语法解析
SemanticAnalyzer
SemanticAnalyzer是Hive中的语义分析器,负责检查Hive SQL程序的语义是否正确。SemanticAnalyzer会对Hive SQL程序进行以下检查:
检查过程
语法检查
SemanticAnalyzer会检查Hive SQL程序的语法是否正确,包括关键字、运算符、字符串、数字等。
类型检查
SemanticAnalyzer会检查Hive SQL程序中的变量、常量、表达式等的类型是否正确。
范围检查
SemanticAnalyzer会检查Hive SQL程序中的变量是否在定义的范围内使用。
约束检查
SemanticAnalyzer会检查Hive SQL程序中的约束是否满足。
SemanticAnalyzer的检查结果会记录在Hive的错误日志中。如果SemanticAnalyzer发现语义错误,则Hive SQL程序将无法执行。
原理
SemanticAnalyzer的原理如下:
- SemanticAnalyzer首先会使用ANTLR解析器来解析Hive SQL程序,生成抽象语法树 (AST)。AST是Hive SQL程序的结构化表示,它包含了Hive SQL程序的语法信息。
- SemanticAnalyzer会使用Resolver来解析AST,将AST中的变量、常量、表等引用解析为具体的值。
- SemanticAnalyzer会使用Checker来检查AST,检查AST中的语义是否正确。
Checker是SemanticAnalyzer的核心组件,它负责检查AST的语义。Checker会对AST进行以下检查:
- 语法检查:Checker会检查AST是否满足Hive的语法规则。
- 类型检查:Checker会检查AST中的变量、常量、表达式等的类型是否正确。
- 范围检查:Checker会检查AST中的变量是否在定义的范围内使用。
- 约束检查:Checker会检查AST中的约束是否满足。
如果Checker发现语义错误,则会记录在Hive的错误日志中。
SemanticAnalyzer的检查过程是递归的,它从AST的根节点开始,逐级检查子节点。如果发现语义错误,则会中止检查,并返回错误信息。
Checker
SemanticAnalyzer中的Checker是用来检查源代码语义是否正确的组件。它通常是基于一个类型系统来实现的。类型系统定义了程序中的各种类型,以及这些类型之间的关系。Checker会使用类型系统来检查程序中的表达式、语句和函数是否符合语义规则。
Checker的实现可以分为以下几个步骤:
- 构建符号表。符号表是存储程序中所有符号及其类型信息的数据结构。Checker需要使用符号表来查找符号的类型。
- 检查表达式。Checker会检查表达式的类型是否正确。例如,如果表达式的类型是整数,那么其值必须是一个整数。
- 检查语句。Checker会检查语句的语义是否正确。例如,如果语句是赋值语句,那么其左值和右值的类型必须是兼容的。
- 检查函数。Checker会检查函数的参数类型和返回类型是否正确。
以下是一个简单的Checker的实现示例:
class Checker:
def __init__(self, symbol_table):
self.symbol_table = symbol_table
def check_expression(self, expression):
# 检查表达式的类型是否正确
expression_type = self.symbol_table.get_type(expression)
if expression_type is None:
raise SemanticError("Unknown symbol: " + expression)
# 检查表达式的值是否正确
if expression_type == "int":
if not isinstance(expression, int):
raise SemanticError("Expression is not an integer: " + expression)
elif expression_type == "float":
if not isinstance(expression, float):
raise SemanticError("Expression is not a float: " + expression)
def check_statement(self, statement):
# 检查语句的语义是否正确
if isinstance(statement, AssignmentStatement):
# 检查赋值语句的左值和右值的类型是否兼容
variable_type = self.symbol_table.get_type(statement.variable)
value_type = self.check_expression(statement.value)
if variable_type != value_type:
raise SemanticError("Type mismatch: " + statement)
elif isinstance(statement, IfStatement):
# 检查条件表达式的类型是否是布尔值
condition_type = self.check_expression(statement.condition)
if condition_type != "bool":
raise SemanticError("Condition is not a boolean: " + statement)
elif isinstance(statement, WhileStatement):
# 检查条件表达式的类型是否是布尔值
condition_type = self.check_expression(statement.condition)
if condition_type != "bool":
raise SemanticError("Condition is not a boolean: " + statement)
def check_function(self, function):
# 检查函数的参数类型是否正确
for parameter in function.parameters:
parameter_type = self.symbol_table.get_type(parameter)
if parameter_type is None:
raise SemanticError("Unknown symbol: " + parameter)
# 检查函数的返回类型是否正确
return_type = self.symbol_table.get_type(function.return_type)
if return_type is None:
raise SemanticError("Unknown symbol: " + function.return_type)
这个Checker可以检查简单的表达式、语句和函数。它使用了一个简单的符号表来存储程序中所有符号及其类型信息。它还使用了一些简单的规则来检查表达式、语句和函数的语义。
HiveServer2
HiveServer2 是 Hive 的一种服务器模式,它允许用户通过 JDBC 或 ODBC 连接到 Hive。HiveServer2 在 Hive 的后端运行,它将用户的查询发送到 Hive 的执行引擎。HiveServer2 还负责处理用户的连接和认证。
HiveServer2 相对于 Hive 的其他模式有以下优点:
- 它提供了一个可扩展的连接管理器,可以处理多个用户同时连接到 Hive。
- 它提供了一个安全的连接管理器,可以使用用户名和密码来认证用户。
- 它提供了一个标准的 JDBC 和 ODBC 接口,可以通过任何支持这些接口的客户端工具来连接到 Hive。
HiveServer2 是 Hive 的默认服务器模式。它是使用 Hive 的推荐方式。
HiveServer2 的工作原理如下:
- 用户使用 JDBC 或 ODBC 连接到 HiveServer2。
- HiveServer2 会验证用户的连接,并为用户创建一个会话。
- 用户向 HiveServer2 发送查询。
- HiveServer2 将查询发送到 Hive 的执行引擎。
- Hive 的执行引擎执行查询,并将结果返回给 HiveServer2。
- HiveServer2 将结果返回给用户。
HiveServer2 的架构如下:
+-------------------------------------------------------+
| HiveServer2 |
+-------------------------------------------------------+
| |
| Hive Driver |
| |
+-------------------------------------------------------+
| |
| JDBC/ODBC Client |
| |
+-------------------------------------------------------+
HiveServer2 由以下组件组成:
- HiveServer2 服务器:HiveServer2 服务器是 HiveServer2 的核心组件,它负责处理用户的连接、认证和查询。
- Hive 执行引擎:Hive 执行引擎负责执行 Hive 的查询。
- Hive JDBC/ODBC 驱动程序:Hive JDBC/ODBC 驱动程序提供 JDBC 和 ODBC 接口,可以通过任何支持这些接口的客户端工具来连接到 Hive。
HiveServer2 服务器
Hive 执行引擎
Hive 执行引擎是 Hive 的核心组件,它负责执行 Hive 的查询。Hive 执行引擎可以使用不同的计算引擎来执行查询,包括 MapReduce、Tez 和 Spark。
Hive 执行引擎的功能如下:
- 解析查询语句。
- 生成执行计划。
- 执行执行计划。
- 生成查询结果。
Hive 执行引擎的实现可以分为以下几个阶段:
- 解析阶段:Hive 执行引擎首先会解析查询语句,并生成语法树。
- 优化阶段:Hive 执行引擎会对语法树进行优化,以提高查询的性能。
- 编译阶段:Hive 执行引擎会将优化后的语法树转换为执行计划。
- 执行阶段:Hive 执行引擎会根据执行计划来执行查询。
- 结果阶段:Hive 执行引擎会将查询结果返回给用户。
Hive 执行引擎的架构如下:
+-------------------------------------------------------+
| Hive 执行引擎 |
+-------------------------------------------------------+
| |
| Parser |
| |
+-------------------------------------------------------+
| |
| Optimizer |
| |
+-------------------------------------------------------+
| |
| HivePlanner |
| |
+-------------------------------------------------------+
| |
| HiveExecDriver |
| |
+-------------------------------------------------------+
| |
| HiveExecMapper |
| |
+-------------------------------------------------------+
| |
| HiveExecReducer |
| |
+-------------------------------------------------------+
Hive 执行引擎由以下组件组成:
- Parser:Parser 负责解析查询语句,并生成语法树。
- Optimizer:Optimizer 负责对语法树进行优化,以提高查询的性能。
- HivePlanner:HivePlanner 负责将优化后的语法树转换为执行计划。
- HiveExecDriver:HiveExecDriver 负责执行查询。
- HiveExecMapper:HiveExecMapper 负责执行 MapReduce 阶段的任务。
- HiveExecReducer:HiveExecReducer 负责执行 Reduce 阶段的任务。
Hive 执行引擎的优化策略可以分为以下几个方面:
-
逻辑优化:逻辑优化是指对查询的语法树进行优化,以提高查询的性能。例如,Hive 执行引擎可以通过以下方式来进行逻辑优化:
- 常量折叠:将查询中出现的常量值折叠到表达式中,以减少计算量。
- 子查询优化:将子查询合并到外层查询中,以减少查询的次数。
- 谓词下推:将查询中的谓词下推到表扫描之前,以减少扫描的数据量。
-
物理优化:物理优化是指对查询的执行计划进行优化,以提高查询的性能。例如,Hive 执行引擎可以通过以下方式来进行物理优化:
- 合并 Map 任务:将多个 Map 任务合并到一个 Map 任务中,以提高 Map 任务的并行度。
- 合并 Reduce 任务:将多个 Reduce 任务合并到一个 Reduce 任务中,以减少 Reduce 任务的数量。
- 选择合适的计算引擎:根据查询的特点,选择合适的计算引擎,以提高查询的性能。
Hive JDBC/ODBC 驱动程序
Hive JDBC/ODBC 驱动程序是 Hive 提供的一种连接器,它允许用户通过 JDBC 或 ODBC 连接到 Hive。Hive JDBC/ODBC 驱动程序提供标准的 JDBC 和 ODBC 接口,可以通过任何支持这些接口的客户端工具来连接到 Hive。
Hive JDBC/ODBC 驱动程序的功能如下:
- 支持 JDBC 和 ODBC 接口。
- 支持 Hive 的所有功能,包括查询、DDL、DML 等。
- 支持 Hive 的所有数据类型,包括表、视图、UDF 等。
- 支持 Hive 的所有安全功能,包括用户名、密码、Kerberos 等。
Hive JDBC/ODBC 驱动程序可以通过以下方式下载:
- 从 Hive 的官方网站下载。
- 从 Hive 的源代码中编译。
Hive JDBC/ODBC 驱动程序的使用方法如下:
- 使用 JDBC 连接到 HiveServer2。
- 使用 ODBC 连接到 HiveServer2。
Hive JDBC/ODBC 驱动程序的示例代码如下:
// 使用 JDBC 连接到 HiveServer2
Connection connection = DriverManager.getConnection("jdbc:hive2://localhost:10000/default", "user", "password");
// 使用 ODBC 连接到 HiveServer2
Connection connection = DriverManager.getConnection("jdbc:hive2://localhost:10000/default;user=user;password=password");
Hive JDBC/ODBC 驱动程序的优势如下:
- 提供了一种标准的连接方式,可以通过任何支持 JDBC 或 ODBC 的客户端工具来连接到 Hive。
- 提供了一种安全的连接方式,可以使用用户名、密码、Kerberos 等来认证用户。
- 提供了一种灵活的连接方式,可以通过 JDBC 或 ODBC 接口来访问 Hive 的所有功能。
Optimizer
Hive中的Optimizer是负责优化Hive SQL程序执行计划的组件。Optimizer会对Hive SQL程序的执行计划进行以下优化:
优化过程
-
逻辑优化:Optimizer会对Hive SQL程序的逻辑执行计划进行优化,例如:
- 推导常量
- 合并子查询
- 重写表达式
-
物理优化:Optimizer会对Hive SQL程序的物理执行计划进行优化,例如:
- 选择合适的分布策略
- 选择合适的算子
- 合并MapReduce任务
原理
Optimizer的原理如下:
- Optimizer会首先使用语义分析器来检查Hive SQL程序的语义是否正确。如果语义错误,则会中止优化,并返回错误信息。
- Optimizer会使用逻辑优化器来对Hive SQL程序的逻辑执行计划进行优化。逻辑优化器会根据Hive的语义规则,对Hive SQL程序的逻辑执行计划进行改写,以提高执行效率。
- Optimizer会使用物理优化器来对Hive SQL程序的物理执行计划进行优化。物理优化器会根据Hive的执行机制,对Hive SQL程序的物理执行计划进行改写,以提高执行效率。
Optimizer的作用是提高Hive SQL程序的执行效率。Optimizer可以通过对Hive SQL程序的执行计划进行优化,减少不必要的计算和I/O操作,从而提高Hive SQL程序的执行效率。
在Hive 3.0中,Optimizer进行了一些改进,包括:
- 支持更加复杂的优化规则
- 支持更加灵活的优化策略
- 支持更多的优化算法
这些改进使得Hive 3.0的Optimizer更加高效,能够对Hive SQL程序进行更加有效的优化。
Hive Metastore
Hive Metastore 是 Hive 的元数据存储系统,它存储了 Hive 的所有元数据,包括表、列、分区、外部表、UDF 等。Hive Metastore 是一个关系型数据库,可以使用 MySQL、PostgreSQL 等数据库来实现。
Hive Metastore 的主要功能如下:
- 存储 Hive 的所有元数据。
- 提供对 Hive 元数据的访问接口。
- 实现 Hive 元数据的版本控制。
- 实现 Hive 元数据的安全访问控制。
Hive Metastore 的架构如下:
+-------------------------------------------------------+
| Hive Metastore |
+-------------------------------------------------------+
| |
| MySQL/PostgreSQL |
| |
+-------------------------------------------------------+
Hive Metastore 由以下组件组成:
- Hive Metastore Server:Hive Metastore Server 是 Hive Metastore 的核心组件,它负责处理对 Hive 元数据的访问请求。
- MySQL/PostgreSQL:MySQL/PostgreSQL 是 Hive Metastore 的存储组件,它存储 Hive 的所有元数据。
Hive Metastore 的优点如下:
- 提供了一个集中式、可靠的元数据存储系统。
- 提供了对 Hive 元数据的访问接口,可以通过 HiveQL 或 JDBC 来访问 Hive 元数据。
- 实现了 Hive 元数据的版本控制,可以追踪 Hive 元数据的变更历史。
- 实现了 Hive 元数据的安全访问控制,可以根据用户的权限来访问 Hive 元数据。
Hive Metastore 的缺点如下:
- 是一个单点故障系统,如果 Hive Metastore Server 发生故障,可能会导致 Hive 无法使用。
- 需要额外维护一个关系型数据库,增加了系统的复杂度。
总体而言,Hive Metastore 是一个重要的 Hive 组件,它提供了对 Hive 元数据的集中式、可靠的存储。文章来源:https://www.toymoban.com/news/detail-703452.html
总结
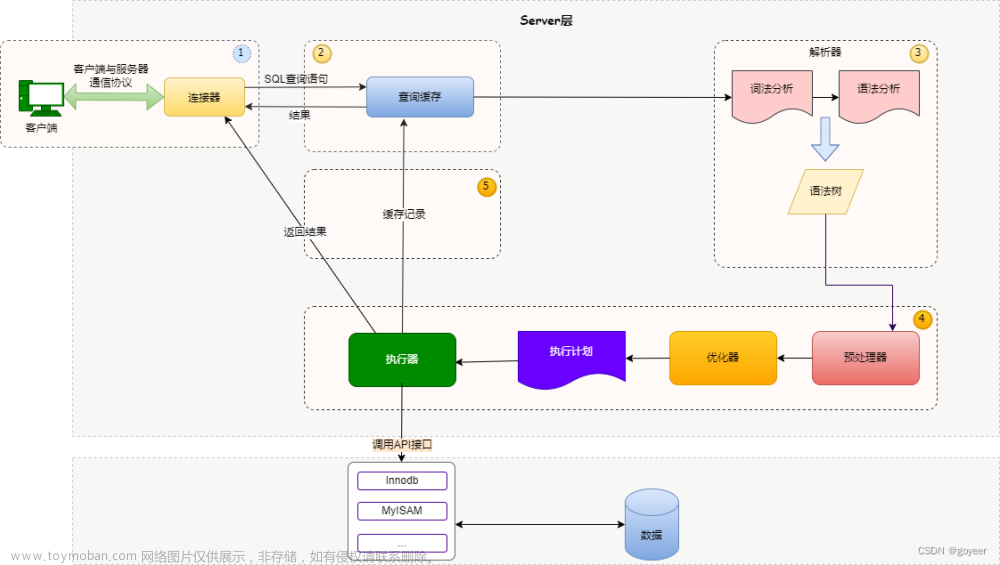
也就是说,hive sql在客户端被编写之后会发送到hive的服务端,服务端首先会对编写的sql进行词法解析和语法解析,检测语法的正确性,然后会对sql进行语义分析,如果语义分析没有问题,则进行下一步sql优化工作,优化工作完毕之后,会生成sql的执行计划,然后最终会生成一系列map reduce任务,从而得到结果。文章来源地址https://www.toymoban.com/news/detail-703452.html
到了这里,关于hivesql执行过程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!