项目源码
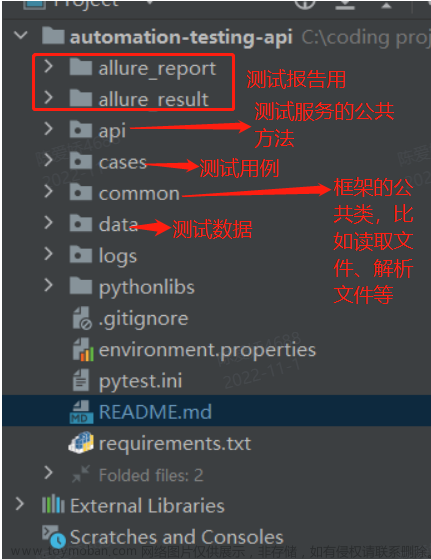
目录结构及项目介绍
整体目录结构,目录说明参考
测试用例结构类似httprunner写法,可参考demo

主要核心函数
用例读取转换json文章来源:https://www.toymoban.com/news/detail-704184.html
import yaml
import main
import os
def yaml_r():
curpath = f'{main.BASE_DIR}/quality_management_logic/ops_new/TestCaseCenter'
yamlpath = os.path.join(curpath, "ops.yaml")
f = open(yamlpath, 'r', encoding='utf-8')
cfg = f.read()
d = yaml.load(cfg,Loader=yaml.FullLoader) # 用load方法转字典
return d
测试用例格式处理函数文章来源地址https://www.toymoban.com/news/detail-704184.html
import ast
import yaml
import os
import datetime
import time
now_time = datetime.datetime.now()
now = datetime.datetime.strftime(now_time, '%Y-%m-%d %H:%M:%S')
logger = getlog(targetName='Case_Get_Data')
import openpyxl
def GetPreposition(mydict,pattern,res):
'''
获取value中的sql
:param str:
:param pattern:
:param env:
:return:
'''
#字典类型的
# pattern1=f'${pattern}:$'
# res={'code': '', 'data': {}, 'flag': 'S', 'msg': ''}
if isinstance(mydict, dict): # 使用isinstance检测数据类型,如果是字典
# if key in mydict.keys(): # 替换字典第一层中所有key与传参一致的key
# if value in mydict.values():
for key in mydict.keys():
if isinstance(mydict[key],int) or mydict[key]==None:
continue
if str(pattern) in (mydict[key]):
mydict[key] = eval((mydict[key]).split(pattern)[1])
# for k in mydict.keys(): # 遍历字典的所有子层级,将子层级赋值为变量chdict,分别替换子层级第一层中所有key对应的value,最后在把替换后的子层级赋值给当前处理的key
chdict = mydict[key]
GetPreposition(chdict,pattern,res)
if str(pattern) in str(mydict[key]):
mydict[key] = eval(list(mydict[key])[0].split(pattern)[1])
elif isinstance(mydict, list): # 如是list
for element in mydict: # 遍历list元素,以下重复上面的操作
if isinstance(element, dict):
# if value in element.values():
for key in element.keys():
if str(pattern) in str(element[key]):
element[key] =eval(list(element[key])[0].split(pattern)[1])
# for k in mydict.keys(): # 遍历字典的所有子层级,将子层级赋值为变量chdict,分别替换子层级第一层中所有key对应的value,最后在把替换后的子层级赋值给当前处理的key
chdict = element[key]
GetPreposition(chdict,pattern,res)
if str(pattern) in str(element[key]):
element[key] = eval(list(element[key])[0].split(pattern)[1])
def GetSql(dic,pattern='sql-',env='stg2'):
'''
获取用例中的sql
:param dic:
:param pattern:
:param env:
:return:
'''
if isinstance(dic,dict):
if re.match(pattern,str(list(dic.keys())[0]),re.I):
logger.debug('有查数据库的变量,开始获取sql')
try:
sql=list(dic.values())[0]
dbname=list(dic.keys())[0].split('-')[1]
return list(DBmananger(env, dbname).callMysql(sql)[0].values())[0]
except Exception as e:
logger.error(e)
return ''
else:
return False
def Issql(sql):
if isinstance(sql,dict) :
return True
else:
return False
def GetSqll(dic,pattern='sql-',env='stg1'):
'''
获取value中的sql
:param str:
:param pattern:
:param env:
:return:
'''
#字典类型的
if isinstance(dic, dict): # 使用isinstance检测数据类型,如果是字典
for key in dic.keys():
if isinstance(dic[key],int) or dic[key]==None:
continue
if pattern in (dic[key]):
try:
sql = (dic[key]).split(":")[1]
dbname = (dic[key]).split(":")[0].split('-')[1]
dic[key] = list(DBmananger(env, dbname).callMysql(sql)[0].values())[0]
except Exception as e:
logger.error(e)
# for k in mydict.keys(): # 遍历字典的所有子层级,将子层级赋值为变量chdict,分别替换子层级第一层中所有key对应的value,最后在把替换后的子层级赋值给当前处理的key
chdict = dic[key]
GetSqll(chdict, pattern, env)
elif isinstance(dic, list): # 如是list
for element in dic: # 遍历list元素,以下重复上面的操作
if isinstance(element, dict):
# if value in element.values():
for key in element.keys():
if isinstance(element[key], int) or element[key] == None:
continue
if pattern in element[key]:
try:
sql = element[key].split(":")[1]
dbname = element[key].split(":")[0].split('-')[1]
element[key] = list(DBmananger(env, dbname).callMysql(sql)[0].values())[0]
except Exception as e:
logger.error(e)
# for k in mydict.keys(): # 遍历字典的所有子层级,将子层级赋值为变量chdict,分别替换子层级第一层中所有key对应的value,最后在把替换后的子层级赋值给当前处理的key
chdict = element[key]
GetSqll(chdict, pattern, env)
else:
for i in range(len(dic)):
if isinstance(dic[i], int) or dic[i] == None:
continue
if pattern in dic[i]:
try:
sql = dic[i].split(":")[1]
dbname =dic[i].split(":")[0].split('-')[1]
dic[i] = list(DBmananger(env, dbname).callMysql(sql)[0].values())[0]
except Exception as e:
logger.error(e)
def GetExpectedResults(dic):
'''
获取预期结果值,dict的value必须是list,有且两个值,第一个是位置,第二个是值
:param dic:
:return:
'''
ExpectedResults = dic.get("ExpectedResults")
ExpectedResults=ast.literal_eval(str(ExpectedResults))
if isinstance(ExpectedResults, list): # 如是list
if len(ExpectedResults)==2:
return ExpectedResults
else:
return ['res', '']
def GetFun(dic,env,pattern='fun'):
'''
获取用例中的自定义函数
:param dic:
:param pattern:
:return:
'''
if isinstance(dic, dict):
if re.match(pattern,str(list(dic.keys())[0]),re.I):
logger.debug(f'有调用公共函数,开始获取调用函数:{list(dic.values())[0]}')
return eval(list(dic.values())[0].replace('env',env))
else:
return False
def yaml_r(yamlpath):
'''
yaml文件转换成json
:param yamlpath:
:return:
'''
with open(yamlpath, 'r', encoding='utf-8') as f:
# f = open(yamlpath, 'r', encoding='utf-8')
cfg = f.read()
d = yaml.load(cfg,Loader=yaml.FullLoader) # 用load方法转字典
return d
def File_Name(file_dir):
L = []
for root, dirs, files in os.walk(file_dir):
for file in files:
if os.path.splitext(file)[1] == '.yaml':
L.append(os.path.join(root, file))
return L
def to_extract(key):
return f"${key}$"
# 遍历嵌套字典或list并替换字典的key
def update_allvalues(mydict, value, env='stg1'):
tovalue=GetSqll(mydict, env)
if isinstance(mydict, dict): # 使用isinstance检测数据类型,如果是字典
# if key in mydict.keys(): # 替换字典第一层中所有key与传参一致的key
# if value in mydict.values():
for key in mydict.keys():
if value in mydict[key] :
mydict[key] = tovalue
# for k in mydict.keys(): # 遍历字典的所有子层级,将子层级赋值为变量chdict,分别替换子层级第一层中所有key对应的value,最后在把替换后的子层级赋值给当前处理的key
chdict = mydict[key]
update_allvalues(chdict, value, tovalue)
if value in mydict[key] :
mydict[key] = tovalue
elif isinstance(mydict, list): # 如是list
for element in mydict: # 遍历list元素,以下重复上面的操作
if isinstance(element, dict):
# if value in element.values():
for key in element.keys():
if value in element[key] :
element[key] = tovalue
# for k in mydict.keys(): # 遍历字典的所有子层级,将子层级赋值为变量chdict,分别替换子层级第一层中所有key对应的value,最后在把替换后的子层级赋值给当前处理的key
chdict = element[key]
update_allvalue(chdict, value, tovalue)
if value in str(element[key]) :
element[key] = tovalue
# 遍历嵌套字典或list并替换字典的value
def update_allvalue(mydict, value, tovalue):
if isinstance(mydict, dict): # 使用isinstance检测数据类型,如果是字典
# if key in mydict.keys(): # 替换字典第一层中所有key与传参一致的key
# if value in mydict.values():
for key in mydict.keys():
if str(value) in str(mydict[key]):
mydict[key] = (str(mydict[key]).replace(value,tovalue))
# for k in mydict.keys(): # 遍历字典的所有子层级,将子层级赋值为变量chdict,分别替换子层级第一层中所有key对应的value,最后在把替换后的子层级赋值给当前处理的key
chdict = mydict[key]
update_allvalue(chdict, value, tovalue)
if str(value) in str(mydict[key]):
mydict[key] = (str(mydict[key]).replace(value, tovalue))
elif isinstance(mydict, list): # 如是list
for element in mydict: # 遍历list元素,以下重复上面的操作
if isinstance(element, dict):
# if value in element.values():
for key in element.keys():
if str(value) in str(element[key]):
element[key] = (str(element[key]).replace(value, tovalue))
# for k in mydict.keys(): # 遍历字典的所有子层级,将子层级赋值为变量chdict,分别替换子层级第一层中所有key对应的value,最后在把替换后的子层级赋值给当前处理的key
chdict = element[key]
update_allvalue(chdict, value, tovalue)
if str(value) in str(element[key]):
element[key] = (str(element[key]).replace(value, tovalue))
def re_search(str,pattern='\\$(.*)\\$'):
#查找
match_str=re.search(pattern,str).group()
return match_str
def nowtime():
now_time = datetime.datetime.now()
now = datetime.datetime.strftime(now_time, '%Y-%m-%d %H:%M:%S')
# date_now=datetime.datetime.strftime(now_time, '%Y-%m-%d')
date = (int(time.mktime(time.strptime(now, "%Y-%m-%d %H:%M:%S"))))
return now, date
def readexcle(exclepath):
wb = openpyxl.load_workbook(exclepath)
# 获取所有工作表名
names = wb.sheetnames
# wb.get_sheet_by_name(name) 已经废弃,使用wb[name] 获取指定工作表
sheet = wb[names[0]]
# 获取最大行数
maxRow = sheet.max_row
# 获取最大列数
maxColumn = sheet.max_column
a12 = sheet.cell(row=1, column=2).value
# 定义结果变量list
result = []
for i in range(2, (maxRow)):
casedic = {}
for j in range(1, (maxColumn) + 1):
if j == 2 or j == 6 or j == 7:
casedic[sheet.cell(row=1, column=j).value] = eval(sheet.cell(row=i, column=j).value)
else:
casedic[sheet.cell(row=1, column=j).value] = sheet.cell(row=i, column=j).value
result.append(casedic)
return result
到了这里,关于接口自动化测试系列-yml管理测试用例的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!