Related Work
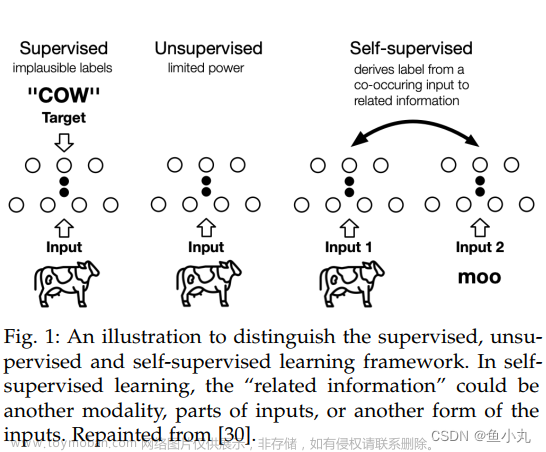
- Self-supervised 学习目的是在无人工标注的情况下通过自定制的任务(hand-crafted pretext tasks)学习丰富的表示。
Abstract
- 使用自监督学习为卷积网络(CNN)学习表示已经被验证对视觉任务有效。作为CNN的一种替代方案,视觉变换器(ViT)具有强大的表示能力,具有空间自注意力和通道级前馈网络。最近的研究表明,自监督学习有助于释放ViT的巨大潜力。然而,大多数研究仍然遵循为CNN设计的自监督策略,例如实例级别的样本区分,但它们忽视了ViT的特性。我们观察到,关于空间和通道维度的关系建模使ViT与其他网络有所不同。为了强化这一特性,我们探索了特征自关系(SElf-RElation,SERE)来训练自监督ViT。具体来说,我们不仅仅在来自多个视图的特征嵌入上进行自监督学习,还利用特征自关系,即空间/通道自关系,进行自监督学习。基于自关系的学习进一步增强了ViT的关系建模能力,产生了更强的表示,稳定地提高了多个下游任务的性能。
Introduction
- 空间自关系(spatial self-relation)提取图像中块的联系。
- 通道自关系(channel self-relation)建模不同通道间的联系,特征图(feature embeddings)中每一个通道代表了(Highlight)独特的语义信息。
- 特征自关系是新维度的表示

- (a)典型的自监督学习方法编辑图像视图的特征嵌入。
- (b)我们提出的方法去建模测量不同维度间一张图像视图内的特征自相关度。
- (c )两种特殊形式的自相关,空间自相关与通道自相关。

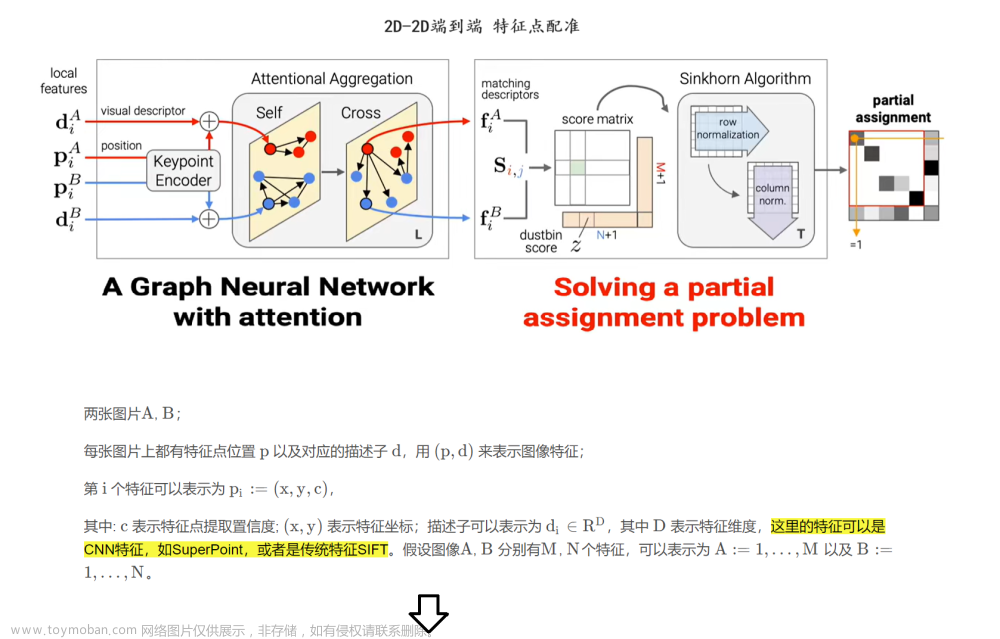
- 对空间(spatial)和通道(channel)维度的自关联(self-relation)。给出图像x,通过随机数据增强( τ n \tau_n τn)获得两个视角。再通过编码器 f n f_n fn得到特征。特征再通过表示变化 P \mathbb{P} P得到空间或者通道自相关。对于空间自相关,只有特征再重叠部分会被考虑。 O \mathbb{O} O代表再重叠区域提取特征的操作。
Method
- 我们关注于 the instance discrminative(实例判别) self-supervised learning pipeline.首先介绍一下普通实例判别自监督学习方法的框架。给一个未标注图像x,由不同的随机数据增强获得多视角。假设不同视角包含相同的信息,主要的思想是最大化不同视角间的共享信息编码。首先,两个视角被送到Encoder网络提取特征
r
1
,
r
2
r_1,r_2
r1,r2。特征被
P
\mathbb{P}
P变换成不同的表示。再借由不同的优化目标获得不同的损失函数:

- R代表最大化视角间一致性。受启发于ViT的关系建模特性,而不是直接使用特征。
空间自相关(Spatial Self-relation)
-
ViT有通过多头注意力机制(MHSA)建模局部块的特性。
-
生成 spatial self-relation 表示。首先给出嵌入特征 r 1 = f 1 ( τ 1 ( x ) ) ∈ R C × H W r_1 = f_1(\tau_1(x)) \in \mathbb{R}^{C \times HW} r1=f1(τ1(x))∈RC×HW 和 r 2 = f 2 ( τ 2 ( x ) ) ∈ R C × H W r_2 = f_2(\tau_2(x)) \in \mathbb{R}^{C \times HW} r2=f2(τ2(x))∈RC×HW。一个预测头 h p h_p hp, 处理得到 p 1 = h p ( r 1 ) p_1 = h_p(r_1) p1=hp(r1) and p 2 = h p ( r 2 ) p_2 = h_p(r_2) p2=hp(r2)。
-
不同于图像级的嵌入,不同视角的空间自监督(Sptial Self-relation)需要由计算相同空间位置的patches计算。为此,提出 O \mathbb{O} O的操作去采样 p 1 p_1 p1和 p 2 p_2 p2的重叠区域,如下图。

-
我们在原图中定位重叠区域,并将其分为 H s × W s H_s \times W_s Hs×Ws个格子。对于每个格子中心,我们计算其在不同视角特征中的空间坐标。然后通过bi-linear 内插采样特征。
-
这样我们就可以计算空间自相关(Self-Relation) A p ( p 1 ) ∈ R H s W s × H s W s \mathbb{A_p}(p_1) \in \mathbb{R}^{H_sW_s \times H_sW_s} Ap(p1)∈RHsWs×HsWs

-
t_p是温度参数控制Softmax的峰值。
-
空间自关系(Spatial Self-Relation)的自监督:使用 asymmetric non-contrastive self-supervised loss:
 文章来源:https://www.toymoban.com/news/detail-703837.html
文章来源:https://www.toymoban.com/news/detail-703837.html -
R e R_e Re是交叉熵损失函数, G \cancel{G} G 是 stop-gradient 操作防止训练崩溃。 A p \mathbb{A}_p Ap是asymmetric non-contrastive self-supervised loss的预测头,包含全连接层以及batch normalization 层。文章来源地址https://www.toymoban.com/news/detail-703837.html
通道自相关(Channel-relation)
- 不同的通道编码不同的模式,给与神经网络强大的表示能力。ViT的前馈网络(FFN)结合了跨通道模式并且编码了通道间的关系。
-
Generating channel self-relation representation. 根据
r
1
,
r
2
r_1,r_2
r1,r2,一个投影头
h
c
h_c
hc(与
h
p
h_p
hp结构相同),获得
c
1
=
h
c
(
r
1
)
T
,
c
2
=
h
c
(
r
2
)
T
c_1 = h_c(r_1)^T,c_2 = h_c(r_2)^T
c1=hc(r1)T,c2=hc(r2)T。然后独立计算通道自相关。对于
c
1
,
c
2
∈
R
H
W
×
C
c_1,c_2 \in \mathbb{R}^{HW \times C}
c1,c2∈RHW×C,我们计算通道自相关
A
c
(
c
1
)
∈
R
C
×
C
\mathbb{A_c(c_1)} \in \mathbb{R}^{C \times C}
Ac(c1)∈RC×C。

-
通道自关系的自监督函数同空间自关系:

实施细节
- 使用提出的Spatial/channel self-relations 以及 Image Embedding 作为自关系损失函数,这些损失揭示了特征的不同属性。

-
L
I
L_I
LI是图像级Embedding的损失,在Tab.8中可知使用我们提出的方法可以获得有竞争力甚至是更好的结果。

到了这里,关于论文阅读:SERE: Exploring Feature Self-relation for Self-supervised Transformer的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[arxiv论文阅读] LiDAR-LLM: Exploring the Potential of Large Language Models for 3D LiDAR Understanding](https://imgs.yssmx.com/Uploads/2024/02/785864-1.png)




![[论文阅读] Revisiting Feature Propagation and Aggregation in Polyp Segmentation](https://imgs.yssmx.com/Uploads/2024/02/786537-1.jpeg)