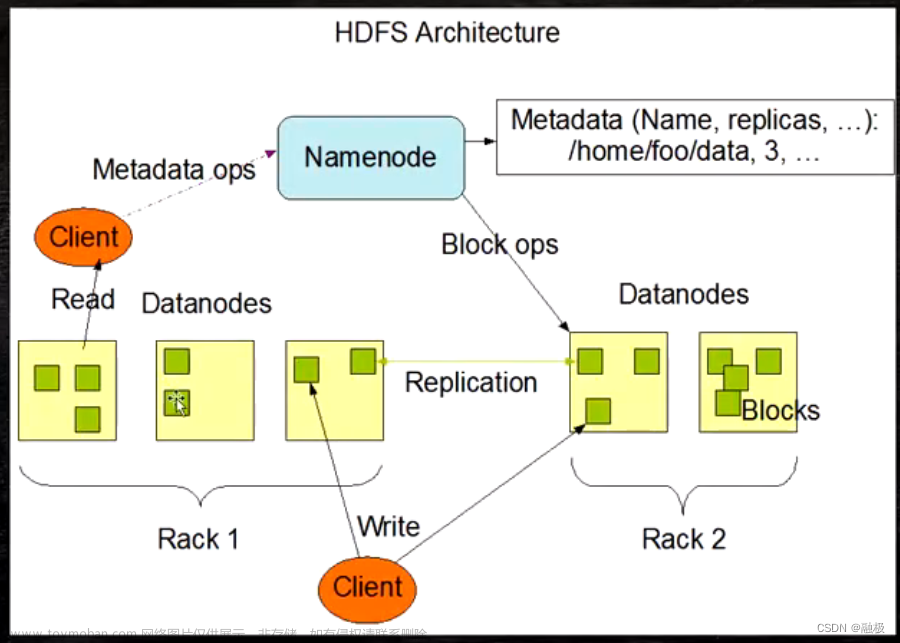
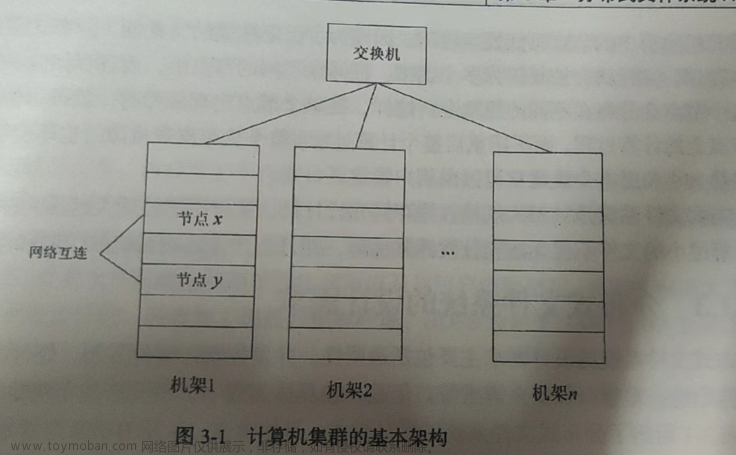
一、HDFS的组成
1、NameNode
- 存储整个HDFS集群的元数据(metaData) —— 整个集群中存储的目录和文件的索引
- 管理整个HDFS集群
- 接收客户端的请求
- 负责节点的故障转移
2、DataNode
- 存储数据,是以block块的形式进行数据的存放。
- 默认情况下block块的大小是128M。
- blocksize大小的计算公式:
- 寻址时间:下载文件时找到文件的时间;寻址时间是传输时间的1%的时候是最佳的状态;hdfs的寻址时间平均是10ms
- 数据传输速度:100M/s
- 定时负责汇总整个节点上存储的block块的信息,然后给NN汇报。
- 负责和客户端连接进行文件的读写操作。
3、SecondaryNameNode
- 辅助NameNode去完成edits编辑日志和fsimage镜像文件的合并操作。
4、客户端:命令行/Java API
- 负责和HDFS集群进行通信实现文件的增删改查
- 负责进行block块的分割
二、HDFS的基本使用
HDFS是一个分布式文件存储系统,可以存储数据(文件数据),HDFS既然是一个文件系统,那么就可以进行文件的上传、下载、删除、创建文件夹等等
HDFS给我们提供了两种操作的方式:①命令行来操作②通过Java API来进行操作
1、命令行操作
命令行操作
hdfs dfs -xxxx xxxxx 或者 hadoop fs -xxxx xxxxx
查看 —— hdfs dfs -ls/
新建 —— hdfs dfs -mkdir /demo
上传 —— hdfs dfs -put jdk-8u371-linux-x64.tar.gz /demo
上传并删除Linux本地内容 —— hdfs dfs -moveFromLocal hadoop-3.1.4.tar.gz /demo
下载 —— hdfs dfs -getToLocal /demo/hadoop-3.1.4.tar.gz /opt/software
下载 —— hdfs dfs -copyToLocal /demo/hadoop-3.1.4.tar.gz /opt/software
删除 —— hdfs dfs -rm -r /demo
2、Java API操作
引入Hadoop的编程依赖(hadoop-client、hadoop-hdfs)到pom.xml中:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.kang</groupId>
<artifactId>hdfs-study</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>hdfs-study</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<hadoop.version>3.1.4</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>compile</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
</project>
- hdfs的基本操作
/**
* HDFS的编程流程
* 1、创建Hadoop的配置文件对象,配置文件对象指定HDFS的相关连接配置
* 配置文件对象等同于hadoop的etc/hadoop目录下的哪些xxx.xml配置
* 2、根据配置获取和HDFS的连接
* 3、连接去操作HDFS集群
*/
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class Demo {
public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException {
//1、创建Hadoop的配置文件Configuration对象
Configuration conf = new Configuration();
//2、根据配置文件获取HDFS的连接 FileSystem
FileSystem system = FileSystem.get(new URI("hdfs://192.168.31.104:9000"), conf, "root");
//3、根据System去操作HDFS集群了
RemoteIterator<LocatedFileStatus> listedFiles = system.listFiles(new Path("/"), false);
while(listedFiles.hasNext()){
LocatedFileStatus fileStatus = listedFiles.next();
System.out.println("文件的路径" + fileStatus.getPath());
System.out.println("文件的所属用户" + fileStatus.getOwner());
System.out.println("文件的权限" + fileStatus.getPermission());
System.out.println("文件的blocksize" + fileStatus.getBlockSize());
}
}
}


import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* 单元测试
*/
public class HDFSTest {
public FileSystem fileSystem;
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
//1、创建Hadoop的配置文件Configuration对象
Configuration conf = new Configuration();
conf.set("dfs.replication","1");
//2、根据配置文件获取HDFS的连接 FileSystem
fileSystem = FileSystem.get(new URI("hdfs://192.168.31.104:9000"), conf, "root");
}
/**
* 1、通过JavaAPI实现文件的上传
*/
@Test
public void test01() throws IOException {
fileSystem.copyFromLocalFile(new Path("D:\\2023PracticalTraining\\software\\InstallPackage\\PowerDesginer16.5.zip"),new Path("/demo"));
System.out.println("上传成功!");
//fileSystem.copyToLocalFile();
}
/**
* 2、下载文件
* 在Windows上远程操作HDFS或者是在Windows上操作MapReduce代码的时候,有些情况下要求windows上也必须有hadoop的软件环境
* 但是hadoop只能在Linux上安装,因此,Windows上安装的hadoop其实是一个假的环境
* 报错:exitcode=-107xxxxxxx 原因是因为电脑缺少C语言的运行环境
*/
@Test
public void test02() throws IOException {
fileSystem.copyToLocalFile(new Path("/jdk-8u371-linux-x64.tar.gz"),new Path("D:\\Desktop"));
System.out.println("下载成功!");
}
/**
* 3、删除文件的方法
*/
@Test
public void test03() throws IOException {
boolean delete = fileSystem.delete(new Path("/demo"), true);
System.out.println(delete);
}
}
test01:


test02:
会显示报错:HADOOP_HOME and hadoop.home.dir are unset. 
在Windows上远程操作HDFS或者是在Windows上操作MapReduce代码的时候,有些情况下要求windows上也必须有hadoop的软件环境;
但是hadoop只能在Linux上安装,因此,Windows上安装的hadoop其实是一个假的环境
将发给Linux的hadoop-3.1.4.tar.gz这个安装包先解压为hadoop-3.1.4.tar再解压为hadoop-3.1.4
解压时会报错,此报错不予理会

解压后,将文件中的bin目录下的所有文件均作替换,替换文件可在百度上搜索下载
配置环境变量

编辑系统变量中的Path

再次运行程序即可成功!

test03:


package com.kang;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* hdfs查看某个路径下的所有文件和文件夹的信息
*/
public class Demo01 {
public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.31.104:9000"), conf, "root");
/**
*
*/
FileStatus[] fileStatuses = fs.listStatus(new Path("/"));
for (FileStatus fileStatus : fileStatuses) {
System.out.println(fileStatus.getPath());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
}
}
}

package com.kang;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* hdfs的相关判断类型的JavaAPI操作
*/
public class Demo02 {
public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.31.104:9000"), conf, "root");
boolean b = fs.isDirectory(new Path("/demo"));
System.out.println(b);
boolean b1 = fs.isFile(new Path("/demo"));
System.out.println(b1);
boolean exists = fs.exists(new Path("/a"));
System.out.println(exists);
}
}
package com.kang;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* hdfs的创建相关的JavaAPI
*/
public class Demo03 {
public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.31.104:9000"), conf, "root");
boolean mkdirs = fs.mkdirs(new Path("/a/b"));
System.out.println(mkdirs);
boolean newFile = fs.createNewFile(new Path("/a/a.txt"));
System.out.println(newFile);
}
}
package com.kang;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* hdfs提供了一个可以借助JavaIO流读取数据的方法
* 上传fs.create 下载fs.open
*/
public class Demo04 {
public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.31.104:9000"), conf, "root");
FSDataInputStream inputStream = fs.open(new Path("/jdk-8u371-linux-x64.tar.gz"));
inputStream.seek(128*1024*1024);
FileOutputStream fos = new FileOutputStream("D:\\Desktop\\block2");
int read = 0;
while((read = inputStream.read())!=-1){
fos.write(read);
}
System.out.println("第二个数据块读取完成");
}
}
- HDFS不适用于大量小文件的常量、HDFS不能对存储的文件进行修改操作
三、HDFS的工作流程问题(HDFS的原理性内容)
1、HDFS上传数据的流程
客户端在和DN建立连接的时候,是和距离它最近的某一个DN建立连接
怎么判断DN距离客户端的距离:网络拓扑原则
客户端和HDFS的节点在同一个集群上

- 客户端向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在。
- namenode返回是否可以上传。
- 客户端请求第一个 block上传到哪几个datanode服务器上。
- namenode返回3个datanode节点,分别为dn1、dn2、dn3。
- 客户端请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
- dn1、dn2、dn3逐级应答客户端。
- 客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
- 当一个block传输完成之后,客户端再次请求namenode上传第二个block的服务器。(重复执行3-7步)
2、HDFS下载数据的流程

- 客户端向namenode请求下载文件,namenode通过查询元数据,找到文件块所在的datanode地址。
- 挑选一台datanode(就近原则,然后随机)服务器,请求读取数据。
- datanode开始传输数据给客户端(从磁盘里面读取数据放入流,以packet为单位来做校验)。
- 客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
3、HDFS副本备份机制
数据上传的时候,会根据配置进行block块的备份,备份的时候,选择哪些节点进行数据备份?
机架感知原则进行备份
低版本Hadoop副本节点选择:
第一个副本在client所处的节点上。如果客户端在集群外,随机选一个。
第二个副本和第一个副本位于不相同机架的随机节点上。
第三个副本和第二个副本位于相同机架,节点随机。
Hadoop2.8.5副本节点选择:
第一个副本在client所处的节点上。如果客户端在集群外,随机选一个。
第二个副本和第一个副本位于相同机架,随机节点。
第三个副本位于不同机架,随机节点。
4、HDFS中NameNode和SecondaryNameNode的工作机制
这个工作机制就是NameNode如何管理元数据的机制
元数据:指的是HDFS存储文件/文件夹的类似的目录结构,目录中记录着每一个文件的大小、时间、每一个文件的block块的份数,block块存储的节点列表信息…
NameNode默认的元数据内存是1000M,可以存储管理百万个block块的元数据信息
两个和元数据有关的文件 —— 再次启动HDFS之后恢复元数据的机制
edits编辑日志文件:记录客户端对HDFS集群的写入和修改操作
fsimage镜像文件:理解为HDFS元数据的持久点检查文件
HDFS的安全模式(safemode)
HDFS启动之后会先进入安全模式,安全模式就是将edits和fsimage文件加载到nn内存的这一段时间,dn向NN注册的这一段时间
安全模式下无法操作HDFS集群的,安全模式会自动退出,NN的内存加载好了(元数据加载好了),同时HDFS集群还满足节点数的启动
SNN的作用就是对NN进行checkpoint(检查点机制)操作
-
checkpoint什么时候触发
- 检查点时间到了 —— 1小时
dfs.namenode.checkpoint.period 3600s - HDFS距离上一次检查点操作数到达100万次
dfs.namenode.checkpoint.txns 1000000
- 检查点时间到了 —— 1小时
-
SNN每隔1分钟会询问一次NN是否要进行checkponit操作
dfs.namenode.checkpoint.check.period 60s
NameNode的出现故障之后,元数据的恢复方式
-
因为元数据的核心是edits和fsimage文件,同时snn工作的时候会把nn的文件复制到snn当中,因此如果NN的元数据丢失,我们可以从SNN中把这些文件再复制到NN的目录下 进行元数据的恢复(恢复可能会导致一部分的元数据丢失)
SNN的目录: h a d o o p . t m p . d i r / d f s / n a m e s e c o n d a r y / c u r r e n t n n 的目录: {hadoop.tmp.dir}/dfs/namesecondary/current nn的目录: hadoop.tmp.dir/dfs/namesecondary/currentnn的目录:{hadoop.tmp.dir}/dfs/name/current -
元数据还有一种恢复方式:配置HDFS的namenode的多目录保存(HDFS的编辑日志和镜像文件在多个目录下保存相同的备份)
这种方式只能使用在同一个节点上
这种方式存在的问题:如果整个节点宕机,无法恢复了
dfs.namenode.name.dir 多个路径hdfs-site.xml <property> <name>dfs.namenode.name.dir</name> <value>/opt/app/hadoop/data/dfs/name1,/opt/app/hadoop/data/dfs/name2</value> </property> -
最好把HDFS重新格式化一下,或者手动把目录创建一份
-
HA高可用模式
5、HDFS中NameNode和DataNode之间的工作机制

- 详细流程
- 一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
- DataNode启动后向namenode注册,通过后,周期性(1小时)的向namenode上报所有的块信息。
- 心跳是每3秒一次,心跳返回结果带有namenode给该datanode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个datanode的心跳,则认为该节点不可用。
- 集群运行中可以安全加入和退出一些机器。
DataNode上存储的block块除了数据本身以外,还包含数据的长度、数据校验和、时间戳…
数据校验和是为了保证block块的完整性和一致性的,校验和机制,创建block块的时候会根据数据本身计算一个校验和,以后每一次DN进行block汇总的时候会再进行一次校验和的计算,如果两次校验和不一致则认为block块损坏了。
DataNode和NameNode心跳,默认三秒心跳一次,默认值可以调整
dfs.heartbeat.interval 3s
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>单位毫秒
</property>
<property>
<name> dfs.heartbeat.interval </name>
<value>3</value>单位秒
</property>
修改此配置时需关闭HDFS,但是不需要重新格式化
心跳的作用有两个:1、检测DN是否活着 2、把NN让DN做的事情告诉DN
NN如何知道DN掉线 - 死亡 - 宕机了(掉线的时限):NN如果在某一次心跳中没有收到DN的心跳,NN不会认为DN死亡了,而是会继续心跳,如果超过掉线的时限的时间还没有心跳成功,NN才会认为DN死亡了,然后启动备份恢复机制
掉线时限的时长是有一个计算公式:
timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval。
dfs.namenode.heartbeat.recheck-interval 心跳检测时间 5分钟
dfs.heartbeat.interval 心跳时间 3s
默认情况下,如果超过10min30s没有收到DN的心跳 认为DN死亡了
DataNode每隔一段时间(默认6小时)会向NameNode汇报一次节点上所有的block块的信息
dfs.blockreport.intervalMsec 21600000ms 每隔6小时向NN汇报一次DN的block块的信息
dfs.datanode.directoryscan.interval 21600s 每隔6小时DN自己扫描一下DN上的block块信息
四、HDFS、YARN的新节点的服役和旧节点的退役 —— 在namenode所在节点的hadoop中配置
1、概念
HDFS是一个分布式文件存储系统,HDFS身为一个大数据软件,基本上都是7*24小时不停机的,那如果HDFS集群的容量不够用了,那么我们需要增加一个新的数据节点,因为HDFS不能停止,因此我们需要在HDFS集群运行过程中动态的增加一个数据节点(新节点的服役操作);旧节点的退役。
2、新节点服役操作
服役新节点之前,需要创建一台新的虚拟节点,并且配置Java、Hadoop环境、SSH免密登录、ip、主机映射、主机名
1、在Hadoop的配置文件目录创建一个dfs.hosts文件,文件中声明Hadoop集群的从节点的主机名
2、在Hadoop的hdfs-site.xml文件中,增加一个配置项
dfs.hosts 值:文件的路径
<!--dfs.hosts代表改文件中的地址都为白名单,可以访问NameNode节点,与NameNode节点通信-->
<property>
<name>dfs.hosts</name>
<value>/opt/app/hadoop-3.1.4/etc/hadoop/dfs.hosts</value>
</property>
3、在HDFS开启的状态下刷新从节点的信息
hdfs dfsadmin -refreshNodes
yarn rmadmin -refreshNodes
4、只需要在新节点启动datanode和nodemanager即可成功实现节点的服役
hadoop-daemon.sh start datanode
hadoop-daemon.sh start nodemanager
3、旧节点退役操作(如果第一次增加退役文件,必须重启HDFS集群)
1、在Hadoop的配置目录创建一个文件dfs.hosts.exclude,文件中编写退役的主机名
2、在Hadoop的hdfs-site.xml配置文件中声明退役的节点文件
dfs.hosts.exclude 值 文件的路径
<!--dfs.hosts.exculde文件代表namenode访问的黑名单 需要退役的数据节点
黑名单加入的数据节点如果也在dfs.hosts文件存在的话 不会立即退出 而是先把数据块转移到其他数据节点 然后再退役
-->
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/app/hadoop-3.1.4/etc/hadoop/dfs.hosts.exclude</value>
</property>
3、同时需要在服役节点文件中把退役节点删除了在dfs.hosts中
4、刷新节点信息状态
hdfs dfsadmin -refreshNodes
yarn rmadmin -refreshNodes文章来源:https://www.toymoban.com/news/detail-704224.html
【注意】退役的时候,会先把退役节点的block块复制到没有退役的节点上,然后才会下线,而且退役的时候,必须保证退役之后剩余集群的节点数大于等于副本数文章来源地址https://www.toymoban.com/news/detail-704224.html
到了这里,关于Hadoop的分布式文件存储系统HDFS组件的使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!