
chessPieceMap.put(position1,new ChessPiece(ChessUnitFactory.getChessUnit(1L),position1));
Position position2 = new Position(1, 4);
chessPieceMap.put(position2,new ChessPiece(ChessUnitFactory.getChessUnit(1L),position2));
Position position3 = new Position(1, 5);
chessPieceMap.put(position3,new ChessPiece(ChessUnitFactory.getChessUnit(3L),position3));
}
public void display(){
for (Map.Entry<Position,ChessPiece> entry : chessPieceMap.entrySet()){
System.out.println(entry.getKey() + "-->" + entry.getValue());
}
}
public static void main(String[] args) {
ChessBoard chessBoard = new ChessBoard();
chessBoard.display();
}
}在上面的代码实现中,我们利用工厂类来缓存 ChessPieceUnit 信息(也就是 id、text、color)。通过工厂类获取到的 ChessPieceUnit 就是享元。所有的 ChessBoard 对象共享这 30 个 ChessPieceUnit 对象(因为象棋中只有 30 个棋子)。在使用享元模式之前,记录 1 万个棋局,我们要创建 30 万(30*1 万)个棋子的 ChessPieceUnit 对象。利用享元模式,我们只需要创建 30 个享元对象供所有棋局共享使用即可,大大节省了内存。
二、源码应用
1、享元模式在 Java Integer 中的应用
如何判定两个 Java 对象是否相等(也就代码中的“==”操作符的含义)?
什么是自动装箱(Autoboxing)和自动拆箱(Unboxing)?
Java 为基本数据类型提供了对应的包装器类型。
Integer i = 56; //自动装箱
int j = i; //自动拆箱自动装箱:就是自动将基本数据类型转换为包装器类型。
数值 56 是基本数据类型 int,当赋值给包装器类型(Integer)变量的时候,触发自动装箱操作,创建一个 Integer 类型的对象,并且赋值给变量 i。其底层相当于执行了下面这条语句
Integer i = 56;//底层执行了:Integer i = Integer.valueOf(56);自动拆箱:也就是自动将包装器类型转化为基本数据类型。
当把包装器类型的变量 i,赋值给基本数据类型变量 j 的时候,触发自动拆箱操作,将 i 中的数据取出,赋值给 j。其底层相当于执行了下面这条语句
int j = i; //底层执行了:int j = i.intValue();“==”来判定两个对象是否相等的时候,实际上是在判断两个局部变量存储的地址是否相同,换句话说,是在判断两个局部变量是否指向相同的对象。
下面的这段"神奇"的代码会输出什么???
Integer i1 = 56;
Integer i2 = 56;
Integer i3 = 129;
Integer i4 = 129;
System.out.println(i1 == i2); // true
System.out.println(i3 == i4); // false一个 true,一个 false
实际上,这正是因为 Integer 用到了享元模式来复用对象,才导致了这样的运行结果。当我们通过自动装箱,也就是调用 valueOf() 来创建 Integer 对象的时候,如果要创建的 Integer 对象的值在 -128 到 127 之间,会从 IntegerCache 类中直接返回,否则才调用 new 方法创建。
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}实际上,这里的 IntegerCache 相当于,生成享元对象的工厂类,只不过名字不叫 xxxFactory 而已。这个类是 Integer 的内部类。
private static class IntegerCache {
// 下限
static final int low = -128;
// 上限(根据配置或默认值来确定)
static final int high;
// 存储整数对象的数组
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}为什么 IntegerCache 只缓存 -128 到 127 之间的整型值呢?
在 IntegerCache 的代码实现中,当这个类被加载的时候,缓存的享元对象会被集中一次性创建好。毕竟整型值太多了,我们不可能在 IntegerCache 类中预先创建好所有的整型值,这样既占用太多内存,也使得加载 IntegerCache 类的时间过长。所以,我们只能选择缓存对于大部分应用来说最常用的整型值,也就是一个字节的大小(-128 到 127 之间的数据)。
实际上,JDK 也提供了方法来让我们可以自定义缓存的最大值,有下面两种方式。如果你通过分析应用的 JVM 内存占用情况,发现 -128 到 255 之间的数据占用的内存比较多,你就可以用如下方式,将缓存的最大值从 127 调整到 255。不过,这里注意一下,JDK 并没有提供设置最小值的方法。
//方法一:
-Djava.lang.Integer.IntegerCache.high=255
//方法二:
-XX:AutoBoxCacheMax=255现在,让我们再回到最开始的问题,因为 56 处于 -128 和 127 之间,i1 和 i2 会指向相同的享元对象,所以 i1i2 返回 true。而 129 大于 127,并不会被缓存,每次都会创建一个全新的对象,也就是说,i3 和 i4 指向不同的 Integer 对象,所以 i3i4 返回 false。
实际上,除了 Integer 类型之外,其他包装器类型,比如 Long、Short、Byte 等,也都利用了享元模式来缓存 -128 到 127 之间的数据。比如,Long 类型对应的 LongCache 享元工厂类及 valueOf() 函数代码如下所示:
private static class LongCache {
private LongCache(){}
static final Long cache[] = new Long[-(-128) + 127 + 1];
static {
for(int i = 0; i < cache.length; i++)
cache[i] = new Long(i - 128);
}
}
public static Long valueOf(long l) {
final int offset = 128;
if (l >= -128 && l <= 127) { // will cache
return LongCache.cache[(int)l + offset];
}
return new Long(l);
}在我们平时的开发中,对于下面这样三种创建整型对象的方式,我们优先使用后两种。
Integer a = new Integer(123);
Integer a = 123;
Integer a = Integer.valueOf(123);第一种创建方式并不会使用到 IntegerCache,而后面两种创建方法可以利用 IntegerCache 缓存,返回共享的对象,以达到节省内存的目的。
举一个极端一点的例子,假设程序需要创建 1 万个 -128 ~ 127 之间的 Integer 对象。使用第一种创建方式,我们需要分配 1 万个 Integer 对象的内存空间;使用后两种创建方式,我们最多只需要分配 256 个 Integer 对象的内存空间。
2、享元模式在 Java String 中的应用
刚刚我们讲了享元模式在 Java Integer 类中的应用,现在,我们再来看下,享元模式在 Java String 类中的应用。同样,我们还是先来看一段代码,你觉得这段代码输出的结果是什么呢?
String s1 = "楠老师";
String s2 = "楠老师";
String s3 = new String("楠老师");
System.out.println(s1 == s2);
System.out.println(s1 == s3);上面代码的运行结果是:一个 true,一个 false。跟 Integer 类的设计思路相似,String 类利用享元模式来复用相同的字符串常量(也就是代码中的“小争哥”)。JVM 会专门开辟一块存储区来存储字符串常量,这块存储区叫作“字符串常量池”。上面代码对应的内存存储结构如下所示:
不过,String 类的享元模式的设计,跟 Integer 类稍微有些不同。Integer 类中要共享的对象,是在类加载的时候,就集中一次性创建好的。但是,对于字符串来说,我们没法事先知道要共享哪些字符串常量,所以没办法事先创建好,只能在某个字符串常量第一次被用到的时候,存储到常量池中,当之后再用到的时候,直接引用常量池中已经存在的即可,就不需要再重新创建了。
三、享元模式和单例、缓存、池化的区别
在上面的讲解中,我们多次提到“共享”“缓存”“复用”这些字眼,那它跟单例、缓存、对象池这些概念有什么区别呢?
享元模式跟单例的区别
在单例模式中,一个类只能创建一个对象,而在享元模式中,一个类可以创建多个对象,每个对象被多处代码引用共享。
我们前面也多次提到,区别两种设计模式,不能光看代码实现,而是要看设计意图,也就是要解决的问题。尽管从代码实现上来看,享元模式和多例有很多相似之处,但从设计意图上来看,它们是完全不同的。应用享元模式是为了对象复用,节省内存,而应用多例模式是为了限制对象的个数。
享元模式跟缓存的区别
在享元模式的实现中,我们通过工厂类来“缓存”已经创建好的对象。
这里的“缓存”实际上是“存储”的意思,跟我们平时所说的“数据库缓存”“CPU 缓存”“MemCache 缓存”是两回事。我们平时所讲的缓存,主要是为了提高访问效率,而非复用。
享元模式跟对象池的区别
对象池、连接池(比如数据库连接池)、线程池等也是为了复用,那它们跟享元模式有什么区别呢?
虽然对象池、连接池、线程池、享元模式都是为了复用,但是,如果我们再细致地抠一抠“复用”这个字眼的话,对象池、连接池、线程池等池化技术中的“复用”和享元模式中的“复用”实际上是不同的概念。
- 池化技术中的“复用”可以理解为“重复使用”,主要目的是节省时间(比如从数据库池中取一个连接,不需要重新创建)。在任意时刻,每一个对象、连接、线程,并不会被多处使用,而是被一个使用者独占,当使用完成之后,放回到池中,再由其他使用者重复利用。
- 享元模式中的“复用”可以理解为“共享使用”,在整个生命周期中,都是被所有使用者共享的,主要目的是节省空间。
文章到这里就结束了,如果有什么疑问的地方,可以在评论区指出~
希望能和大佬们一起努力,诸君顶峰相见文章来源:https://www.toymoban.com/news/detail-702770.html
再次感谢各位小伙伴儿们的支持!!!文章来源地址https://www.toymoban.com/news/detail-702770.html
到了这里,关于【23种设计模式】享元模式【⭐】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!