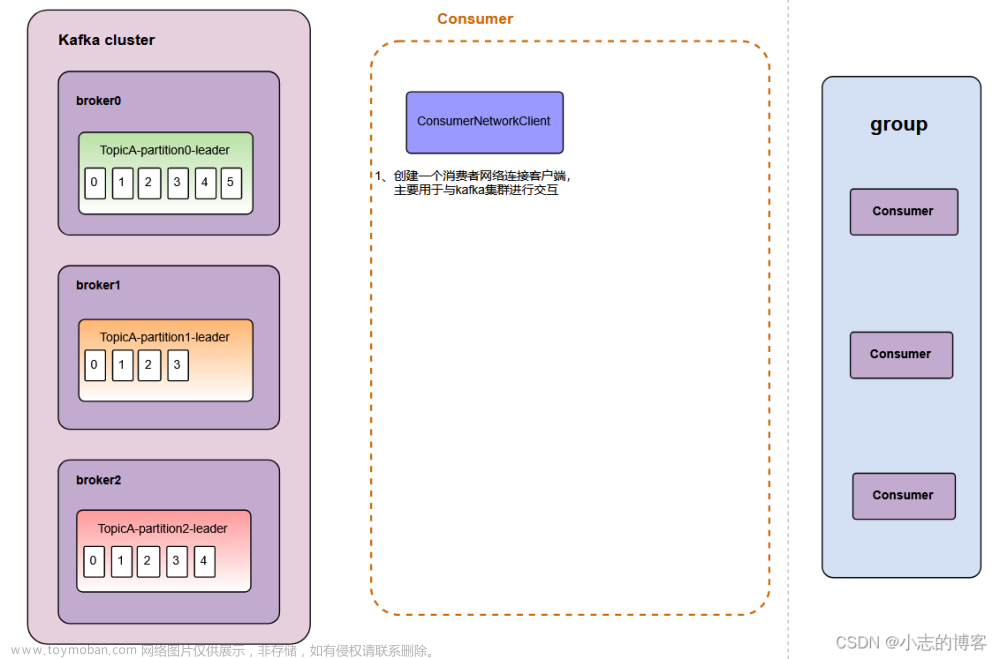
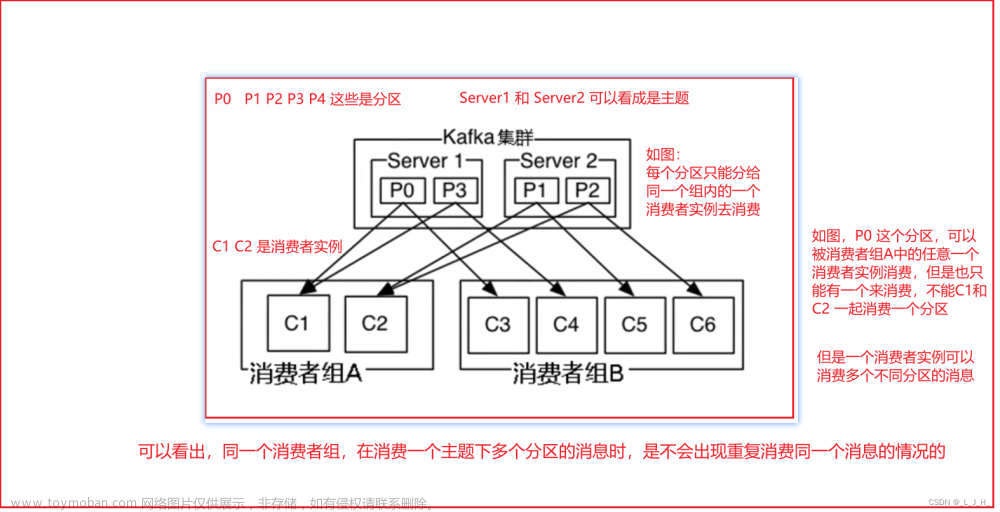
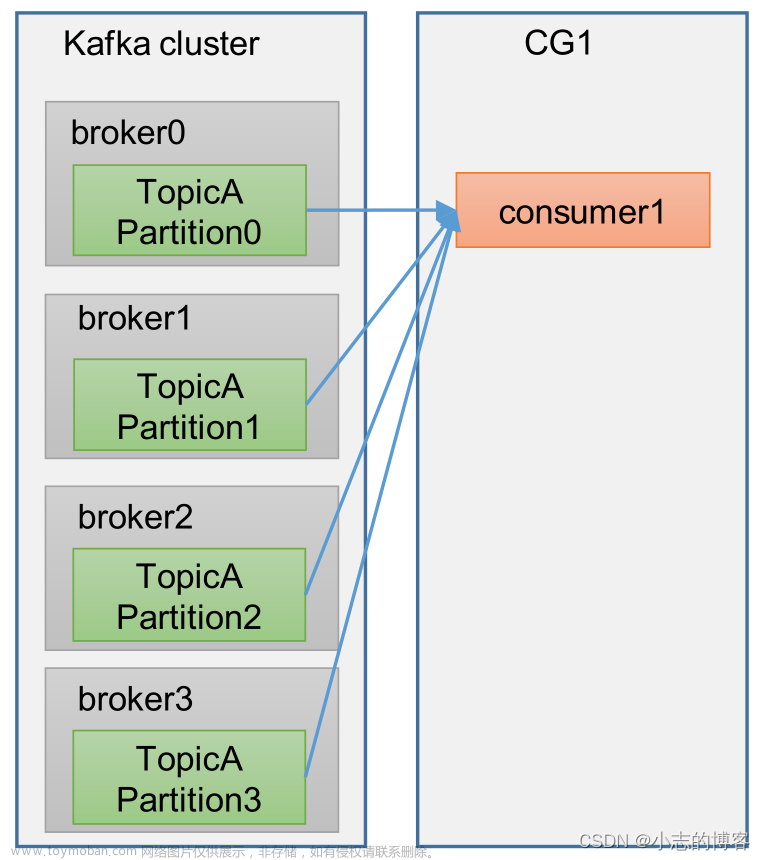
当我们使用kafka的时候存在这样一个场景:
有一个消费组正在正常消费中并且消息偏移量策略为lastoffset(最新偏移量),这个时候在kafka服务器中为当前主题下新增了一个分区,各个生产者纷纷将消息投递到了这个新增分区中。当然我们知道针对于这种场景消费者方可以触发重平衡回调方法,不过需要注意的一点是这个过程并非即时触发,它中间是会有一段时间的空档期,这个空档期决策与消费者刷新kafka集群元数据时间参数有关,一般都会设置为分钟级。那么问题就来了,在空档期中新分区的消息没有任何消费者接管,这就导致了即使过了这个空档期触发了重平衡机制也无法消费到之前的消息,因为我们的偏移量策略为lastoffset(最新偏移量)。
针对于这个场景我个人给出的一些解决方案和思路,供大家参考:
我的实现思路:
一、操作kafka系统命令实现(简单暴力,需要手动启停相关消费者进程):
1. 执行强行重置某个主题下某个分区的消费者组消息偏移量为0的命令:
需要注意的是如果当前myGroup消费者组处于活跃状态(有消费者进程运行)的情况,该命令会报错,所以需要停止掉当前消费者组下的所有消费者进程。
kafka-consumer-groups.sh --bootstrap-server kafka-kraft:9092 --group myGroup --reset-offsets --topic myTopic:1 --to-offset 0 --execute2. 启动当前这个消费者组下的消费者进程,这个时候消费者组检测当前分区偏移量为0,自然就会重头开始消费这个分区的所有消息。
二、消费者客户端代码层实现(无需启停相关消费者进程):
自行维护当前主题的某个消费者组的分区数;
需要知道本次周期新增了哪些分区;
在重平衡方法中将这个新分区的offset置为0,也就是重头消费这个新分区的所有消息;
我的实现方案:
在重平衡回调方法中使用redis的无序集合储存当前主题、当前消费者组下的全部分区信息,然后在根据当前消费者会话去和上一代的全部分区信息进行差集对比,对比的结果就是新增的分区。得到新增的分区后将这些分区的偏移量重置为0即重头开始消费,当前存在重复消费的情况,需要你的业务逻辑上做好幂等性。最后再将这些差集新增分区ID更新至redis存储的当前主题、当前消费者组下的全部分区信息内形成了一个闭环,即使一个消费者组下有多个消费者进程也不会出现数据覆盖更新等问题,因为如果存在差集新增分区只会将更新差集分区ID。文章来源:https://www.toymoban.com/news/detail-704074.html
以下是代码演示:文章来源地址https://www.toymoban.com/news/detail-704074.html
package main
import (
"context"
"fmt"
"github.com/Shopify/sarama"
"github.com/go-redis/redis/v8"
"log"
"os"
"strconv"
"time"
)
type ConsumerGroupHandler struct {
Client sarama.Client
GroupId string
}
var redisClient *redis.Client
func init() {
redisClient = redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "", // no password set
DB: 0, // use default DB
})
}
func SliceDiff(a, b []int32) (diff []int32) {
set := make(map[int32]struct{})
for _, v := range b {
set[v] = struct{}{}
}
for _, v := range a {
if _, ok := set[v]; !ok {
diff = append(diff, v)
}
}
return
}
// c *ConsumerGroupHandler.getNewPartition 获取新增分区
func (c *ConsumerGroupHandler) getNewPartition(topic, groupId string, currentPartition []int32) ([]int32, error) {
key := fmt.Sprintf("kafkaPartition.%s:%s", topic, groupId)
if exists, err := redisClient.Exists(context.Background(), key).Result(); exists == 0 || err != nil {
allPartitions, err := c.Client.Partitions(topic)
err = c.syncPartition(topic, groupId, allPartitions)
return nil, err
}
oldPartition := make([]int32, 0)
cursor := uint64(0)
for {
keys, cursor, err := redisClient.SScan(context.Background(), key, cursor, "*", 100).Result()
if err != nil {
return nil, err
}
newKeys := make([]int32, 0, len(keys))
for _, k := range keys {
i, _ := strconv.ParseInt(k, 10, 32)
newKeys = append(newKeys, int32(i))
}
oldPartition = append(oldPartition, newKeys...)
if cursor == 0 {
break
}
}
diffPartition := SliceDiff(currentPartition, oldPartition)
log.Printf("当前分区集合: %v 上一代分区集合: %v 差集新增分区集合: %v \n", currentPartition, oldPartition, diffPartition)
return diffPartition, nil
}
// c *ConsumerGroupHandler.syncPartition 同步更新分区信息
func (c *ConsumerGroupHandler) syncPartition(topic, groupId string, partition []int32) (err error) {
partitionStrings := make([]string, 0, len(partition))
for _, p := range partition {
partitionStrings = append(partitionStrings, strconv.Itoa(int(p)))
}
_, err = redisClient.SAdd(context.Background(), fmt.Sprintf("kafkaPartition.%s:%s", topic, groupId), partitionStrings).Result()
return
}
func (c *ConsumerGroupHandler) Setup(sess sarama.ConsumerGroupSession) error {
log.Println("Setup CallBack Start...")
for topic, partition := range sess.Claims() {
log.Printf("主题:%s 分区:%+v \n", topic, partition)
newPartition, err := c.getNewPartition(topic, c.GroupId, partition)
if newPartition != nil && err == nil {
for _, p := range newPartition {
//这里之所以调用这个方法是因为当消费者没有消费过这个新分区的任何一条消息时
//kafka内部__consumer_offsets这个主题下分区偏移量为-1
//当分区偏移量为-1时sess.ResetOffset方法是无效的,所以先将偏移量提交至
//kafka集群并且0,这里不必担心偏移量出现问题,因为sess.MarkOffset方法
//不会提交真实分区偏移量小于第三个参数的情况
sess.MarkOffset(topic, p, 0, "")
sess.ResetOffset(topic, p, 0, "")
log.Printf("主题:%s 分区:%d 已完成偏移量重置. \n", topic, p)
}
if err = c.syncPartition(topic, c.GroupId, newPartition); err != nil {
log.Println("Setup CallBack syncPartition Error: ", err)
return err
}
} else if err != nil {
log.Println("Setup CallBack getNewPartition ERROR:", err)
return err
}
log.Println("Setup CallBack syncPartition Success!")
}
log.Println("Setup CallBack Finish...")
return nil
}
func (*ConsumerGroupHandler) Cleanup(_ sarama.ConsumerGroupSession) error {
log.Println("\n Cleanup CallBack...")
return nil
}
func (c *ConsumerGroupHandler) ConsumeClaim(sess sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for msg := range claim.Messages() {
if err := c.handler(msg); err != nil {
log.Println("消息处理失败: ", err, " msg: ", msg)
}
sess.MarkMessage(msg, "")
sess.Commit()
}
return nil
}
func (c *ConsumerGroupHandler) handler(msg *sarama.ConsumerMessage) error {
log.Printf("Message key:%v value:%v topic:%q partition:%d offset:%d \n", string(msg.Key), string(msg.Value), msg.Topic, msg.Partition, msg.Offset)
return nil
}
func main() {
groupId := os.Args[1]
config := sarama.NewConfig()
config.Consumer.Return.Errors = true
config.Consumer.Offsets.AutoCommit.Enable = false
config.Version = sarama.V3_2_0_0
config.Metadata.RefreshFrequency = time.Minute
client, err := sarama.NewClient([]string{"192.168.6.105:9093"}, config)
if err != nil {
panic(any(err))
}
defer func() { _ = client.Close() }()
handler := &ConsumerGroupHandler{Client: client, GroupId: groupId}
group, err := sarama.NewConsumerGroup([]string{"192.168.6.105:9093"}, handler.GroupId, config)
if err != nil {
panic(any(err))
}
defer func() { _ = group.Close() }()
// Track errors
go func() {
for err = range group.Errors() {
fmt.Println("ERROR", err)
}
}()
ctx := context.Background()
topics := []string{"myTopic"}
for {
err = group.Consume(ctx, topics, handler)
if err != nil {
panic(any(err))
}
}
}

到了这里,关于golang kafka Shopify/sarama 消费者重置新增分区偏移量并进行重新消费的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!