一杯奶茶,成为 AIGC+CV 视觉前沿弄潮儿!
25个方向!CVPR 2022 GAN论文汇总
35个方向!ICCV 2021 最全GAN论文汇总
超110篇!CVPR 2021 最全GAN论文梳理
超100篇!CVPR 2020 最全GAN论文梳理
在最新的视觉顶会 CVPR 2023 会议中,涌现出了大量基于生成式AIGC的CV论文,包括不限于生成对抗网络GAN、扩散模型diffusion等等!除了直接生成,还广泛应用于其它各类 low-level、high-level 的视觉任务!
经过小编累计半年的跟踪,集齐和梳理了CVPR 2023里共30+大方向、近130篇的AIGC论文!下述论文均已分类打包好!
关注公众号【机器学习与AI生成创作】公众号,在后台回复 AIGC (长按红字、选中复制)即可获取分类、按文件夹汇总好的论文集,gan起来吧!!!
文章很长,梳理不易,越到后面的方向越有趣!麻烦各位看官,转发、分享、在看三连,多多鼓励小编!!!
一、图像转换/翻译
1、Masked and Adaptive Transformer for Exemplar Based Image Translation
提出了一个基于样本的图像转换新方法。 最近用于此任务的先进方法主要集中在建立跨域语义对应上,它以局部风格控制的方式顺序控制图像生成。 但跨域语义匹配具有挑战性,匹配错误最终会降低生成图像的质量。
为了克服这一挑战,一方面提高了匹配的准确性,另一方面削弱了匹配在图像生成中的作用。 为了实现前者,提出了一种掩码和自适应变换器 (MAT),用于学习准确的跨域对应关系,并执行上下文感知特征增强。 为了实现后者,使用样本的输入源特征和全局样式代码作为补充信息来解码图像。
此外,设计了一种新的对比风格学习方法,用于获取质量区分风格表示,这反过来有利于高质量图像的生成。 实验结果表明在各种图像转换任务中表现更好。 代码可在 https://github.com/AiArt-HDU/MATEBIT

2、LANIT: Language-Driven Image-to-Image Translation for Unlabeled Data
现有的图像转换技术通常存在两个关键问题:严重依赖每个样本域标注,或无法处理每个图像的多个属性。 最近的真正无监督方法采用聚类方法来提供每个样本的域标签。 然而,它们无法解释现实世界的设置:一个样本可能具有多个属性。 此外,集群的语义不容易与人类理解相结合。
为了克服这些问题,提出了语言驱动的图像转换模型,称为 LANIT。 利用数据集文本中给出的易于获取的候选属性:图像和属性之间的相似性表示每个样本域标签。 用户可以使用语言中的一组属性指定目标域。 为了解决初始提示文本不准确的情况,还提供提示学习。
进一步提出域正则化损失,强制将转换后的图像映射到相应的域。 几个标准基准的实验表明,LANIT 实现了与现有模型相当或更优的性能。

3、Interactive Cartoonization with Controllable Perceptual Factors
图像卡通化,即将自然照片渲染成卡通风格。 以前的卡通化方法只关注端到端的转换,这可能会阻碍可编辑性。 相反,本文提出了一种基于卡通创作过程的纹理和颜色编辑特征的新解决方案。
设计了一个模型架构,具有独立的解码器、纹理和颜色,以解耦这些属性。 在纹理解码器中,提出了一个纹理控制器,它使用户能够控制笔触样式和抽象以生成不同的卡通纹理。 还引入了 HSV 颜色增强来诱导网络生成多样且可控的颜色转换。 作者声称,该工作是第一个在推理时控制卡通化的深度学习方法,同时比基线有明显的质量改进。

4、LightPainter: Interactive Portrait Relighting with Freehand Scribble
给定所需的照明表示(例如环境贴图),最近的人像重新打光/照明(portrait relighting)方法已经实现了人像照明效果的逼真效果。 然而,这些方法对于用户交互来说并不直观,并且缺乏精确的照明控制。
本文推出了 LightPainter,一种基于涂鸦的重打光系统,允许用户轻松地以交互方式操纵人像照明效果。 通过两个条件神经网络实现的,一个模块根据肤色恢复几何形状和反照率,以及一个用于重新照明的基于涂鸦的模块。 为了训练重新照明模块,提出了一种新的涂鸦模拟程序来模拟真实用户的涂鸦,可以在没有任何人工注释的情况下进行训练。
通过定量和定性实验展示了高质量和灵活的肖像照明编辑能力。 用户研究与商业照明编辑工具的比较也证明了用户对方法的一致偏好。

5、Picture that Sketch: Photorealistic Image Generation from Abstract Sketches
给定一个抽象的、变形的、普通的草图,这些草图来自像你我这样未经训练的业余爱好者,本文将它变成了一个逼真的图像。
与现有技术有很大的不同,因为一开始并不规定类似边缘图的草图,而是旨在使用抽象的徒手人体草图。 首先,提出一个解耦的编码器-解码器训练范例,其中解码器是仅在照片上训练的 StyleGAN。 这可确保生成的结果始终逼真。
剩下的就是如何最好地处理素描和照片之间的抽象差距。 为此,提出了一个在草图-照片对上训练的自回归草图映射器,将草图映射到 StyleGAN 潜在空间。 进一步介绍了具体的设计来解决人体草图的抽象性质,包括在经过训练的草图照片检索模型背后的细粒度判别损失,以及部分感知的草图增强策略。
最后,展示了我们的生成模型支持的一些下游任务,其中展示了如何将基于细粒度草图的图像检索简化为图像(生成)到图像检索任务。
项目页面:https://subhadeepkoley.github.io/PictureThatSketch

6、Few-shot Semantic Image Synthesis with Class Affinity Transfer
语义图像合成,旨在在给定语义分割图的情况下生成照片般逼真的图像。 尽管最近取得了很大进展,但训练它们仍然需要大量图像数据集,这些图像数据集用像素标签图进行标注,获取起来非常繁琐。
为了减轻标注成本,提出了一种迁移方法,该方法利用在大型源数据集上训练的模型,通过估计源类和目标类之间的成对关系来提高小型目标数据集的学习能力。 类亲和矩阵( class affinity matrix )作为源模型的第一层引入,使其与目标标签映射兼容,然后针对目标域进一步微调源模型。 为了估计类亲和力,考虑利用先验知识的不同方法:源域语义分割、文本标签嵌入和自监督视觉特征。
将方法应用于基于 GAN 和基于扩散的语义合成架构。 实验表明,可以有效地组合估计类亲和力的不同方法,并且改进了生成图像模型的现有最先进的转换方法。

二、GAN改进
7、CoralStyleCLIP: Co-optimized Region and Layer Selection for Image Editing
高保真编辑(Edit fidelity)是开放可控生成图像编辑中的一个重要问题。最近,基于clip的方法通过在StyleGAN的一个精心挑选的层中引入空间注意力来进行优化改进。
本文提出CoralStyleCLIP,它在StyleGAN2的特征空间中融合了多层注意力引导的混合策略,以获得高保真的编辑。提出了多种形式的共同区域优化和层选择策略,以展示时间复杂性随不同架构复杂性的编辑质量的变化,同时保持简单性。
进行了广泛的实验分析,并将方法与最先进的基于clip的方法进行了比较。研究结果表明,在保持易用性的同时,CoralStyleCLIP可以产生高质量的编辑。
8、Cross-GAN Auditing: Unsupervised Identification of Attribute Level Similarities and Differences between Pretrained Generative Models
生成对抗网络(GAN)在训练复杂分布和数据量有限的情况下尤其难以训练。这促使需要一些工具以人类可读的格式审核已训练的网络,例如识别偏见或确保公平性。现有的GAN审核工具(GAN audit tools)仅限于基于总结统计量(如FID或召回率)的粗粒度模型数据比较。
本文提出了一种替代方法,即将新开发的GAN与之前的基线进行比较。为此,引入了跨GAN审核(Cross-GAN Auditing,xGA),给定一个已建立的“参考”GAN和一个新提出的“客户端”GAN,共同识别可理解的属性(intelligible attributes),这些属性在两个GAN中是相同的、客户端GAN中是新的、或缺少于客户端GAN中。
这为用户和模型开发人员提供了GAN之间相似性和差异的直观评估。引入新的指标来评估基于属性的GAN审核方法,并使用这些指标定量地证明xGA优于基线方法。还包括定性结果,展示了xGA从各种图像数据集上训练的GAN中识别出的常见、新颖和缺失属性。

9、Efficient Scale-Invariant Generator with Column-Row Entangled Pixel Synthesis
任意尺寸图像生成(Any-scale image synthesis)提供了一种高效和可扩展的解决方案,可以在任何比例下合成逼真的图像,甚至超过2K分辨率。然而,现有的基于GAN的解决方案过度依赖卷积和分层架构,在缩放输出分辨率时会导致不一致和“纹理粘合”问题。
从另一个角度来看,基于INR的生成器从设计上具有尺度等变性,但它们巨大的内存占用和慢速推断阻碍了这些网络在大规模或实时系统中的采用。这项工作提出了列行耦合的像素生成(Column-Row Entangled Pixel Synthesis,CREPS),一种既高效又具有尺度等变性的新型生成模型,而不使用任何空间卷积或粗到细的设计。为了节省内存占用并使系统可扩展,采用了一种新的双线表示方法(bi-line representation),将层内特征映射分解为单独的“厚”列和行编码。
在各种数据集上的实验,包括FFHQ、LSUNChurch、MetFaces和Flickr-Scenery,证实了CREPS具有在任意任意分辨率下合成尺度一致图像的能力。代码在https://github.com/VinAIResearch/CREPS

10、Fix the Noise: Disentangling Source Feature for Transfer Learning of StyleGAN
最近,StyleGAN的迁移学习已经展示出解决不同任务的潜力,特别是在领域转换方面。以前的方法在迁移学习过程中利用源模型通过权重交换或冻结来进行,然而它们在视觉质量和控制源特征方面存在局限性。换句话说,它们需要额外的模型,这些模型计算量巨大并且具有限制的控制步骤,这阻止了平滑的过渡。
本文提出了一种新的方法来克服这些限制。引入了一种简单的特征匹配损失来提高生成质量,而不是交换或冻结。此外,为了控制源特征的程度,使用所提出的策略“FixNoise”训练目标模型,仅在目标特征空间的一个分离子空间中保留源特征。由于这个分离特征空间,方法可以在一个单一模型中平滑地控制源特征的程度。广泛的实验表明,提出的方法可以比以前的方法生成更加一致和逼真的图像。

11、Improving GAN Training via Feature Space Shrinkage
由于出色的数据生成能力,生成对抗网络(GAN)在无监督学习中引起了相当大的关注。 然而,训练 GAN 很困难,因为训练分布对于鉴别器是动态的,导致图像表示不稳定。
本文从一个新的角度解决训练 GAN 的问题,即稳健的图像分类。 受鲁棒图像表示研究的启发,提出了一个简单而有效的模块,即 AdaptiveMix,用于 GAN,它缩小了鉴别器图像表示空间中训练数据的区域。 考虑到直接绑定特征空间是棘手的,提出构造hard sample并缩小难样本和易样本之间的特征距离。 hard sample是通过混合训练图像对来构建的。
使用广泛使用的最先进的 GAN 架构评估 AdaptiveMix 的有效性。 评估结果表明,AdaptiveMix 可以促进 GAN 的训练,并有效提高生成样本的图像质量。 还表明 AdaptiveMix 可以通过配备最先进的方法进一步应用于图像分类和分布外 (OOD) 检测任务。 在七个公开可用的数据集上进行的大量实验表明,方法有效地提高了基线的性能。
代码 https://github.com/WentianZhangML/AdaptiveMix

12、Look ATME: The Discriminator Mean Entropy Needs Attention
生成对抗网络(GANs)已经成功用于图像生成,但在训练过程中面临不稳定性的问题。概率扩散模型(DMs)稳定且生成高质量的图像,但采样过程代价昂贵。本文提出了一种简单的方法,将GANs与DMs的去噪机制结合起来,使GANs能够稳定地收敛到其理论最优解。这些模型被结合成一个更简单的模型(a simpler model,ATME),只需要前向传递即可进行预测。
ATME打破了大多数GAN模型存在的信息不对称,其中鉴别器具有生成器失败的空间知识。为了恢复信息对称性,生成器被赋予鉴别器的熵状态的知识,该知识被利用以使对抗游戏收敛于平衡。在几个图像到图像转换任务中展示了方法的优势,显示出比最先进的方法更好的性能,而成本更低。
代码https://github.com/DLR-MI/atme

13、NoisyTwins: Class-Consistent and Diverse Image Generation through StyleGANs
StyleGAN是可控图像生成的前沿技术,因为它生成了一个语义上解耦的潜在空间,适用于图像编辑和操作。然而,当通过对大规模长尾数据集进行类别条件训练时,StyleGAN的性能严重降低。导致性能下降的一个原因是W潜在空间中每个类别的潜变量崩溃。
本文提出NoisyTwins,首先引入了一种有效且廉价的类嵌入增强策略,然后基于W空间的自监督进行潜变量去相关。这种去相关缓解了崩溃,确保方法在图像生成中保持类内多样性和类一致性。
在ImageNet-LT和iNaturalist 2019这些大规模现实世界长尾数据集上展示了方法的有效性,其中在FID上比其他方法提高了约19%,创造了新的最优结果。

14、DeltaEdit: Exploring Text-free Training for Text-Driven Image Manipulation
文本驱动的图像编辑,在训练或推理灵活性方面仍然具有挑战性。 条件生成模型在很大程度上依赖于昂贵的带标注训练数据。 同时,利用预训练视觉语言模型的最新框架时,受到每个文本提示优化或推理时间超参数调整的限制。
这项工作提出DeltaEdit 来解决这些问题。 关键思想是识别一个空间,即两图像的 CLIP 视觉特征差异、源文本和目标文本的 CLIP 文本嵌入差异,在它们之间具有良好对齐分布的 delta 图像和文本空间。 基于 CLIP delta 空间,DeltaEdit 网络被设计为在训练阶段将 CLIP 视觉特征差异映射到 StyleGAN 的编辑方向。 然后,在推理阶段,DeltaEdit 根据 CLIP 文本特征的差异预测 StyleGAN 的编辑方向。 通过这种方式,DeltaEdit 以无文本的方式进行训练。 经过训练后,它可以很好地泛化到各种文本提示,以进行零样本推理。
代码:https://github.com/Yueming6568/DeltaEdit

15、Delving StyleGAN Inversion for Image Editing: A Foundation Latent Space Viewpoint
通过StyleGAN的逆映射inversion和编辑,可以将输入图像映射到嵌入空间(W、W+和F),同时保持图像保真度和有意义的操作。从潜在空间W到扩展潜在空间W+再到特征空间F,GAN逆映射的可编辑性降低了,虽然重构质量可以提高。
最近的GAN逆映射方法通常探索W+和F而不是W。由于W+和F是从W中衍生出来的,而W实质上是StyleGAN的基础潜在空间,这些inversion方法集中于W+和F空间,可以通过回到W进行改进。这项工作首先在基础潜在空间W中获得适当的潜变量编码。引入对比学习来对齐W和图像空间,以便发现适当的潜变量编码。然后,利用交叉注意力编码器将在W中获得的潜变量编码相应地转换为W+和F。
实验表明,对基础潜在空间W的探索提高了W+中的潜变量编码和F中的特征的表示能力,从而在标准基准测试中产生了最先进的重构保真度和可编辑性结果。项目页面:https://kumapowerliu.github.io/CLCAE

16、SIEDOB: Semantic Image Editing by Disentangling Object and Background
语义图像编辑为用户提供了一种灵活的工具,可以通过相应的分割图指导修改给定图像。在这个任务中,前景对象和背景的特征非常不同。然而,所有之前的方法都使用单一模型处理背景和对象。因此,它们在处理内容丰富的图像时仍存在限制,并且容易生成不真实的对象和纹理不一致的背景。
为了解决这个问题,提出了一种新的范式,通过分解对象和背景进行语义图像编辑(SIEDOB),其核心思想是明确利用几个异构子网络来处理对象和背景。首先,SIEDOB将编辑输入分解成背景区域和实例级对象。然后,将它们送到专门的生成器中。最后,所有合成部分都嵌入到它们原始的位置,并利用融合网络获得协调的结果。此外,为了生成高质量的编辑图像,提出了一些创新设计,包括语义感知自传播模块、边界锚定局部块级别的鉴别器和样式多样性对象生成器,并将它们集成到SIEDOB中。
在Cityscapes和ADE20K-Room数据集上进行了大量实验,并展示了方法在合成真实和多样化的对象以及纹理一致的背景方面明显优于基线方法。
代码在 https://github.com/WuyangLuo/SIEDOB

三、可控文生图/定制化文生图
17、DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
大型文本生成图像模型已取得显著进展,有能力从给定的文本提示中生成高质量和多样化的图像。然而,给定目标个体的一些参考图片(这里不妨称之为“主题”),这些模型还无法做到的是,在不同的上下文环境里去生成关于它们不同图片的能力。
DreamBooth是一种新的文本到图像扩散模型的“个性化”方法。给定一个主题的几张图像作为输入,对预训练的文本到图像模型进行微调,使其学会将一个唯一标识符(identifier)绑定到特定的主题。一旦主题被嵌入到模型的输出域中,唯一的标识符就可以用来生成不同场景下关于主题的新颖逼真图像。通过利用模型中嵌入的语义先验和一种类特定先验保留损失,能够在参考图像中没有出现的不同场景、姿势、视图和光照条件下合成主题。
在保留主题关键特征的同时,应用于主题重新背景化、文本引导的视图合成和艺术渲染等任务。此外,研究者还为这个新的主题驱动生成任务提供了一个新的数据集和评估协议。项目页面:https://dreambooth.github.io/

18、Ablating Concepts in Text-to-Image Diffusion Models
大规模的文本到图像扩散模型可以生成高保真图像。 模型通常是根据大量互联网数据进行训练的,这些数据通常包含受版权保护的材料、许可图像和个人照片。 此外,它们被发现可以复制各种艺术家的风格或记住准确的训练样本。 如何在不从头开始重新训练模型的情况下删除此类受版权保护的概念或图像?
为了实现这一目标,提出了一种在预训练模型中消除概念的有效方法,即防止目标概念的生成。 算法将希望消融的目标样式、实例或文本提示的图像分布与锚概念对应的分布相匹配。 这可以防止模型在给定文本条件的情况下生成目标概念。 大量实验表明,方法可以成功地防止消除概念的产生,同时在模型中保留密切相关的概念。

19、Multi-Concept Customization of Text-to-Image Diffusion
生成模型从大型数据库中学习到概念,但用户通常希望合成他们自己的概念(例如,他们的家人、宠物或物品)的实例。 可以教一个模型快速获得一个新概念吗? 可以将多个新概念组合在一起吗?
本文提出了 Custom Diffusion,一种增强现有文本到图像模型的有效方法。 仅优化文本到图像调节机制中的几个参数就足以代表新概念,同时实现快速调整(∼ 6 分钟)。
此外,可以联合训练多个概念,或通过闭式约束优化将多个微调模型组合成一个。 经过微调的模型生成多个新概念的变体,并将它们与新设置中的现有概念无缝组合。 方法在定性和定量评估方面优于多个基线和并行工作,同时具有内存和计算效率。

20、Imagic: Text-Based Real Image Editing with Diffusion Models
以文本为条件的图像编辑最近引起了相当大的兴趣。然而,目前大多数方法要么仅限于特定的编辑类型(例如,目标融合叠加、风格迁移),要么适用于合成生成的图像,或者需要一个公共对象的多个输入图像。
本文首次展示了将复杂(例如,非刚性)文本引导语义编辑应用于单个真实图像的能力。例如,可以改变图像中一个或多个对象的姿势和构图,同时保留其原始特征。方法可以让站立的狗坐下或跳跃,让鸟张开翅膀等等——每一个都在用户提供的单个高分辨率自然图像中。
与以前的工作相反,提出的方法只需要一个输入图像和一个目标文本(所需的编辑)。使用真实图像,不需要任何额外的输入(例如图像掩码或对象的额外视图)。方法称之为“Imagic”,利用预训练的文本到图像扩散模型来完成这项任务。它生成与输入图像和目标文本对齐的文本嵌入,同时微调扩散模型以捕获特定于图像的外观。
在来自不同领域的大量输入上展示了方法的质量和多功能性,展示了大量高质量的复杂语义图像编辑。
https://imagic-editing.github.io/

21、Shifted Diffusion for Text-to-image Generation
本文提出了一种新的文本到图像生成方法Corgi。Corgi基于本文出的shifted扩散模型,从输入文本中实现了更好的图像特征嵌入生成。与在DALL-E 2中使用的基线扩散模型不同,方法通过设计新的初始化分布和新的扩散步骤,无缝地编码预训练的CLIP模型在扩散过程中的先验知识。
与强DALL-E 2基线相比,方法在从文本生成图像嵌入方面的效率和有效性都更好,从而获得更好的文本到图像生成。进行了大量的大规模实验,从定量测量和人工评价两方面进行了评价,表明方法比现有方法具有更强的生成能力。
此外,模型支持半监督和无语言的文本到图像生成训练,其中训练数据集中只有部分或没有图像具有相关的文本描述。半监督模型在只有1.7%的图像被配上文本的情况下进行训练,在MS-COCO上评估零镜头文本到图像生成时,得到的FID结果与DALL-E 2相当。Corgi还在下游无语言文本到图像生成任务的不同数据集上获得了最新的结果,大大超过了之前的Lafite方法。

22、SpaText: Spatio-Textual Representation for Controllable Image Generation
最近的文本到图像扩散模型能够以前所未有的质量生成令人信服的结果。然而,当前方法无法以精细控制不同区域/对象的形状或它们的布局。以前提供此类的尝试,却因依赖标签而有所受限制。
为此,本文提出了 SpaText,一种使用开放式词汇场景控制、进行文本到图像生成的新方法。除了描述整个场景的全局文本外,用户还提供了一个分割图,其中每个感兴趣的区域都用自由形式的自然语言描述进行了注释。由于缺乏对图像中每个区域进行详细文本描述的大规模数据集,选择利用当前的大规模文本到图像数据集,并将方法基于一种新的基于 CLIP 的空间文本表示,并展示其在两种最先进的扩散模型上的有效性:基于像素和基于潜在。
此外,展示了如何将扩散模型中的无分类器指导方法扩展到多条件情况,并提出了一种替代加速推理算法。最后,除了 FID 分数和用户研究之外,还提供了几个自动评估指标并评估方法。
https://omriavrahami.com/spatext/

23、Scaling up GANs for Text-to-Image Synthesis
最近,文字-图像生成技术的成功已经席卷全球,激发了大众的想象力。从技术的角度来看,它也标志着设计生成图像模型所青睐的架构的巨大变化。GANs曾经是事实上的选择,有StyleGAN这样的优秀技术。随着DALL·e2的出现,自回归和扩散模型似乎一夜之间成为大规模生成模型的新标准。
这种快速的转变提出了一个基本问题:能否扩大GANs的规模,从像LAION这样的大型数据集中受益?本文发现,随意增加StyleGAN架构的容量很快就会变得不稳定。因此提出了一种新的GAN架构GigaGAN,它远远超过了这一限制,证明了GAN是文本到图像生成的可行选择。
GigaGAN有三大优势。首先,它的推理速度快了几个数量级,合成一张512px的图像只需要0.13秒。其次,它可以在3.66秒内合成高分辨率图像,例如1600万像素的图像。最后,GigaGAN支持各种潜在空间编辑应用程序,如潜在插值、风格混合和其它编辑操作。

24、GALIP: Generative Adversarial CLIPs for Text-to-Image Synthesis
为了同时实现生成质量高、训练高效、生成速度快,以及内容更可控的文本到图像生成模型,作者提出了 Generative Adversarial CLIPs,即 GALIP。
GALIP首先提出了一个基于 CLIP 的判别器。CLIP的复杂场景理解能力使判别器能够更加准确地评估复杂图像的质量。此外,还提出了一个 CLIP增强的生成器,它通过Bridge Feature和Prompts从 CLIP 中抽取有用的视觉概念。集成 CLIP 的生成器和判别器提高了对抗学习效率,使得GALIP只需要大约 3% 的训练数据和 6% 的可学习参数,仅用8张3090显卡训练3天时间,取得了与大规模预训练的自回归和扩散模型相当的结果。同时,GALIP的生成速度也快了120倍,且继承了GAN更加可控的平滑隐空间。实验结果证明GALIP的卓越性能。(https://github.com/tobran/GALIP)

25、Variational Distribution Learning for Unsupervised Text-to-Image Generation
当训练期间图像的文本不可用时,本文提出了一种基于深度神经网络的文本到图像生成算法。 这项工作不是简单地使用现有的图像文本描述生成方法生成训练图像的伪句子,而是使用预训练的 CLIP 模型,该模型能够在联合空间中正确对齐图像和相应文本的嵌入,因此, 在零样本识别任务上效果很好。
通过最大化以图像-文本 CLIP 嵌入对为条件的数据对数似然来优化文本到图像生成模型。 为了更好地对齐两个域中的数据,采用了一种基于变分推理方法,可以有效地估计给定图像及其 CLIP 特征的隐藏文本嵌入的近似后验。 实验结果证实,在无监督和半监督的文本到图像生成设置下,所提出的框架大大优于现有方法。

四、图像恢复
26、Bitstream-Corrupted JPEG Images are Restorable: Two-stage Compensation and Alignment Framework for Image Restoration
本文研究JPEG图像恢复问题,即加密比特流中的比特错误。比特错误会导致解码后的图像内容出现不可预测的色偏和块位移,这些问题无法通过现有的主要依赖于像素域中预定义退化模型的图像恢复方法来解决。为了解决这些挑战,提出了一个强健的JPEG解码器,并采用两阶段补偿和对齐框架来恢复受比特流损坏的JPEG图像。
具体而言,JPEG解码器采用了一种具有容错机制的方法来解码受损的JPEG比特流。两阶段框架由自补偿和对齐(SCA)阶段和引导补偿和对齐(GCA)阶段组成。SCA阶段基于图像内容相似性和估计的颜色和块偏移量,自适应地对图像颜色进行块状补偿和对齐。GCA阶段利用从JPEG头中提取的低分辨率缩略图来指导全分辨率像素级图像恢复,通过粗到细的方式实现。它由一个粗略引导的pix2pix网络和一个细化引导的双向拉普拉斯金字塔融合网络实现。
在三个不同比特错误率的基准测试上进行了实验。实验结果和消融研究表明了我们所提出的方法的优越性。代码在 https://github.com/wenyang001/Two-ACIR

27、Contrastive Semi-supervised Learning for Underwater Image Restoration via Reliable Bank
尽管最近的水下图像恢复技术取得了显著成就,但标注数据的缺乏已成为进一步进展的主要障碍。本研究提出了一种基于mean-teacher的半监督水下图像恢复(Semi-UIR)框架,将未标记的数据纳入网络训练。然而,朴素的mean-teacher方法存在两个主要问题:(1)训练中使用的一致性损失可能在教师的预测错误时变得无效。(2)使用L1距离可能会导致网络过度拟合错误的标签,导致确认偏差。
为了解决上述问题,首先引入一个可靠的bank来存储“最佳”的输出作为伪基础事实。为了评估输出的质量,基于单调性属性进行实证分析,选择最可信的NR-IQA方法。此外,针对确认偏差问题,还引入对比正则化以防止对错误标签的过拟合。在全参考和非参考水下基准测试上的实验结果表明,算法在定量和定性上都比SOTA方法有明显的改进。
代码在https://github.com/Huang-ShiRui/Semi-UIR

28、Efficient and Explicit Modelling of Image Hierarchies for Image Restoration
本文的目的是提出一种机制,以有效地和明确地建模图像恢复的全局、区域和局部层次结构。
为了实现这一目标,首先分析了自然图像的两个重要属性,包括跨尺度相似性和各向异性图像特征。在此启发下,提出了锚定条纹自注意力机制,它在自注意力的空间和时间复杂度和区域范围之外的建模能力之间取得了良好的平衡。
然后,提出了一种名为GRL的新网络结构,通过锚定条纹自注意力、窗口自注意力和通道注意力增强卷积,明确地建模图像的全局、区域和局部层次结构。
最后,将所提出的网络应用于7种图像恢复类型,包括真实和合成设置。所提出的方法为其中的几种设定设立了新的技术标准。
代码在https://github.com/ofsoundof/GRL-ImageRestoration.git

29、Generating Aligned Pseudo-Supervision from Non-Aligned Data forImage Restoration in Under-Display Camera
Under-Display Camera (UDC)图像修复任务,由于收集大规模且完全对齐的配对训练数据的困难,之前的方法采用基于监视器的图像系统或基于模拟的方法,牺牲了数据的真实性并引入了域差异。
本文重新考虑了经典的立体设置用于训练数据的收集——使用一个UDC和一个标准相机捕获同一场景的两个图像。关键思想是从高质量的参考图像中“复制”细节并将其“粘贴”到UDC图像中。虽然能够生成真实的训练配对,但由于透视和景深的变化,该设置容易出现空间不对齐的问题。该问题进一步加剧了UDC和正常图像之间的大域差异,这是UDC修复所特有的。
本文通过一种基于Transformer的框架,通过两个精心设计的组件,即域对齐模块(DAM)和几何对齐模块(GAM),来缓解非常规域差异和空间不对齐的问题,这有助于鼓励鲁棒和准确地发现UDC和正常视图之间的对应关系,并生成对应UDC输入的高质量、对齐的目标数据。实验表明,高质量和对齐的伪UDC训练配对有助于训练鲁棒的修复网络。
代码和数据集在https://github.com/jnjaby/AlignFormer

30、 Learning Semantic-Aware Knowledge Guidance for Low-Light Image Enhancement
低光图像增强(Low-light image enhancement ,LLIE)研究如何改善照明并产生正常光照的图像。现有的大多数方法通过全局和均匀的方式改善低光图像,而不考虑不同区域的语义信息。没有语义先验,网络可能会轻易偏离区域的原始颜色。
为了解决这个问题,提出了一个新的语义感知知识引导框架(semantic-aware knowledge-guided framework ,SKF),可以帮助低光增强模型学习包含在语义分割模型中的丰富多样的先验知识。专注于从三个关键方面融合语义知识:一个智能地在特征表示空间中集成语义先验的语义感知嵌入模块,一个保留各种实例颜色一致性的语义引导颜色直方图损失,以及语义引导的对抗性损失可通过语义先验产生更自然的纹理。
实验表明,配备 SKF 的模型在多个数据集上的表现明显优于基线,SKF可以很好地泛化到不同的模型和场景。代码在 https://github.com/langmanbusi/Semantic-Aware-Low-Light-Image-Enhancement

31、Refusion: Enabling Large-Size Realistic Image Restoration with Latent-Space Diffusion Model
本研究旨在提高扩散模型在实际图像恢复中的适用性。具体而言,从网络结构、噪声水平、去噪步骤、训练图像大小和优化器/调度器等多个方面增强了扩散模型。
调整这些超参数可以在失真和感知得分上实现更好的性能。还提出了一种基于U-Net的潜在扩散模型,它在低分辨率潜在空间中执行扩散,同时保留来自原始输入的高分辨率信息用于解码过程。与先前训练VAE-GAN来压缩图像的潜在扩散模型相比,提出的U-Net压缩策略更加稳定,并且可以在不依赖对抗性优化的情况下恢复高度精确的图像。
重要的是,这些修改能够将扩散模型应用于各种图像恢复任务,包括现实世界的阴影去除、高分辨率非均匀去雾、立体超分辨率和浅景深效果转换。通过简单地更换数据集并稍微更改噪声网络,模型Refusion能够处理大尺寸图像(例如HR去雾中的6000×4000×3)并在所有以上恢复问题上产生良好的结果。Refusion在NTIRE 2023图像阴影去除挑战赛中实现了最佳的感知性能,并获得了总体第二名。
https://github.com/Algolzw/image-restoration-sde

32、Robust Model-based Face Reconstruction through Weakly-Supervised Outlier Segmentation
通过避免将模型拟合到异常值(如遮挡物或化妆品这种无法很好地被模型表达的区域),提高基于模型的人脸重建的质量。局部异常值的核心挑战在于,它们高度变化且难以标注。
为了克服这个困难,引入了一种联合人脸自编码器和异常值分割方法(FOCUS)。具体而言,利用异常值不能很好地适配人脸模型这一事实,因此在给定高质量的模型拟合的情况下可以很好地定位异常值。主要的挑战在于模型拟合和异常值分割相互依赖,需要一起推断。通过EM类型的训练策略,其中人脸自编码器与异常值分割网络一起进行训练。这产生了一种协同作用,即分割网络防止人脸编码器拟合异常值,提高了重建质量。改进的3D人脸重建,反过来又使分割网络更好地预测异常值。
为了解决异常值和难以拟合的区域之间的模糊性,如眉毛,从合成数据中建立一个统计先验,以测量模型拟合中的系统偏差。在NoW测试集上的实验表明,FOCUS在没有3D注释的所有基线中实现了SOTA的3D人脸重建性能。此外,在CelebA-HQ和AR数据库上的结果表明,分割网络可以准确地定位遮挡物,尽管没有任何分割标签。
https://github.com/unibas-gravis/Occlusion-Robust-MoFA

33、Robust Unsupervised StyleGAN Image Restoration
基于 GAN 的图像恢复,修复因已知退化而损坏的图像。 现有的无监督方法必须针对每个任务和退化级别仔细调整。 在这项工作中,使 StyleGAN 图像恢复具有鲁棒性:一组超参数适用于各种退化水平。 这使得处理多种降级的组合成为可能,而无需重新调整。
提出的方法依赖于三阶段渐进潜在空间扩展和优化器,这避免了对任何额外正则化项的需要。 大量实验证明了在不同退化水平下修复、上采样、去噪和去伪像的稳健性,优于其他基于 StyleGAN 的技术。

五、布局可控生成
34、LayoutDiffusion: Controllable Diffusion Model for Layout-to-image Generation
最近,扩散模型在图像生成方面取得了巨大的成功。然而,当涉及到布局生成时,由于图像通常包含多个物体的复杂场景,如何对全局布局图和每个详细对象进行强大的控制仍然是一个具有挑战性的任务。
本文提出LayoutDiffusion扩散模型,可以获得比以前方法更高的生成质量和更大的可控性。为了克服图像和布局的难以多模态融合,提出构造具有区域信息的结构图像块,并将该图像块转换为特殊布局,以与普通布局统一形式进行融合。此外,提出了布局融合模块(Layout Fusion Module,LFM)和物体感知交叉关注(Object-aware Cross Attention,OaCA),用于对多个物体之间的关系进行建模,旨在具有物体感知和位置敏感性,可以精确控制空间相关信息。
大量实验表明,LayoutDiffusion在FID、CAS上相对于以前的SOTA方法分别提高了46.35%、26.70%在COCO-stuff上分别提高了44.29%、41.82%的性能。
代码在https://github.com/ZGCTroy/LayoutDiffusion

35、LayoutDM: Discrete Diffusion Model for Controllable Layout Generation
可控布局生成(Controllable layout generation),旨在生成元素边界框的合理排列,还要在可选的约束下,例如特定元素的类型或位置。
这项工作尝试在单个模型中解决广泛的布局生成任务,该模型基于离散状态空间扩散模型。模型名为LayoutDM,处理离散表示中的结构化布局数据,并逐步从初始输入推断出无噪声的布局,其中通过分模态离散扩散来模拟布局破坏过程。对于条件生成,在推断过程中以屏蔽或逻辑调整的形式注入布局约束。
实验结果表明,LayoutDM成功生成了高质量的布局,并在几个布局任务上优于特定任务和非特定任务的基线。
https://cyberagentailab.github.io/layout-dm/

36、PosterLayout: A New Benchmark and Approach for Content-aware Visual-Textual Presentation Layout
内容感知的视觉-文本呈现布局旨在为预定义的元素(包括文本、标志和底层)在给定的画布上安排空间,这是自动无模板创意图形设计的关键。在实际应用中,如海报设计,画布最初是非空的,生成适当的布局时应同时考虑元素间关系和层间关系。近期的一些研究同时处理这两个问题,但仍然存在图形性能差的问题,如缺乏布局变化或空间不对齐。
由于内容感知的视觉-文本呈现布局是一个新的任务,首先构建了一个名为PKU PosterLayout的新数据集,它由9,974个海报布局对和905张图像,即非空画布组成。该数据集更具挑战性和实用性,具有更大的布局多样性、域多样性和内容多样性。
然后,提出了设计序列形成(DSF)方法,以模拟人类设计师的设计过程重新组织布局中的元素,并提出了一种基于CNN-LSTM的条件生成对抗网络(GAN)来生成适当的布局。具体来说,鉴别器是设计序列感知的,将监督生成器的“设计”过程。
实验结果验证了新基准的有用性和所提出方法的有效性,该方法通过为不同的画布生成适当的布局实现了最佳性能。数据集和源代码在 https://github.com/PKU-ICSTMIPL/PosterLayout-CVPR2023

37、Unifying Layout Generation with a Decoupled Diffusion Model
布局生成,旨在生成具有不同属性的元素的真实图形场景,包括类别、大小、位置和元素间关系。对于格式化场景(例如出版物、文档和用户界面(UI))来说,这是减轻图形设计工作负担的关键任务。在各种应用场景下统一各种布局生成任务,包括条件和非条件生成方面,提出了巨大的挑战。
本文提出一个名为LDGM(Layout Diffusion Generative Model)的布局扩散生成模型。LDGM将具有任意缺失或粗糙元素属性的布局视为从已完成布局的中间扩散状态。由于不同的属性具有其个体语义和特征,提出为它们分离扩散过程,以提高训练样本的多样性,并联合学习反向过程以利于生成全局范围上下文。
LDGM可以从头开始生成布局,也可以根据任意可用属性进行条件生成。广泛的定量和定性实验验证了提出的LDGM在功能和性能方面,均优于现有的布局生成模型。

38、Unsupervised Domain Adaption with Pixel-level Discriminator for Image-aware Layout Generation
布局对于图形设计和海报生成非常重要。最近,应用深度学习模型生成布局越来越受到关注。本文专注于使用基于GAN的模型,在图像内容的条件下生成广告海报的图形布局。
需要一个带有成对产品图像和图形布局的广告海报布局数据集。然而,现有数据集中的成对图像和布局是通过修补和标注海报收集的,存在修补海报(源域数据)和干净产品图像(目标域数据)之间的领域差距。因此,本文结合无监督的领域自适应技术,设计了一种具有新型像素级鉴别器(PD)的GAN,称为PDA-GAN,以根据图像内容生成图形布局。PD连接到浅层级别的特征图并计算每个输入图像像素的GAN损失。
定量和定性评估均表明,PDAGAN可以实现最先进的性能并为广告海报生成高质量的图像感知的图形布局。

六、医学图像
39、High-resolution image reconstruction with latent diffusion models from human brain activity
从人类脑活动中重构视觉体验,为我们理解大脑如何表示世界提供了独特的方式,同时也解释了计算机视觉模型与我们视觉系统之间的联系。尽管最近有研究工作使用深度生成模型来完成这项任务,但重构具有高语义保真度的逼真图像仍然是一个具有挑战性的问题。
本文提出一种基于扩散模型(DM)的新方法,通过功能性磁共振成像(functional magnetic resonance imaging,fMRI)从人脑活动来重构出图像。更具体地说,依赖Stable Diffusion的潜在扩散模型(LDM),该模型降低了DM的计算成本,同时保持了其高生成性能。通过研究LDM的不同组成部分(例如图像的潜在向量Z、条件输入C以及去噪U-Net的不同元素)与不同的脑功能之间的关系,表征了LDM的内部机制。
方法可以在简单的方式下重构具有高保真度的高分辨率图像,而不需要任何额外的训练和精调复杂的深度学习模型。还提供了从神经科学角度对不同LDM组件的定量解释。总体而言,研究提出了一种重构人类脑活动中图像的有前途的方法,并为理解DM提供了新的框架。网页https://sites.google.com/view/stablediffusion-withbrain/

40、 Leveraging GANs for data scarcity of COVID-19: Beyond the hype
基于人工智能(AI)的模型可以帮助通过肺CT扫描和X射线图像诊断COVID-19;然而,这些模型需要大量的数据进行训练和验证。许多研究人员研究了生成对抗网络(GANs)来生成合成肺CT扫描和X射线图像,以提高基于AI的模型的性能。目前并不清楚基于GAN的方法的生成可靠性如何。本文分析了43篇报告GANs用于合成数据的研究,其中许多研究存在数据偏差、缺乏可重复性和缺乏来自放射学家或其他领域专家的反馈。这些研究中的一个普遍问题是源代码不可用,从而妨碍了可重复性。
尽管基于 GAN 的方法具有数据增强和改进基于 AI 模型的训练的潜力,但这些方法在临床实践中的使用方面存在不足。 本文重点介绍了应对数据稀缺问题的研究热点,确定了各种问题和潜力,并提出了指导未来研究的建议。 这些建议可能有助于提高基于 GAN 的数据增强方法的可接受性,因为用于数据增强的 GAN 在 AI 和医学成像研究社区中越来越受欢迎。

41、Why is the winner the best?
国际计算机视觉竞赛已成为图像分析方法比较性能评估的平台。 然而,很少有人关注调查可以从这些比赛中学到什么。 它们真的会带来科学进步吗? 什么是常见且成功的参与策略? 是什么使解决方案优于竞争方法?
本文对在 IEEE ISBI 2021 和 MICCAI 2021 范围内进行的所有 80 场比赛进行了多项研究。统计分析基于提交算法进行,与其排名以及潜在的参与策略,揭示了获胜解决方案的共同特征。 这些通常包括使用多任务学习 (63%) 和/或多阶段管道 (61%),以及对增强 (100%)、图像预处理 (97%)、数据管理 (79%) 的关注, 和后处理 (66%)。 获胜团队的“典型”领导者是拥有博士学位、五年生物医学图像分析经验和四年深度学习经验的计算机科学家。 两个核心的通用开发策略在排名靠前的团队中脱颖而出:方法设计中指标的反映以及对失败案例分析和处理的关注。
据组织者称,43% 的获胜算法超过了最先进的水平,但只有 11% 完全解决了各自领域的问题。 本文研究可以帮助研究人员 (1) 在处理新问题时改进算法开发策略,以及 (2) 关注这项工作揭示的开放研究问题。

45、Solving 3D Inverse Problems using Pre-trained 2D Diffusion Models
扩散模型已经成为具有高质量样本的新一代最佳生成模型,具有不错的优势,如模式覆盖和高灵活性。它们还被证明可以有效地解决逆问题,作为分布的先验,而前向模型的信息可以在采样阶段获得。然而,由于生成过程仍然处于相同的高维空间(即与数据维数相同),因此这些模型尚未扩展到3D逆问题(3D inverse problem),因为其极高的内存和计算成本。
这篇论文中,将传统的基于模型的迭代重建的想法与现代扩散模型相结合,构建了一种在解决3D医学图像重建任务(如稀疏视图断层扫描、有限角度断层扫描和压缩感测MRI)方面非常有效的方法,这些任务是从预先训练的2D扩散模型中得出的。本质上,在测试时通过2D扩散先验与基于模型的先验来增强剩余方向,从而实现所有维度的连贯重建。
方法可以在单个消费级GPU上运行,并确立了新的最佳实践方法,表明所提出的方法能够在最极端的情况下(如2视图3D断层扫描)实现高保真和准确的重建。进一步揭示,所提出方法的泛化能力非常之高,可用于重建与训练数据集完全不同的volume。

七、人脸相关
46、A Hierarchical Representation Network for Accurate and Detailed Face Reconstruction from In-The-Wild Images
受到3DMM低维表示能力的限制,大多数基于3DMM的面部重建( face reconstruction,FR)方法无法恢复高频面部细节,如皱纹、酒窝等。有人尝试通过引入细节图或非线性操作来解决这个问题,然而,结果仍不是很生动。
为此,本文提出一种新的分层表示网络(hierarchical representation network,HRN),以实现从单幅图像中进行精确和详细的面部重建。具体来说,实现了几何解耦,引入分层表示来实现详细的面部建模。同时,引入3D面部细节的先验知识,以提高重建结果的准确性和真实性。
还提出了一个去修饰模块,以实现几何和外观的更好解耦。值得注意的是,通过考虑不同视角的细节一致性,可以扩展到多视角方式。两个单视角和两个多视角FR基准上的大量实验表明,方法在重建精度和视觉效果方面优于现有方法。
最后,引入了一个高质量的3D人脸数据集FaceHD-100,以推动高保真面部重建的研究。项目主页地址为https://younglbw.github.io/HRN-homepage/

47、DR2: Diffusion-based Robust Degradation Remover for Blind Face Restoration
盲面部修复(Blind face restoration)通常使用预定义的退化模型将退化的低质量数据为训练数据,而在现实世界中可能发生更复杂的情况。和实际退化之间的差距,对修复性能造成影响,输出结果中常常观察到伪影。然而,在训练数据中包含所有类型的退化,想足以覆盖现实世界的情况,是昂贵的且不可行的。
为了解决这个鲁棒性问题,提出了基于扩散的鲁棒退化去除器(Diffusion-based Robust Degradation Remover,DR2),首先将退化图像转换为粗糙但不受退化影响的预测,然后采用增强模块将粗糙预测恢复为高质量图像。通过利用性能优越的去噪扩散概率模型,DR2将输入图像扩散到嘈杂状态,各种类型的退化让位于高斯噪声,然后通过迭代去噪步骤捕获语义信息。因此,DR2对常见退化(如模糊、调整大小、噪声和压缩)具有鲁棒性,并且与不同设计的增强模块相兼容。
各种设定下的实验表明,在严重退化的合成和现实世界数据集上优于当前最优秀的方法。

48、DiffusionRig: Learning Personalized Priors for Facial Appearance Editing
解决从少量同一个人的肖像照片(例如,20 张])中学习个人特定面部先验的问题。这使我们能够编辑这个特定人的面部表情,如表情和光照,同时保留他们的身份和高频面部细节。
提出DiffusionRig,基于扩散模型,由自然场景下的单图像中估计的粗糙的 3D 人脸模型条件。在高层次上,DiffusionRig 学会将简单的 3D 人脸模型渲染为给定人物的真实照片。具体来说,DiffusionRig 分两阶段进行训练:首先从大规模脸部数据集中学习通用的面部先验,然后从感兴趣的人物的一小部分肖像照片集中学习个人特定的先验。通过学习这种个性化的先验中的 CGI-to-photo 映射,仅仅在粗糙的 3D 模型条件下,DiffusionRig 可以“操纵”肖像照片的光照、面部表情、头部姿势等,同时保留这个人的身份和其他高频特征。
定性和定量实验表明,DiffusionRig 在身份保护和照片写实方面均优于现有方法。详细的补充材料、视频、代码和数据网站:https://diffusionrig.github.io
49、Fine-Grained Face Swapping via Regional GAN Inversion
提出一种新的高保真换脸范式,能够保留期望的微妙几何和纹理细节。从微观面部编辑的角度重新思考换脸任务,基于“编辑用于互换(editing for swapping)”(E4S)的原则,提出了一种基于面部组件形状和纹理的显式解耦方法。
遵循E4S原则,实现面部特征的全局和局部互换,以及由用户指定的部分互换。此外,E4S范式通过面部遮罩固有地处理面部遮挡问题。核心是一种新的区域GAN逆映射(RGI)方法,它允许显式解耦形状和纹理,同时允许在StyleGAN的潜在空间中进行面部互换。具体来说,设计了一个多尺度遮罩引导编码器,将每个面部组件的纹理投影到区域样式码中。还设计了一个遮罩引导注入模块,用样式码操作特征映射。基于解耦,面部互换被重新制定为样式和遮罩互换的简化问题。
与现有技术的大量实验和比较表明,方法在保留纹理和形状细节方面以及处理高分辨率图像方面具有优越性。项目页面地址为https://e4s2022.github.io

50、SunStage: Portrait Reconstruction and Relighting using the Sun as a Light Stage
光照舞台使用一系列校准相机和灯光,以不同照明和视图下捕捉对象的面部外观。这些捕获的信息对于面部重建和重照至关重要。不幸的是,光照舞台往往无法获取:它们代价昂贵并且需要大量的技术专业知识来建造和操作。
本文提出SunStage:一种轻量级替代光照舞台的方法,仅使用智能手机相机和太阳捕捉可比较的数据。方法只需要用户在户外拍摄一段自拍视频,原地旋转,并使用太阳和脸之间的变化角度来指导面部几何建模,反射率、摄像机姿势和照明参数的联合重建。
尽管在野外未校准的环境中,方法能够重建详细的面部外观和几何形状,实现诸如重照、新视图合成和反射率编辑等引人注目的效果。

八、3D相关
51、3DQD: Generalized Deep 3D Shape Prior via Part-Discretized Diffusion Process
提出一个通用的3D形状生成先验模型,专为多种3D任务量身定制,包括无条件形状生成、点云补全和跨模态形状生成等。
一方面,为了精确捕捉局部细节形状信息,利用VQ-VAE来索引基于广泛任务训练数据的紧凑codebook中的局部几何。另一方面,引入离散扩散生成器以模拟不同token之间的固有结构依赖关系。
同时,开发了一种多频融合模块(multi-frequency fusion module,MFM),以多频上下文信息为指导,抑制高频形状特征波动。让3D形状先验模型拥有高保真、多样化特征以及跨模态对齐能力,大量实验已证明了其在各种3D形状生成任务上的优越性能。
https://github.com/colorful-liyu/3DQD

52、Controllable Mesh Generation Through Sparse Latent Point Diffusion Models
网格生成(Mesh generation)在涉及计算机图形和虚拟内容的各种应用中具有很高的价值,但由于Mesh的不规则数据结构和同类别Mesh的不一致拓扑,为Mesh设计生成模型具有挑战性。
这项工作为Mesh生成设计了一种新的稀疏潜在点扩散模型。关键是将点云视为Mesh的中间表示,并对点云的分布进行建模。为了提高生成方法的效率和可控性,进一步将点云编码为具有逐点语义有意义特征的稀疏潜在点集,其中两个DDPM分别在稀疏潜在点空间中训练以分别模拟潜在点位置的分布以及这些潜在点处的特征。在这个潜在空间中采样要比直接采样密集点云快。
此外,稀疏潜在点还能显式控制生成Mesh的整体结构和局部细节。在ShapeNet数据集上进行了大量实验,提出的稀疏潜在点扩散模型在生成质量和可控性方面实现了与现有方法相比的优越性能。项目页面,代码和附录:https://slide-3d.github.io

53、GD-MAE: Generative Decoder for MAE Pre-training on LiDAR Point Clouds
尽管在开发视觉任务如图像和视频方面,Masked Autoencoders(MAE)取得了巨大进步,但由于固有的不规则性,探索大规模3D点云中的MAE仍然具有挑战性。与之前的3D MAE框架相比(设计复杂的解码器从维护区域推断掩蔽信息或采用复杂的掩蔽策略),提出了一种更简单的范例。
核心思想是应用生成解码器MAE(GD-MAE)自动将周围上下文合并,以按层次融合方式恢复掩蔽的几何知识。这样做,方法不需要引入解码器的启发式设计,并且可以灵活地探索各种掩蔽策略。相应的部分在与传统方法相比的延迟中减少不到12%,同时实现更好的性能。
展示了该方法在几个大型基准(Waymo、KITTI和ONCE)上得到的效果。在下游检测任务中持续改进,说明了强大的鲁棒性和泛化能力。方法展示了最先进的结果,值得注意的是,即使在Waymo数据集上只有20%的标记数据,也实现了可比拟的准确性。代码在https://github.com/Nightmare-n/GD-MAE

54、GINA-3D: Learning to Generate Implicit Neural Assets in the Wild
从传感器数据中模拟3D世界,是为诸如自动驾驶等机器人学习问题开发测试和验证环境的可扩展方法。然而,手动创建或重新创建类似真实世界的环境困难、昂贵且无法扩展。最近的生成模型技术通过仅使用大量的2D图像学习3D资源来取得了有望解决这类挑战的进展,但仍然具有局限性,因为它们利用的是人类策划的图像数据集或手动创建的合成3D环境的渲染。
本文介绍GINA-3D,一种生成模型,它使用来自摄像头和LiDAR传感器的真实驾驶数据创建真实的3D,包括多样化的车辆和行人。与现有图像数据集相比,真实世界驾驶环境由于遮挡、光照变化和长尾分布带来了新的挑战。GINA-3D通过将表示学习和生成建模分解为两个阶段,并借鉴最近在图像生成建模方面的进展,采用了一种学习的三平面潜在结构来应对这些挑战。
为了评估方法,构建了一个大型对象中心数据集,包含来自Waymo开放数据集的超过520K辆车辆和行人的图像,以及一组新的8万张长尾实例图像,如施工设备、垃圾车和缆车。将模型与现有方法进行比较,并证明它在生成的图像和几何方面的质量和多样性方面实现了最先进的性能。

55、Graphics Capsule: Learning Hierarchical 3D Face Representations from 2D Images
构建对象层次结构,对于人脑视觉过程非常重要。以前的研究已经成功地采用胶囊网络将digits和面部分解为部件,以无监督的方式研究神经网络中类似的感知机制。然而,它们的描述仅限于2D空间,限制了它们模仿人类固有的3D感知能力。
本文提出一种逆图形胶囊网络(Inverse Graphics Capsule Network,IGC-Net),用于从大规模未标记图像中学习分层3D人脸表示。 IGC-Net的核心是一种新型胶囊,名为图形胶囊,它以计算机图形(CG)中的可解释参数表示3D图元,包括深度、反照率和3D姿态。
具体而言,IGC-Net首先将对象分解成一组语义一致的部分级描述,然后将它们组装成对象级描述以构建层次结构。学到的图形胶囊揭示了面向视觉感知的神经网络如何将面孔理解为3D模型的层次结构。此外,发现的部件可以部署到无监督的人脸分割任务中,以评估方法的语义一致性。此外,具有显式物理含义的部分级描述为原本在黑匣子中运行的面部分析提供了见解,例如形状和纹理对于面部识别的重要性。 CelebA, BP4D 和 Multi-PIE 上的实验展示了IGC-Net。

56、HOLODIFFUSION: Training a 3D Diffusion Model using 2D Images
扩散模型已经成为2D图像生成建模的最佳方法。它们的成功部分原因是可以利用稳定的学习目标对数百万乃至数十亿图像进行训练。然而,将这些模型扩展到3D存在两个难点。首先,找到大量的3D训练数据要比2D图片复杂得多。其次,尽管在概念上将模型从2D扩展到3D非常简单,但相关的内存和计算复杂性的增长使其变得不切实际。
通过引入一种新的扩散设置来解决第一个挑战,该设置可以在端到端地使用已布局的2D图像进行监督;然后通过提出一种image formation模型来解决第二个挑战,该模型将模型内存与空间内存解耦。使用在 CO3D 数据集中尚未用于训练3D生成模型的真实世界数据来评估方法。
实验表明,它们具有可扩展性,训练稳定,并在样本质量和保真度方面与现有的3D生成建模方法具有竞争力。
https://holodiffusion.github.io/

57、Learning 3D-aware Image Synthesis with Unknown Pose Distribution
现有的3D感知图像合成方法很大程度上依赖于在训练集上预先估计的3D姿态分布。如果估计不准确,可能会误导模型去学习错误的几何信息。这项工作提出了PoF3D,它释放了生成辐射场对3D姿态先验的需求。
首先为生成器配置一种有效的姿态学习器,能够从一个潜在的编码中推断出姿态,以自动近似底层真实的姿态分布。接着,分配给鉴别器一个在生成器的监督下学习姿态分布的任务,并以预测的姿态作为条件区分实际和合成图像。姿态自由生成器和姿态感知鉴别器以对抗性的方式共同训练。
一系列数据集上的结果证实,方法在图像质量和几何质量方面的性能与最先进的方法相当。PoF3D首次证明了在不使用3D姿态先验的情况下学习高质量的3D感知图像合成的可行性。项目页面:https://vivianszf.github.io/pof3d/

58、Lift3D: Synthesize 3D Training Data by Lifting 2D GAN to 3D Generative Radiance Field
本文探讨了使用3D生成模型为3D视觉任务生成训练数据。生成模型的关键要求是生成数据应与现实世界场景相匹配的真实,并且相应的3D属性应该与给定的采样标签保持一致。然而,由于它们设计的生成管道和缺乏明确的3D监督,最近的基于NeRF的3D GANs几乎不能满足上述要求。
这项工作中,提出了Lift3D,一种逆过程的2D至3D生成框架,以实现数据生成目标。与先前的方法相比,Lift3D具有几个优点:(1)与先前的3D GAN输出分辨率在训练后固定不同, Lift3D 可以推广到具有更高分辨率和真实输出的任何相机内参数。 (2)通过将完全解耦的2D GAN提升到3D对象NeRF,Lift3D为生成的对象提供了显式的3D信息,从而为下游任务提供了准确的3D标注。
通过增强自主驾驶数据集来评估有效性。实验结果表明,数据生成可以有效地提高3D物体检测器的性能。项目页面:len-li.github.io/lift3d-web

59、Magic3D: High-Resolution Text-to-3D Content Creation
DreamFusion最近展示了使用预训练的文本到图像扩散模型优化神经辐射场(NeRF)的实用性,取得了显著的文本到3D合成效果。然而,该方法有两个固有的限制:(a)NeRF的优化极其缓慢,(b)对NeRF的低分辨率图像空间监督导致了质量较低的3D模型并且处理时间较长。
本文通过使用两阶段优化框架来解决这些限制。首先,利用低分辨率扩散先验和稀疏3D哈希网格结构得到粗糙模型。使用粗略表示作为初始化,利用高效的可微渲染器与高分辨率潜在扩散模型进行交互,进一步优化纹理3D网格模型。
方法称为Magic3D,可以在40分钟内创建高质量3D网格模型,速度比DreamFusion快2倍(据报道平均花费1.5小时),同时实现更高分辨率。用户研究显示,61.7%的受访者更倾向于本文方法而非DreamFusion。还为用户提供图像生成能力和新的3D合成控制方法,为各种创意应用开辟了新的途径。
https://research.nvidia.com/labs/dir/magic3d/

60、NeuFace: Realistic 3D Neural Face Rendering from Multi-view Images
从多视角图像进行真实感人脸渲染(face rendering),有利于各种计算机视觉和图形应用任务。然而,由于人脸具有复杂的空间变化的反射特性和几何特征,因此在当前的研究中,恢复3D人脸表示仍然具有挑战性。
本文提出了一种新的3D人脸渲染模型,即NeuFace,通过神经渲染技术学习精确和物理意义上有意义的底层3D表示。它自然地将神经BRDFs融入到基于物理的渲染中,以协作方式捕获复杂的面部几何和外观线索。具体来说,引入了一种近似的BRDF积分和一个简单而新的低秩先验,有效地降低了人脸BRDF的模糊性并提高了性能。大量实验证明了NeuFace在人脸渲染方面的优越性,以及在常见物体上的良好泛化能力。
代码已在NeuFace上发布:https://github.com/aejion/NeuFace

61、NeuralField-LDM: Scene Generation with Hierarchical Latent Diffusion Models
自动生成高质量真实世界的3D场景对于虚拟现实和机器人仿真等应用领域具有巨大的前景。为实现这一目标,引入了NeuralField-LDM,一种能够生成复杂3D环境的生成模型。
利用了已成功应用于高效高质量2D内容创建的潜在扩散模型(Latent Diffusion Models)。首先,训练一个场景自编码器,将一组图像和姿态对表示为神经场,表示为密度和特征体素网格,可以投影生成场景的新视图。为了进一步压缩这种表示,训练一个潜在自编码器,将体素网格映射到一组潜在表示。然后将分层扩散模型拟合到潜在中,以完成场景生成管道。
在现有技术水平上实现了显著的改进。展示了如何将NeuralField-LDM用于各种3D内容生成应用,包括条件场景生成、场景修补和场景风格编辑。
https://research.nvidia.com/labs/toronto-ai/NFLDM/

62、Next3D: Generative Neural Texture Rasterization for 3D-Aware Head Avatars
3D感知生成对抗网络(GANs)仅使用单视角2D图像合成高保真度和多视角一致的面部图像。为实现对面部属性的细粒度控制,近期的研究努力将3D形变人脸模型(3D Morphable Face Model,3DMM)纳入生成辐射场的显式或隐式描述中。显式方法提供细粒度的表达控制,但无法处理由头发和配饰引起的拓扑变化,而隐式方法可以建模各种拓扑,但由于不受约束的变形场,其适用范围有限。
提出了一种新的3D GAN框架,用于从无结构的2D图像中无监督学习生成高质量且具备3D一致性的面部形象。为实现变形精度和拓扑灵活性,提出了一种名为生成纹理光栅化三角面的3D表示。所提出的表示在参数化网格模板之上学习生成神经纹理,然后通过光栅化将它们投影到三个正交视角的特征平面上,形成一个三角面的体积渲染。这样,结合了网格引导的显式变形的细粒度表达控制和隐式体积表示的灵活性。进一步提出了用于建模不受3DMM影响的嘴部特定模块。
方法通过广泛的实验展示了最先进的3D感知合成质量和动画能力。此外,作为3D先验的可驱动3D表示在单样本人脸虚拟化和3D感知风格化等多个应用中起到了推动作用。
63、SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation
通过人脸图像和一段语音音频生成说话头像视频(talking head)仍然存在许多挑战。即,不自然的头部运动,扭曲的表情和身份修改。这些问题主要是因为从耦合的2D运动场中学习。另一方面,显式使用3D信息也遇到了表达僵硬和非连贯视频的问题。
提出了SadTalker,它从音频中生成3D运动系数(头部姿态,表情),并隐式调制新的3D感知脸部渲染以实现说话头生成。为了学习真实的运动系数,显式地建立了音频与不同类型的运动系数之间的连接。具体来说,提出了ExpNet,通过提取系数和3D渲染面部来从音频中学习准确的面部表情。至于头部姿势,设计了一个基于条件VAE的PoseVAE,以生成不同风格的头部运动。最后,将生成的3D运动系数映射到所提议的面部渲染的无监督3D关键点空间,并合成最终视频。
大量实验证明方法在运动和视频质量方面的优越性:https://sadtalker.github.io/

64、SDFusion: Multimodal 3D Shape Completion, Reconstruction, and Generation
这项工作提出了一个新的框架,旨在为初学者用户简化3D asset生成。为了实现交互式生成,方法支持各种可以方便地由人类提供的输入方式,包括图像、文本、部分观察到的形状以及这些的组合,还可以调整每个输入的强度。
方法的核心是一个编码器解码器,将3D形状压缩成一个紧凑的潜在表示,然后学习一个扩散模型。为了支持多模态输入的多样性,采用任务特定的编码器进行dropout,然后用一个交叉注意力机制。由于模型具有很高的灵活性,可以自然支持各种任务,在形状完成、基于图像的3D重建和文本到3D方面超越了以前的方法。
模型可以将所有这些任务整合到一个工具中,能同时使用不完整的形状、图像和文本描述进行形状生成,提供每个输入的相对权重并促进交互性。尽管方法只涉及形状,但还展示了一种利用大规模文本到图像模型对生成的形状进行纹理的高效方法。
https://yccyenchicheng.github.io/SDFusion/

65、Solving 3D Inverse Problems using Pre-trained 2D Diffusion Models
扩散模型已经成为具有高质量样本的新一代最佳生成模型,具有不错的优势,如模式覆盖和高灵活性。它们还被证明可以有效地解决逆问题,作为分布的先验,而前向模型的信息可以在采样阶段获得。然而,由于生成过程仍然处于相同的高维空间(即与数据维数相同),因此这些模型尚未扩展到3D逆问题(3D inverse problem),因为其极高的内存和计算成本。
这篇论文中,将传统的基于模型的迭代重建的想法与现代扩散模型相结合,构建了一种在解决3D医学图像重建任务(如稀疏视图断层扫描、有限角度断层扫描和压缩感测MRI)方面非常有效的方法,这些任务是从预先训练的2D扩散模型中得出的。本质上,在测试时通过2D扩散先验与基于模型的先验来增强剩余方向,从而实现所有维度的连贯重建。
方法可以在单个消费级GPU上运行,并确立了新的最佳实践方法,表明所提出的方法能够在最极端的情况下(如2视图3D断层扫描)实现高保真和准确的重建。进一步揭示,所提出方法的泛化能力非常之高,可用于重建与训练数据集完全不同的volume。

66、T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations
这项工作中,研究了一种基于矢量量化变分自动编码器(VQ-VAE)和生成式预训练Transformer (GPT) 的条件生成框架,用于从文本描述生成人体运动。证明,一个简单的基于CNN的VQ-VAE,使用常用的训练技巧(EMA和代码重置)可以获得高质量的离散表示。
对于GPT,在训练过程中加入了一个简单的破坏策略,以减轻训练和测试的差异。尽管简单,T2M-GPT表现优于竞争方法,包括最近的基于扩散的方法。例如,在目前最大的数据集HumanML3D上,文本和生成运动之间的一致性方面取得了与竞争方法相当的性能(R-Precision),但在FID 0.116上大大优于MotionDiffuse的0.630。
此外,还对HumanML3D进行了分析,发现数据集规模限制了方法。工作表明,VQ-VAE仍然是一种有竞争力的人体运动生成方法。实现可以在项目页面上找到:https://mael-zys.github.io/T2M-GPT/

67、TAPS3D: Text-Guided 3D Textured Shape Generation from Pseudo Supervision
这篇论文研究了从给定的文本描述生成可控3D纹理形状的开放研究任务。先前的工作要么需要实际真实的描述标签,要么需要大量的优化时间。为了解决这些问题,提出了一种新颖的框架,TAPS3D,用伪字幕训练一个文本引导的3D形状生成器。
具体来说,根据渲染的2D图像,从CLIP词汇表中检索相关单词,并使用模板构建伪描述。构建的描述文本为生成的3D形状提供了高级语义监督。此外,为了产生细粒度纹理和增加几何多样性,采用低层次的图像正则化,使假渲染图像与真实图像对齐。在推理阶段,模型可以在没有任何额外优化的情况下,从给定文本生成3D纹理形状。
实验分析了提出的每一个组件,并展示了在生成高保真度3D纹理和文本相关形状方面的有效性。代码:https://github.com/plusmultiply/TAPS3D

九、deepfake检测
68、Detecting and Grounding Multi-Modal Media Manipulation
虚假错误信息已成为一个紧迫的问题。 网络上广泛存在视觉和文本形式的虚假媒体。 虽然已经提出了各种 deepfake 检测和文本假新闻检测方法,但它们仅用于基于二分类的单模态检测,难以分析和推理跨不同模态的细微伪造痕迹。
本文强调多模态虚假媒体的一个新研究问题,即Detecting and Grounding Multi-Modal Media Manipulation (DGM4)。 目标不仅是检测多模态媒体的真实性,而且还将被编辑的内容(即图像边界框和文本标记)作为基础,这需要对多模态媒体编辑进行更深入的理解。
构建了第一个 DGM4 数据集,其中图像文本对通过各种方法进行编辑,并带有丰富的标注。此外,提出了一种新的分层多模态操作推理transformer (HierArchical Multi-modal Manipulation rEasoning tRansformer,HAMMER),以充分捕捉不同模态之间的细粒度交互。
最后,为这个新的研究问题建立了一个广泛的基准并建立了严格的评估指标。 综合实验证明了模型的优越性, 还揭示了一些有价值的观察结果,以促进未来对多模态媒体编辑的研究。https://github.com/rshaojimmy/MultiModal-DeepFake

十、图像超分
69、Activating More Pixels in Image Super-Resolution Transformer
基于Transformer的方法在低级别视觉任务中,如图像超分辨率,表现出了令人印象深刻的性能。Transformer的潜力在现有网络中仍未得到充分发挥。为了激活更多的输入像素以实现更好的重建,提出了一种新的混合注意力Transformer(HAT)。它同时结合了通道注意力和基于窗口的自注意力方案,从而充分利用了它们各自的优势,即能够利用全局统计和强大的局部拟合能力。
此外,为了更好地聚合跨窗口信息,引入了一种重叠的交叉注意力模块,以增强相邻窗口特征之间的交互作用。在训练阶段,采用同一任务预训练策略来利用模型的潜力以实现进一步的改进。大量实验证明了所提出的模块的有效性,进一步扩展了模型以显示出该任务的性能可以得到极大的提高。整体方法在PSNR比现有最先进的方法高出1dB以上。
https://github.com/XPixelGroup/HAT

70、Denoising Diffusion Probabilistic Models for Robust Image Super-Resolution in the Wild
扩散模型在单幅图像超分辨率和其他图像-图像转换任务中显示出良好的效果。尽管取得了这样的成功,但在更具挑战性的盲超分辨率任务中,它们的表现并没有超过最先进的GAN模型,在盲超分辨率任务中,输入图像的分布不均匀,退化未知。
本文介绍了一种基于扩散的盲超分辨率模型SR3+,为此,将自监督训练与训练和测试期间的噪声调节增强相结合。SR3+的性能大大优于SR3。在相同的数据上训练时,优于RealESRGAN。

71、Implicit Diffusion Models for Continuous Super-Resolution
图像超分辨率(SR)因其广泛的应用而受到越来越多的关注。然而,当前的SR方法通常受到过度平滑和伪影的影响,而大多数工作只能进行固定放大倍数。本文介绍了一种隐式扩散模型(IDM),用于高保真连续图像超分辨率。
IDM采用隐式神经表示和去噪扩散模型相结合的统一端到端框架,其中,在解码过程中采用了隐式神经表示来学习连续分辨率表示。此外,设计了一种比例自适应调节机制,其中包括低分辨率(LR)调节网络和一个比例因子,该比例因子调节分辨率并相应地调节最终输出中的LR信息和生成特征的比例,从而使模型适应连续分辨率要求。大量实验证实了IDM有效性,并展示其在先前艺术品中的卓越性能。代码在https://github.com/Ree1s/IDM

72、Perception-Oriented Single Image Super-Resolution using Optimal Objective Estimation
相对于使用失真导向损失(如L1或L2)训练的网络而言,使用感知和对抗损失训练的单图像超分辨率(SISR)网络提供了高对比度输出。但是,已经表明,使用单个感知损失无法准确恢复图片中的局部不同形状,往往会产生不良伪像或不自然的细节。因此,人们尝试了各种损失的组合,例如感知、对抗和失真损失,但往往很难找到最优的组合。
本文提出了一种新的SISR框架,应用于每个区域进行最优目标生成,以在高分辨率输出的整体区域中生成合理的结果。具体来说,该框架包括两个模型:一个预测模型,用于推断给定低分辨率(LR)输入的最佳目标图;一个生成模型,生成相应的SR输出。生成模型基于提出的目标轨迹进行训练,该轨迹表示一组基本目标,使单个网络能够学习与轨迹上组合的损失相对应的各种SR结果。
在五个基准测试中,实验结果表明,该方法在LPIPS、DISTS、PSNR和SSIM度量上优于最先进的感知驱动SR方法。视觉结果也证明了方法在感知导向重构方面的优越性。代码和模型在https://github.com/seunghosnu/SROOE
73、Structured Sparsity Learning for Efficient Video Super-Resolution
现有视频超分辨率(VSR)模型的高计算成本阻碍了它们在资源受限的设备(例如智能手机和无人机)上的部署。现有VSR模型包含相当多的冗余参数,拖慢推理效率。为了剪枝这些不重要的参数,根据VSR的特性开发了一种结构化剪枝方案,称为结构稀疏学习(SSL)。
SSL为VSR模型的多个关键组件设计了剪枝方案,包括残差块、递归网络和上采样网络。具体而言,为递归网络的残差块设计了一种残差稀疏连接(RSC)方案,以解放剪枝限制并保留恢复信息。对于上采样网络,设计了一个像素洗牌剪枝方案,以保证特征通道空间转换的准确性。此外观察到,在隐藏状态沿着递归网络传播时,剪枝误差会被放大。为缓解此问题,设计了时间微调(TF)。大量实验证明了SSL在定量和定性上都显著优于最近的方法。代码在https://github.com/Zj-BinXia/SSL

74、Super-Resolution Neural Operator
提出超分辨率神经算子(Super-resolution Neural Operator,SRNO),可以从低分辨率(LR)对应物中解决高分辨率(HR)图像的任意缩放。将LR-HR图像对视为使用不同网格大小近似的连续函数,SRNO学习了对应的函数空间之间的映射。
与先前的连续SR工作相比,SRNO的关键特征是:1)每层中的核积分通过Galerkin类型的注意力得到高效实现,在空间域中具有非局部特性,从而有利于网格自由的连续性;2)多层注意力结构允许动态潜在基础更新,这对于SR问题从LR图像“幻想”高频信息非常重要。
实验结果表明,SRNO在准确性和运行时间方面优于现有的连续SR方法。代码在https://github.com/2y7c3/Super-Resolution-Neural-Operator

75、Towards High-Quality and Efficient Video Super-Resolution via Spatial-Temporal Data Overfitting
提出一种新的高质量、高效的视频分辨率提高方法,利用时空信息将视频准确地分成块,从而将块的数量和模型大小保持在最小。在现成的移动电话上部署模型,实验结果表明,方法实现了具有高视频质量的实时视频超分辨率。与最先进的方法相比,在实时视频分辨率提高任务中实现了28 fps的流媒体速度,41.6 PSNR,速度提高了14倍,质量提高了2.29 dB。代码将发布:https://github.com/coulsonlee/STDO-CVPR2023

十一、风格迁移
76、CAP-VSTNet: Content Affinity Preserved Versatile Style Transfer
内容相似度损失(包括特征和像素相似度)是逼真和视频风格迁移中出现伪影的主要问题。本文提出了一个名为CAP-VSTNet的新框架,包括一个新的可逆残差网络(reversible residual network)和一个无偏线性变换模块,用于多功能风格转移。这个可逆残差网络不仅可以保留内容关联性,而且不像传统的可逆网络引入冗余信息,因此更有利于风格化处理。借助Matting Laplacian训练损失,可以处理线性变换引起的像素亲和力损失问题,因此提出的框架对多功能风格迁移是适用和有效的。广泛的实验显示,CAP-VSTNet相比于现有方法可以产生更好的定量和定性结果。

77、Inversion-Based Style Transfer with Diffusion Models
绘画中的艺术风格是表达的方式,包括绘画材料、颜色、笔法,还包括高级属性,包括语义元素、物体形状等。以往的任意示例引导的艺术图像生成方法通常不能控制形状变化或传达元素。已经预先训练的文本到图像生成扩散概率模型在质量上已经取得了显著的成绩,但通常需要大量的文本描述来准确地描绘特定画作的属性。
本文认为,艺术品的独特之处恰恰在于它无法用平常的语言充分解释。关键思想是直接从一幅画作中学习艺术风格,然后在不提供复杂的文本描述的情况下进行合成。具体而言,将风格假设为绘画的可学习文本描述。提出了一种基于逆映射inversion的风格迁移方法(inversion-based style transfer,InST),可以高效和精确地学习图像的关键信息,从而捕捉和传输绘画的艺术风格。
在各种艺术家和风格的众多画作上展示了方法的质量和效率。代码和模型在 https://github.com/zyxElsa/InST

78、Neural Preset for Color Style Transfer
论文提出一种神经预设技术(Neural Preset technique),以解决现有颜色风格迁移方法的局限性,包括视觉伪影、庞大的内存需求和风格切换速度慢。方法基于两个核心设计。
首先,提出了确定性神经颜色映射(DNCM),通过一个图像自适应的颜色映射矩阵一致地作用于每个像素,避免伪影,并支持具有小内存占用的高分辨率输入。
其次,通过将任务划分为颜色归一化和风格化来开发一个两阶段流水线,这允许通过将颜色风格提取为预设并在归一化的输入图像上重复使用它们来有效地进行风格切换。由于缺乏成对数据集,描述了如何通过自监督策略来训练神经预设。
通过全面的评估展示了神经预设相对于现有方法的各种优势。此外,展示了训练的模型可以自然地支持多个应用程序,无需微调,包括低光图像增强、水下图像校正、图像去雾和图像调和。可以在 https://zhkkke.github.io/NeuralPreset/#/ 获得源代码和训练模型。

十二、去雨去噪去模糊
79、Learning A Sparse Transformer Network for Effective Image Deraining
基于Transformer的方法在图像去雨任务中取得了显著的性能,因为它们可以对重要的非局部信息进行建模,这对高质量的图像重建至关重要。本文发现大多数现有的Transformer通常使用查询-键对中的所有token的相似性进行特征聚合。然而,如果查询中的token与键中的token不同,从这些token估计的自关注值也会涉及到特征聚合,这相应地会干扰清晰的图像恢复。
为了克服这个问题,提出了一种有效的去雨网络,稀疏Transformer(DRSformer),它可以自适应地保留特征聚合的最有用的自关注值,以便聚合的特征更好地促进高质量的图像重建。具体而言,开发了一个可学习的前k选择运算符,以便为每个查询自适应保留最重要的键的自关注分数,进行更好的特征聚合。同时,由于Transformer中的简单前馈网络不能模拟对潜在清晰图像恢复很重要的多尺度信息,开发了一种有效的混合尺度前馈网络,以生成更好的图像去雨特征。为了学习一个丰富的混合特征集,结合了CNN运算符的局部上下文,配备了专家特征补偿器混合的模型,以呈现协作细化去雨方案。
实验结果表明,与最先进的方法相比,所提出的方法在通常使用的基准测试中实现了有利的性能。源代码和训练模型在 https://github.com/cschenxiang/DRSformer

80、Masked Image Training for Generalizable Deep Image Denoising
当捕捉和存储图像时,设备不可避免地会引入噪点。减少这种噪点是称为图像去噪的关键任务。深度学习已经成为图像去噪的事实标准方法,特别是在出现了基于Transformer的模型之后,在各种图像任务上取得了显著的最先进结果。然而,基于深度学习的方法通常缺乏泛化能力。例如,在高斯噪声上训练的深度模型可能在其他噪声分布上测试时表现不佳。
为了解决这个问题,提出了一种增强去噪网络的泛化性能的新方法,称为掩蔽训练。方法涉及掩蔽输入图像的随机像素,并在训练期间重构缺失的信息。还掩蔽了自注意层中的特征,以避免训练-测试不一致性的影响。方法展现出比其他深度学习模型更好的泛化能力,并直接适用于实际场景。此外,可解释性分析证明了方法的优越性。https://github.com/haoyuc/Masked

81、Uncertainty-Aware Unsupervised Image Deblurring with Deep Residual Prior
非盲去模糊方法在准确模糊核假设(accurate blur kernel assumption)下能够实现良好的性能。然而,在实践中模糊核的不确定性(模糊核误差)是不可避免的,因此建议采用半盲去模糊方法,通过引入模糊核(或诱导)误差的先验来处理它。但是,如何为模糊核(或诱导)误差设计合适的先验仍然具有挑战性。手工制作的先验通常表现良好,但当模糊核(或诱导)误差复杂时可能会导致性能下降。基于数据驱动的先验过度依赖于训练数据的多样性和丰度,容易受到超出分布的模糊和图像的影响。
为了解决这一挑战,提出了一种针对模糊核诱导误差kernel induced error(称为残差residual)的无数据集深度残差先验(dataset-free deep residual prior),该方法由自定义的未训练深度神经网络表示,它使我们能够在实际场景中灵活适应不同的模糊和图像。通过有机地整合深度先验和手工制作的先验的各自优势,提出了一种无监督的半盲去模糊模型,它可将清晰的图像从模糊的图像和不准确的模糊核中恢复出来。为了处理这个模型,使用了一个高效的交替最小化算法。实验表明,与模型驱动和数据驱动方法相比,所提出的方法在图像质量和对不同类型模糊核误差的稳健性方面具有良好的性能。

十三、图像分割
82、DiGA: Distil to Generalize and then Adapt for Domain Adaptive Semantic Segmentation
领域适应的语义分割方法通常采用阶段式训练,包括预热warm-up和自训练阶段。然而,这种流行的方法仍然面临着一些挑战,比如预热阶段中广泛采用的对抗训练因特征未对齐而导致性能提升有限,自训练阶段中找到适当的分类阈值十分棘手。
为了缓解这些问题,首先提出用一种新的对称知识蒸馏模块替代预热阶段中的对抗训练,这个模块只访问源域数据,使模型具有域泛化能力。令人惊讶的是,这个具有域泛化能力的预热模型带来了可观的性能提升,这个提升还可以通过提出的跨域混合数据增强技术进一步放大。然后,在自训练阶段,提出一种无阈值动态伪标签选择机制,以缓解前面提到的阈值问题,并使模型更好地适应目标域。
广泛实验表明,与以前的方法相比在流行的基准测试上都取得了显著和一致的改进。代码和模型在https://github.com/fy-vision/DiGA

83、Generative Semantic Segmentation
提出了生成式语义分割(GSS)用于语义分割。独特的是,将语义分割形式化为一种图像条件掩码生成问题。通过用潜在的先验学习过程替代传统的面向像素的判别式学习。
具体来说,建立给定分割掩码的潜变量后验分布。为此,使用了一种特别类型的图像来表示分割掩码(称为“maskige”)。这个后验分布可以无条件地生成分割掩码。为了在给定图像上实现语义分割,进一步引入了一个条件网络。大量的实验表明,GSS可以与以前的替代方案竞争,同时在更具挑战性的跨领域设置中取得了新的最高水平。
https://github.com/fudan-zvg/GSS

84、Learning to Generate Text-grounded Mask for Open-world Semantic Segmentation from Only Image-Text Pairs
通过仅使用图像和文本对而没有密集标注,解决了学习在图像中分割任意视觉概念的开放场景语义分割问题。现有的开放分割方法通过采用对比学习来学习不同的视觉概念,并将学习到的图像级别理解迁移到分割任务中,取得了令人印象深刻的进展。然而,这些基于对比学习的方法在训练时仅考虑图像和文本对齐,而在测试时分割需要进行区域-文本对齐,从而存在训练-测试差异。
本文提出了一种新的以文本为基础的对比学习框架(TCL),使模型能够直接学习区域-文本对齐。方法为给定文本生成一个分割掩码,从掩码区域提取文本引导的图像嵌入,然后通过TCL将其与文本嵌入对齐。通过直接学习区域-文本对齐,鼓励模型直接改善生成的分割掩码的质量。
此外,为了进行严格和公正的比较,提出了一个统一的评估协议,包括广泛使用的8个语义分割数据集。在所有数据集中,TCL都达到了最先进的零样本分割性能。代码在 https://github.com/kakaobrain/tcl

85、Open-Vocabulary Panoptic Segmentation with Text-to-Image Diffusion Models
提出了ODISE: 开放词汇扩散式全景分割,它将预训练的文本-图像扩散和判别模型统一起来,以执行开放词汇全景分割。文本到图像扩散模型已经展现出用有多样性的开放词汇语言描述生成高质量图像的卓越能力。这表明他们的内部表示空间与现实世界中的开放概念高度相关。另一方面,像CLIP这样的文本-图像判别模型擅长将图像分类为开放词汇标签。提出利用这些模型的冻结表示,以执行任何类别的全景分割。方法在开放式词汇全景和语义分割任务上都优于以前的最优结果。特别是仅使用COCO训练,方法在ADE20K数据集上实现了23.4 PQ和30.0 mIoU,相比以前的最优结果,PQ和mIoU绝对提升了8.3和7.9。
开源代码和模型在:https://github.com/NVlabs/ODISE

十四、视频相关
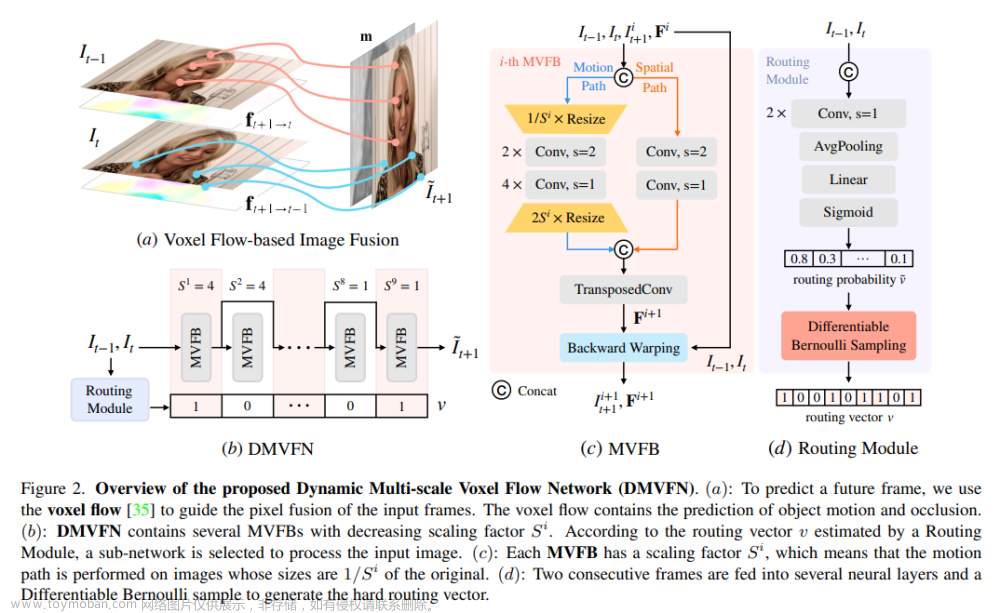
86、A Dynamic Multi-Scale Voxel Flow Network for Video Prediction
视频预测(video prediction)的性能已经通过先进的深度神经网络大幅提高。然而,大多数当前的方法存在着大的模型尺寸和需要额外的输入(如,语义/深度图)以实现良好的性能。出于效率考虑,本文提出了一个动态多尺度体素流网络(Dynamic Multi-scale Voxel Flow Network,DMVFN),只基于RGB图像,可以在更低的计算成本下实现更好的视频预测性能,比之前的方法快一个数量级。
DMVFN的核心是一个可以有效感知视频帧的运动尺度的可微分路由模块(differentiable routing module)。一旦训练完成,在推理阶段为不同的输入选择自适应子网络。在几个基准测试上的实验表明,相比于Deep Voxel Flow,DMVFN速度快一个数量级,超越了最新的基于迭代的OPT在生成图像质量上的表现。
https://huxiaotaostasy.github.io/DMVFN/

87、A Unified Pyramid Recurrent Network for Video Frame Interpolation
流引导合成(Flow-guided synthesis),为帧插值提供了一个通用的框架,其中估计光流以指导合成两个连续输入之间的中间帧。本文提出了一种新型的统一金字塔循环网络(UPR-Net)用于帧插值。UPR-Net利用灵活的金字塔框架,利用轻量级循环模块进行双向流估计和中间帧合成。在每个金字塔级别,它利用估计的双向流为帧合成生成正向变形表示;跨越金字塔级别,它使迭代的优化用于光流和中间帧。迭代合成策略可以显著提高大运动情况下的帧插值的鲁棒性。
尽管基于UPR-Net的基础版本极度轻量(1.7M参数),但在大量基准测试上表现出色。UPR-Net系列的代码和训练模型在https://github.com/srcn-ivl/UPR-Net

88、Conditional Image-to-Video Generation with Latent Flow Diffusion Models
条件图像到视频(Conditional image-to-video,cI2V)生成,旨在从图像(例如,人脸)和条件(例如,类别标签,例如微笑)开始合成一个新的 plausible 视频。 cI2V任务的关键挑战在于同时生成与给定图像和条件对应的空间外观和时间性动态。
本文提出一种使用基于新型潜流扩散模型(latent flow diffusion models,LFDM)的cI2V方法。与以前直接合成相比,LFDM更好利用给定图像的空间内容,在潜在空间中进行变形来合成细节和运动。LFDM训练分为两个独立阶段:(1)无监督学习阶段,用于训练潜在流自动编码器以进行空间内容生成,其中流预测器用于估计视频帧对之间的潜在流(2)条件学习阶段,用于训练基于3D-UNet的扩散模型(DM)以进行时间潜在流生成。LFDM仅需要学习低维潜在流空间以进行运动生成,计算高效。
在多个数据集上进行了全面实验,证明LFDM始终优于现有技术。此外,展示LFDM可以通过简单微调图像解码器来轻松适应新领域。代码在https://github.com/nihaomiao/CVPR23_LFDM

89、Diffusion Video Autoencoders: Toward Temporally Consistent Face Video Editing via Disentangled Video Encoding
受最近人脸图像编辑方法的卓越性能启发,有几项研究自然地提出将这些方法扩展到视频编辑任务中。其中一个主要的挑战是编辑帧之间的时间一致性,这仍然没有解决。
为此,提出了一种基于扩散自动编码器的新的人脸视频编辑框架,能够通过简单地操作具有时间稳定性的特征即可实现视频编辑以达到一致性。模型另一个独特优势是,基于扩散模型可以同时满足重建和编辑能力,并且不同于现有的基于GAN的方法,可以抵御极端情况,自然场景人脸视频(例如遮挡的面部)。
https://diff-video-ae.github.io/

90、Extracting Motion and Appearance via Inter-Frame Attention for Efficient Video Frame Interpolation
有效地提取帧间运动和外观信息对于视频帧插值(video frame interpolation,VFI)非常重要。以往要么混合提取这两种信息,要么针对每种信息都要有详尽的单独模块,这会导致表示的模糊性和效率不高。
本文提出一种新模块,通过统一的操作明确地提取运动和外观信息。具体而言,重新考虑帧间注意力中的信息处理,并重用其注意力图以用于外观特征增强和运动信息提取。此外,为了实现高效的VFI,模块可以无缝集成到混合CNN和Transformer体系结构中。这种混合管道可以缓解帧间注意力的计算复杂性,同时保留详细的低级结构信息。
实验结果表明,无论是在固定间隔还是任意间隔的插值方面,方法在各种数据集上都实现了最先进性能。同时,与具有相似性能的模型相比,具有更小的计算开销。源代码和模型在https://github.com/MCG-NJU/EMA-VF

91、MM-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation
提出了第一个联合音频-视频生成的框架,可以同时带来引人入胜的观看和听觉体验,旨在实现高质量的逼真视频。为了生成联合音视频对,提出了一种新的多模态扩散模型(即MM-Diffusion),其中包括两个耦合去噪自编码器。与现有的单模态扩散模型不同,MM-Diffusion由一个顺序的多模态U-Net组成,通过设计用于联合去噪过程。用于音频和视频的两个子网络逐步从高斯噪声中学习生成对齐的音频视频对。
实验结果表明,在无条件音视频生成和零样本条件任务(例如,视频到音频)方面具有优越的结果。代码和预训练模型在https://github.com/researchmm/MM-Diffusion

92、MOSO: Decomposing MOtion, Scene and Object for Video Prediction
运动、场景和物体是视频的三个主要视觉组成部分。特别是,物体代表前景,场景代表背景,运动则追踪它们的动态。基于这个认识,本文提出了一个两阶段的运动、场景和物体分解框架(MOtion, Scene and Object decomposition,MOSO),用于视频预测,包括MOSO-VQVAE和MOSO-Transformer。
在第一阶段中,MOSO-VQVAE将先前视频剪辑分解为运动、场景和物体组件,并将它们表示为不同的离散token组。然后,在第二阶段中,MOSO-Transformer基于先前的标记预测后续视频剪辑的物体和场景token,并在生成的物体和场景token级别上添加动态运动。
框架可以轻松扩展到无条件视频生成和视频帧插值任务。实验结果表明,方法在视频预测和无条件视频生成的五个具有挑战性的基准测试中取得了新的最优性能:BAIR、RoboNet、KTH、KITTI和UCF101。此外,MOSO可以通过组合来自不同视频的对象和场景产生逼真的视频。
https://github.com/iva-mzsun/MOSO

93、Text-Visual Prompting for Efficient 2D Temporal Video Grounding
本文研究了时间视频定位(temporal video grounding,TVG)的问题,它旨在预测由文本句子描述的时刻在视频中的起始/结束时间点。由于精细3D视觉特征优势,TVG在近年来取得明显进展。然而,3D卷积神经网络(CNNs)的高复杂性耗时,需大量的存储和计算资源。
为了实现高效的TVG,提出一种新的文本-视觉提示(TVP)框架,将优化的扰动模式(optimized perturbation patterns,称之为“prompts”)并入TVG模型的视觉输入和文本特征中。与3D CNN相比,TVP有效地在2D TVG模型中共同训练视觉编码器和语言编码器,并使用低复杂度的稀疏2D视觉特征来提高跨模态特征融合的性能。此外,提出了一种用于有效学习TVG的时间距离IoU(TDIoU)损失。基于Charades-STA和ActivityNet Captions数据集的实验证明,TVP显著提升了2D TVG的性能(如Charades-STA上的9.79%改进和ActivityNet Captions上的30.77%改进),且用3D视觉特征进行TVG相比,推断加速达到5倍。
https://github.com/intel

94、Towards End-to-End Generative Modeling of Long Videos with Memory-Efficient Bidirectional Transformers
Autoregressive transformer在视频生成方面表现出色。然而,受到自注意力的二次复杂性限制,不能直接学习视频中的长期依赖性,并且由于自回归过程而受到慢速推理时间和误差传播影响。
本文提出一种记忆效率的双向transformer(Memory-efficient Bidirectional Transformer,MeBT),用于端到端学习视频中的长期依赖性和快速推理。基于最新进展,方法学习从部分观察到的patch中并行解码视频的整个时空volume。在编码和解码方面均具有线性时间复杂度,通过将可观察的上下文token投影到固定数目的潜在token中,并通过交叉注意力将它们条件化为编码、解码掩码token。
由于线性复杂度和双向建模,方法在质量和速度上对适度长时间内视频的生成比自回归有着显著改进。视频和代码在https://sites.google.com/view/mebt-cvpr2023

95、Video Probabilistic Diffusion Models in Projected Latent Space
尽管深度生成模型取得了显著进展,但由于高维度和复杂的时空动态以及大的空间变化,合成高分辨率和时间连贯的视频仍然是一个挑战。最近扩散模型研究显示了它们解决这一问题的潜力,但它们面临着计算和内存效率问题。
为了解决这个问题,本文提出了一个新的视频生成生成模型,称为投影潜在视频扩散模型(PVDM),它是一个概率扩散模型,可以在低维潜在空间中学习视频分布,因此可以在有限的资源下高效地训练高分辨率视频。具体来说,PVDM由两个组件组成:(a)一个自编码器,将给定的视频投影为2D形状的潜在向量,这些向量分解了视频像素的复杂立方体结构;以及(b)一个扩散模型体系结构,专门为新分解潜在空间和训练/采样过程设计,并使用单个模型合成任意长度的视频。流行视频生成数据集上的实验证明了PVDM相对于以前的视频合成方法的优越性;例如,PVDM在UCF-101长视频(128帧)生成基准测试中获得了639.7的FVD得分,比先前的最优方法提高了1773.4。

96、VideoFusion: Decomposed Diffusion Models for High-Quality Video Generation
扩散概率模型(DPM)通过逐步向数据添加噪声构建正向扩散过程,并学习反向去噪过程以生成新的样本,已被证明可处理复杂的数据分布。尽管在图像生成方面取得了成功,但将DPM应用于视频生成仍具有挑战,因为它面临高维度的数据空间。以前的方法通常采用标准扩散过程,在其中同一视频中的帧使用独立的噪声进行破坏,忽略了内容冗余和时间相关性。
本文通过将每帧噪声解决为在所有帧之间共享的基础噪声和沿时间轴变化的残余噪声,提出了一个分解扩散过程。去噪流程采用两个联合学习的网络相应地匹配噪声分解。各种数据集上的实验确认了方法(称为VideoFusion)在高质量视频生成方面超越了基于GAN和基于扩散的替代方案。

###########################
十五、对抗攻击
97、Adversarial Attack with Raindrops
深度神经网络(DNNs)易受有意构造的对抗样本攻击,但这些攻击很少出现在真实世界的场景中。本文研究由雨滴引起的对抗样本,证明存在许多自然现象可以作为 DNNs 的对抗者。此外,提出了一种新方法来生成对抗性雨滴(AdvRD),使用生成对抗网络(GAN)技术模拟自然雨滴。创建的 AdvRD 图像与真实的雨滴图像非常相似,在统计上也接近真实的雨滴图像分布,更重要的是,可以对最先进的 DNN 模型进行强有力的攻击。同时,展示了使用AdvRD 图像进行对抗性训练可以显著提高 DNNs 对真实雨滴攻击的鲁棒性。

98、TrojDiff: Trojan Attacks on Diffusion Models with Diverse Targets
扩散模型在图像生成和分子设计等任务中取得了巨大成功。由于扩散模型成功依赖于来自不同来源的大规模训练数据,这些收集到的数据的可信性难以控制或审核。这项工作旨在探索扩散模型在潜在的训练数据篡改下的漏洞,并尝试回答:对于训练良好的扩散模型来说,执行特洛伊攻击有多难?特洛伊攻击可以实现什么样的对抗目标?
为了回答这些问题,提出了一种有效的扩散模型特洛伊攻击,即 TrojDiff,它在训练期间优化特洛伊扩散和生成过程。特别地,在特洛伊扩散过程中,设计了新的转换来将对抗目标扩散到有偏的高斯分布中,并提出了特洛伊生成过程的新参数化,这导致了一个有效的攻击训练目标。此外,考虑三种对抗目标:特洛伊扩散模型总是从域内分布(In-D2D 攻击)、域外分布(Out-D2D 攻击)和一个特定实例(D2I 攻击)输出实例。在 CIFAR-10 和 CelebA 数据集上对 DDPM 和 DDIM 扩散模型的 TrojDiff 进行评估。展示了在使用不同类型的触发器和不同的对抗目标时,TrojDiff 总是实现高攻击性能,而在良性环境下的性能保持不变。代码在 https://github.com/chenweixin107/TrojDiff

十六、扩散模型改进
99、All are Worth Words: A ViT Backbone for Diffusion Models
视觉 Transformer(ViT)已在各种视觉任务中显示出潜力,而基于卷积神经网络(CNN)的 U-Net 仍然是扩散模型的主导。设计了一种简单通用的 ViT-based 架构(命名为 U-ViT)用于扩散模型的图像生成。U-ViT 的特点是将所有输入(包括时间、条件和嘈杂的图像块)都视为token,并在浅层和深层之间使用长跳线连接。
在无条件和类条件图像生成以及文本到图像生成任务中评估了 U-ViT,其中 U-ViT 在大小相似的基于 CNN 的 U-Net 上表现出类似或优越的性能。特别是,具有 U-ViT 的潜在扩散模型在 ImageNet 256×256 的类条件图像生成上实现了打破记录的 FID 分数为 2.29,在 MS-COCO 的文本到图像生成上实现了 5.48 的成绩,这是在生成模型的训练过程中没有访问大型外部数据集的方法中的记录。结果表明,在基于扩散的图像建模中,长时间的跳跃连接至关重要,而基于 CNN 的 U-Net 中的下采样和上采样运算并不总是必要。U-ViT 可以为未来的扩散模型骨干研究提供参考,并对跨模态大规模数据集的生成建模有益。代码在 https://github.com/baofff/U-ViT

100、Towards Practical Plug-and-Play Diffusion Models
基于扩散的生成模型在图像生成方面取得了卓越的成果,可以插入外部模块控制各种任务的生成过程,而无需微调扩散模型。然而,用公开可用的即插即用模型直接作为指导器,在嘈杂输入上进行效果很差。为此,现有做法是用噪声损坏的标注数据对指导模型进行微调。
本文认为这种做法有两个方面的局限性:(1)对极其不同噪声数据的输入执行困难;(2)收集标注数据集阻碍了各种任务的扩展。为了克服这些限制,提出一种新的策略,利用多个专家模块,每个专门针对特定的噪声范围,并引导在其相应时间步骤中逆置扩散过程。
但管理多个专家网络并利用标注数据是不可行的,提出了一种实用的指导框架,称为实用即插即用(PPAP),利用参数有效微调和无数据的知识迁移。通过 ImageNet 类条件生成实验进行了扩展,以表明方法可以成功引导扩散,只有少量的可训练参数,而无需依靠标注数据。最后,展示了图像类别、深度估计和语义分割可以在框架中以即插即用的方式指导公开可用的GLIDE。代码在 https://github.com/riiid/PPAP

101、Wavelet Diffusion Models are fast and scalable Image Generators
扩散模型在图像生成中有着极高的保真度,超过了 GANs 在许多情况下的质量。但它们缓慢的训练和推理速度是一个巨大的瓶颈,阻止了它们在实时应用中的使用。最近的 DiffusionGAN 方法将样本步骤的数量从数千个减少到数个,显著降低了模型运行时间,但其速度仍大大落后于 GAN 。
本文旨在通过提出基于小波的扩散方案来减少速度差距。通过小波分解从图像和特征层面提取低频和高频分量,并自适应地处理这些分量,从而实现更快的处理速度而仍保持良好的生成质量。此外,提出使用重构,有效提高模型训练的收敛性能。
在 CelebA-HQ、CIFAR-10、LSUN-Church 和 STL-10 数据集上的实验结果证明,解决方案是提供实时高保真度扩散模型的垫脚石。代码在 https://github.com/VinAIResearch/WaveDiff.git

十七、数据增广
102、DCFace: Synthetic Face Generation with Dual Condition Diffusion Model
生成用于训练人脸识别模型的数据集具有挑战性,因为数据集生成需要的不仅仅是创建高保真图像,涉及在不同因素(例如姿势、光照、表情、年龄和遮挡的变化)下生成相同主体的多幅图像,这些图像遵循真实图像的条件分布。
以前工作已研究了使用GAN或3D模型生成数据集。这项工作从主体外观(ID)和外部因素(风格)条件相结合的角度来解决这个问题。这两个条件提供了一种控制类间和类内变化的直接方法。为此,提出一种基于扩散模型的双条件人脸发生器(DCFace)。Patch-wise风格提取器和Time-step依赖的ID损失使DCFace能够在精确控制下一致地生成同一身份的不同风格的人脸图像。
在LFW、CFP-FP、CPLFW、AgeDB和CALFW这5个测试数据集中的4个测试数据集上,使用DCFace合成图像训练的人脸识别模型的验证准确率比之前的工作平均提高了6.11%。https://github.com/mk-minchul/dcface

103、Leveraging GANs for data scarcity of COVID-19: Beyond the hype
基于人工智能 (AI) 的模型可以帮助从肺部 CT 扫描和 X 射线图像诊断 COVID-19; 但是,这些模型需要大量数据来进行训练和验证。 许多研究人员研究了用于生成肺部 CT 扫描和 X 射线图像的生成对抗网络 (GAN),以提高基于 AI 的模型的性能。 目前还没有很好地探索基于 GAN 的方法如何生成可靠的合成数据。
这项工作分析了 43 项已发表的研究,这些研究报告了 GAN 用于合成数据生成。 其中许多研究存在数据偏差、缺乏可重复性以及缺乏放射科医生或其他领域专家的反馈。 这些研究中的一个常见问题是源代码不可用,这阻碍了重现性。 纳入的研究报告了输入图像的重新缩放以训练现有的 GAN 架构,但没有提供有关重新缩放的动机的临床见解。 最后,尽管基于 GAN 的方法具有数据增强和改进基于 AI 模型的训练的潜力,但这些方法在临床实践中的使用方面存在不足。
本文重点介绍了应对数据稀缺问题的研究热点,确定了各种问题和潜力,并提出了指导未来研究的建议。 这些建议可能有助于提高基于 GAN 的数据增强方法的可接受性,因为用于数据增强的 GAN 在 AI 和医学成像研究社区中越来越受欢迎。
104、Lift3D: Synthesize 3D Training Data by Lifting 2D GAN to 3D Generative Radiance Field
这项工作探索了使用 3D 生成模型来合成 3D 视觉任务的训练数据。 生成模型的关键要求是生成的数据应逼真以匹配真实场景,并且相应的 3D 属性应与给定的采样标签对齐。 然而,最近基于 NeRF 的 3D GAN 由于其设计的生成管道和缺乏明确的 3D 监督而很难满足上述要求。
这项工作提出了 Lift3D,一种 2D 到 3D 生成框架,以实现数据生成目标。 与之前的方法相比,Lift3D 有几个优点:(1) 与之前的 3D GAN 不同,训练后输出分辨率是固定的,Lift3D 可以泛化到任何具有更高分辨率和逼真输出的相机固有特性。 (2) 通过将分离良好的 2D GAN 提升到 3D 对象 NeRF,Lift3D 提供生成对象的显式 3D 信息,从而为下游任务提供准确的 3D 标注。
通过扩充自动驾驶数据集来评估有效性。 实验结果表明,可以有效提高 3D 对象检测器的性能。 项目页面:len-li.github.io/lift3d-web

十八、说话人生成
105、MetaPortrait: Identity-Preserving Talking Head Generation with Fast Personalized Adaptation
这项工作提出一个保持身份的谈话头生成框架,该框架在两个方面改进了先前的方法。首先,与从稀疏流插值相反,密集的关键点对于实现精确的几何感知流场至关重要。其次,受人脸交换方法的启发,在合成过程中自适应融合源身份,使网络更好地保留图像肖像的关键特征。
尽管所提出方法在基准上超过了此前方法的保真度,但仍需进行个性化微调,以进一步使说话头符合实际使用。然而这个过程对计算的要求很高,为缓解问题,提出一种元学习方法的快速适应模型,可以在30秒内适应为高质量的个性化模型。最后,提出了一个时空增强模块,在保证时间一致性的前提下,提高图像的细节。
方法在一次性和个性化设置方面都优于最先进的方法。https://meta-portrait.github.io/

106、Seeing What You Said: Talking Face Generation Guided by a Lip Reading Expert
说话脸生成(Talking face generation),也称为语音到嘴唇生成,在给定连贯语音输入的情况下,重建与嘴唇有关的活动人脸。以往的研究揭示了唇语同步和视觉质量的重要性。尽管取得了很大的进步,但他们很少关注嘴唇运动的内容,即口语的视觉可理解性,这是生成质量的一个重要方面。
为了解决这个问题,使用唇读专家模型通过惩罚错误的生成结果来提高生成的唇区域的可理解性。此外,为了弥补数据的缺乏性,以视听自监督的方式训练唇读专家。在唇读专家的帮助下,提出了一种新的增强唇语同步的对比学习方法,以及一种考虑音频全局时间依赖性的音频与视频同步编码的转换器。
为了评估,提出一种新策略,由两个不同的唇读专家模型来测量生成视频的可理解性。实验表明,方法优于其他先进方法,如Wav2Lip,即LRS2数据集上的单词错误率(WER)超过38%,LRW数据集上的准确率超过27.8%。还在唇语同步方面取得了SOTA性能,在视觉质量方面也取得了相当的性能。

十九、视图合成
107、Consistent View Synthesis with Pose-Guided Diffusion Models
单张图像的新视角合成是许多虚拟现实应用中提供沉浸式体验的基本问题。然而,大多数现有技术只能在有限的相机运动范围内合成新视角,或者在重要的相机运动下无法生成一致和高质量的新视角。
这项工作提出了一个姿态引导的扩散模型,从一张单独的图像生成一部一致的新视角视频。设计了一个注意力层,利用极线约束有助于联合不同视角的图像。对合成的结果进行了实验,并使用合成结果验证了该方法的有效性,证明了其对现有的基于GAN方法和基于transformer方法的优越性。

二十、目标检测
108、Multi-view Adversarial Discriminator: Mine the Non-causal Factors for Object Detection in Unseen Domains
域漂移(Domain shift)会导致目标检测模型在实际应用中的性能下降。为了缓解影响,之前的研究尝试通过域对抗学习(DAL)将域不变(domain-invariant,通用)特征从源域中解耦和学习。然而,受到因果机制的启发,发现之前的方法忽视了隐藏在公共特征中的non-causal factors。这主要是由于DAL的单一视图性质。
提出了一种通过源域上的多视图对抗训练去除公共特征中non-causal factors的方法,这由于数据的多模式结构可能仍然存在于其他潜在空间(视图)中。综上所述,提出了一种基于多视图对抗判别器(Multi-view Adversarial Discriminator,MAD)的域泛化模型,该模型包括一个通过随机增广增加源域多样性的虚假相关性生成器(SCG)和一个将特征映射到多个潜在空间(MVDC)的多视图域分类器,以此去除non-causal factors并净化域不变特征。
进行了六项基准测试的实验表明,MAD取得了最先进的性能。

二十一、人像生成-姿态迁移
109、Person Image Synthesis via Denoising Diffusion Model
姿势引导的人物图像生成任务要求合成以任意姿势站立的人类的逼真图像。现有方法使用生成对抗网络,这些网络不一定能保持逼真的纹理或需要密集的对应关系来处理复杂的变形和严重的遮挡。
这项工作展示了如何使用去噪扩散模型进行高保真人物图像合成,以及如何提高所学数据分布的样本多样性和增强模式覆盖。提出的“人物图像扩散模型”(PIDM)将复杂的转移问题分解为一系列较简单的正向和反向去噪步骤。这有助于学习可信的源-目标转换轨迹,从而产生忠实的纹理和未扭曲的外观细节。
引入了一个基于交叉关注的“纹理扩散模块”,以准确地建模源图像和目标图像中的外观和姿势信息之间的对应关系。此外,提出了“解耦分类器自由指导”,以确保有条件的输入与以姿势和外观信息为基础的合成输出间有紧密的相似性。在两个大规模基准测试和一项用户研究中广泛展示了所提出的方法在具有挑战性的情况下的逼真程度。还展示了生成的图像如何帮助下游任务。

110、VGFlow: Visibility guided Flow Network for Human Reposing
人体重置任务(human reposing),涉及生成以任意可想象的姿势站立的逼真图像。生成视觉上准确的图像存在多个困难,现有方法在保存纹理、维护图案连续性、尊重服装边界、处理遮挡、操作皮肤生成等方面存在局限性。这些困难进一步恶化了人体各种方向的可能空间是大且具有可变性,服装单品的自然情况高度非刚性,身体形状的多样性在人口中差异很大。
为了缓解这些困难并生成视觉上准确的图像,提出了VGFlow。模型使用可见性引导流模块将流分解为目标的可见和不可见部分,以进行纹理保持和风格操作。此外,为了处理不同的身体形状并避免网络 artifacts,还结合了自监督的基于路径的“真实性”损失来改善输出。VGFlow在不同的图像质量指标(SSIM、LPIPS、FID)上实现了最先进的结果,这些结果可以在定量和定性评估中观察到。

二十二、发型迁移
111、StyleGAN Salon: Multi-View Latent Optimization for Pose-Invariant Hairstyle Transfer
论文旨在将参考图像的发型迁移到输入照片中进行虚拟试发。针对各种具有挑战性的场景,例如将具有刘海的长发转换为马尾辫,这需要删除现有的头发并推断额头的样子,或从戴帽子的人的不同姿势中转移部分可见的头发。
过去的解决方案利用StyleGAN来幻想任何缺失部分,并通过所谓的GAN逆映射或投影生成无缝的面部-头发复合图像。然而,仍然存在控制幻觉以精确转移发型并保留输入的脸部形状和身份的挑战。为了克服这个问题,提出了一个多视角优化框架,使用参考复合图像的两个不同视角在语义上指导遮挡或模糊区域。本文优化在两个姿势之间共享信息,从而能够从不完整的参考图像中产生高保真度和逼真的结果。
方法产生了高质量的结果,在比以前研究的更具挑战性的头发转移场景的用户研究中表现出了优于先前工作的性能。项目页面:https://stylegan-salon.github.io/

二十三、图像修复
112、SmartBrush: Text and Shape Guided Object Inpainting with Diffusion Model
通用图像修复旨在通过借用周围信息来完整损坏的图像,从而产生的内容基本上没有产生新的内容。相比之下,多模修复提供了更灵活和有用的对修复内容的控制,例如,文本提示可以用于描述具有更丰富属性的对象,而掩膜可以用于约束修补的形状,而不仅仅被视为缺失区域。
提出了一种名为SmartBrush的基于扩散的新模型,用于使用文本和形状指导完成缺失的区域和对象。虽然以前的一些工作如DALLE-2和稳定扩散可以进行文本引导修复,但它们不支持形状引导,并倾向于修改生成对象周围的背景纹理。本文模型使用精确控制的文本和形状引导相结合。为了更好地保留背景,提出了一种新的训练和采样策略,通过增加对象掩膜预测对扩散UNET进行扩充。最后,引入了一种多任务训练策略,通过联合训练修复和文本到图像生成来利用更多的训练数据。
大量实验证明,模型在视觉质量、掩膜可控性和背景保留方面优于所有基线。

二十四、表征学习
113、GD-MAE: Generative Decoder for MAE Pre-training on LiDAR Point Clouds
尽管在开发视觉任务如图像和视频方面,Masked Autoencoders(MAE)取得了巨大进步,但由于固有的不规则性,探索大规模3D点云中的MAE仍然具有挑战性。与之前的3D MAE框架相比(设计复杂的解码器从维护区域推断掩蔽信息或采用复杂的掩蔽策略),提出了一种更简单的范例。
核心思想是应用生成解码器MAE(GD-MAE)自动将周围上下文合并,以按层次融合方式恢复掩蔽的几何知识。这样做,方法不需要引入解码器的启发式设计,并且可以灵活地探索各种掩蔽策略。相应的部分在与传统方法相比的延迟中减少不到12%,同时实现更好的性能。
展示了该方法在几个大型基准(Waymo、KITTI和ONCE)上得到的效果。在下游检测任务中持续改进,说明了强大的鲁棒性和泛化能力。方法展示了最先进的结果,值得注意的是,即使在Waymo数据集上只有20%的标记数据,也实现了可比拟的准确性。代码在https://github.com/Nightmare-n/GD-MAE

二十五、语音相关
114、Conditional Generation of Audio from Video via Foley Analogies
添加到视频中的音效,旨在传达特定的艺术效果,但可能与场景的真实声音相差甚远。受到为视频创建与真实声音不同但仍能匹配屏幕上发生的动作的音轨的挑战的启发,提出了conditional Foley问题。提出以下解决方案来解决这个问题。
首先,提出了一个预训练任务,通过从同一源视频中采样的有条件音频-视觉剪辑来预测输入视频剪辑的声音。其次,提出了一个模型,用于生成无声输入视频的声音轨道,给定一个用户提供的示例,指定视频应该“听起来”像什么。
通过人类研究和自动评估指标表明,模型成功地从视频中生成声音,并根据提供的示例内容变化其输出。项目网站:https://xypb.github.io/CondFoleyGen/

115、Physics-Driven Diffusion Models for Impact Sound Synthesis from Videos
对物理对象交互发出的声音进行建模,对于真实和虚拟世界中的沉浸式感知体验至关重要。 传统的合成方法是通过物理模拟获得一组能够代表和合成声音的物理参数。 然而,它们需要物体几何形状和撞击位置的精细细节,这在现实世界中很少可用,并且不能应用于合成来自普通视频的撞击声音。 另一方面,现有的基于视频驱动的深度学习方法由于缺乏物理知识,只能捕获视觉内容和声音之间的微弱对应关系。
这项工作提出了一种物理驱动的扩散模型,可以为无声视频剪辑合成高保真冲击声。 除了视频内容,还使用额外的物理先验知识来指导冲击声合成过程。 物理先验包括无需复杂设置即可从嘈杂的现实世界撞击声音示例直接估计的物理参数,以及通过神经网络解释声音环境的学习残差参数。
实验结果表明,模型在生成逼真的冲击声方面优于现有的几个系统。 更重要的是,基于物理的表示是可解释和透明的,能灵活地进行声音编辑。 https://sukun1045.github.io/video-physics-sound-diffusion/

116、Sound to Visual Scene Generation by Audio-to-Visual Latent Alignment
音频如何描述我们周围的世界? 本文提出了一种从声音生成场景图像的方法。 方法解决了处理视觉和声音之间经常存在的巨大差距的挑战。
设计了一个模型,通过安排每个模型组件的学习过程来关联视听模式,尽管它们存在信息差距。 关键思想是通过学习将音频与视觉潜在空间对齐,用视觉信息丰富音频特征。 将输入的音频转换为视觉特征,然后使用预训练的生成器生成图像。 为了进一步提高生成的图像的质量,使用声源定位来选择具有强交叉模态相关性的视听对。
与之前的方法相比,在 VEGAS 和 VGGSound 数据集上获得了更好的结果。 还表明可以通过对输入波形或潜在空间进行简单操作来控制模型的预测。https://sound2scene.github.io/

二十六、域适应-迁移学习
117、Back to the Source: Diffusion-Driven Test-Time Adaptation
测试阶段适应(test-time adaptation),利用测试时的输入来提高在移动目标数据上的模型准确性。 现有方法通过在每个目标域上进行(重新)训练来更新源模型。 虽然有效,但重新训练对数据的数量和顺序以及用于优化的超参数需要调整。
本文通过使用生成扩散模型将所有测试输入投射到源域。 扩散驱动适应方法 DDA (diffusion-driven adaptation)在所有领域共享其分类和生成模型。 两种模型都在源域上训练,然后在测试期间固定。 通过图像引导和自集成来增强扩散,以自动决定适应的程度。
在 ImageNet-C 基准测试中,DDA 的输入自适应比之前的模型自适应方法在各种损坏、架构和数据机制中更稳健。
域,将扩展生成器以协调地联合建模所有新老域。
首先,注意到生成器包含一个有意义的、预训练好的潜在空间。 是否有可能在最大限度地表示新域的同时,最小限度地扰动这个来之不易的表示?有趣的是,发现潜在空间提供了未使用的“休眠”方向,这不会影响输出。 这提供了一个机会:通过“重新利用”这些方向,可以在不影响原始表示的情况下表示新的域。
事实上,发现预训练的生成器有能力添加几个甚至数百个新域!使用扩展方法,一个“扩展”模型可以取代许多领域特定的模型,而无需扩展模型大小。 此外,单个扩展生成器本机支持域之间的平滑转换,以及域的组合。
代码和项目页面可在这里:https://yotamnitzan.github.io/domain-expansion/

119、Zero-shot Generative Model Adaptation via Image-specific Prompt Learning
最近,clip引导的图像生成,在将预训练的源域生成器适应于看不见的目标域方面显示出了吸引人的性能。它不需要任何目标域样本,只需要文本域标签。训练效率很高。然而,现有的方法在生成图像的质量上仍然存在一定的局限性,并且可能存在模态崩溃问题。一个关键原因是对所有的跨域图像对采用固定的自适应方向,导致监督信号相同。
为了解决这个问题,提出一种图像特定提示学习(Image-specific Prompt Learning,IPL)方法,该方法对每个源域图像学习特定提示向量,提供了更精确的自适应方向,大大增强了目标域生成器的灵活性。各领域的定性和定量评价表明,IPL有效地提高了合成图像的质量和多样性,缓解了模态崩溃。此外,IPL独立于生成模型的结构,如生成对抗网络或扩散模型。
代码:https://github.com/Picsart-AI-Research/IPLZero-Shot-Generative-Model-Adaptation

二十七、知识蒸馏
120、KD-DLGAN: Data Limited Image Generation via Knowledge Distillation
生成对抗网络 (GAN) 严重依赖大规模训练数据来训练高质量图像生成模型。 在训练数据有限的情况下,GAN 鉴别器经常会出现严重的过拟合,这直接导致生成退化,尤其是在生成多样性方面。
受知识蒸馏 (KD) 最新进展的启发,提出了 KD-DLGAN,这是一种基于知识蒸馏的生成框架,它引入了预训练的视觉语言模型来训练有效的数据受限生成模型。 KD-DLGAN 由两个创新设计组成。 第一个是聚合生成 KD,它通过用更难的学习任务挑战鉴别器并从预训练模型中提取更普遍的知识来减轻鉴别器的过拟合。 第二种是相关生成 KD,它通过在预训练模型中提取和保留不同的图像-文本相关性来提高生成多样性。
在多个基准上进行的大量实验表明,KD-DLGAN 在有限的训练数据下实现了卓越的图像生成。

二十八、字体生成
121、CF-Font: Content Fusion for Few-shot Font Generation
内容和风格分离是实现少样本字体生成的有效方法,它可以将源域中的字体图像风格转换为目标域中用一些参考图像定义的风格。 但是,使用代表性字体提取的内容特征可能不是最佳的。 鉴于此,提出了一个内容融合模块(CFM),将内容特征投影到由基本字体的内容特征定义的线性空间中,这样可以考虑到不同字体引起的内容特征的变化。
方法还可以通过轻量级迭代样式向量优化 (ISR) 策略优化参考图像的风格表示向量。 此外,将字符图像的一维投影视为概率分布,并利用两个分布之间的距离作为重建损失(即投影字符损失,PCL)。 与L2或L1重建损失相比,分布距离更关注字符的全局形状。 在 300 种字体的数据集上评估方法,每种字体有 6.5k 个字符。 实验结果证实方法大大优于现有的最先进的少样本字体生成方法。
https://github.com/wangchi95/CF-Font

122、Handwritten Text Generation from Visual Archetypes
生成特定于作者风格的手写文本图像是一项具有挑战性的任务,尤其是在未见过的风格和新词的情况下,当后者包含在训练中很少遇到的字符时更是如此。 虽然最近生成模型解决了模仿作家风格的问题,但忽略了对稀有字符。
这项工作为 Few-Shot 风格的手写文本生成设计了一个基于 Transformer 的模型,并专注于获得文本和风格的稳健和信息丰富的表示。 特别是,提出了一种新的文本内容表示形式,即从以标准 GNU Unifont 字形编写的符号图像中获得的密集向量序列,可以将其视为它们的视觉原型。 这种策略更适合生成尽管在训练期间很少见到的字符,但可能与经常观察到的字符共享视觉细节。 至于风格,通过在大型合成数据集上进行特定的预训练,获得了看不见的作家书法的稳健表现。
定量和定性结果证明了方法在以不可见的风格和稀有字符生成单词方面的有效性,比现有的依赖独立的字符编码的方法更好。
二十九、异常检测
123、SQUID: Deep Feature In-Painting for Unsupervised Anomaly Detection
放射学成像协议(Radiography imaging protocols)侧重于特定身体区域,因此产生的图像非常相似,患者之间的解剖结构也是反复出现的。为了利用这种结构化信息,提出了“SQUID(面向空间的内存队列用于放射影像修补和异常检测)”的使用,该方法可以将内在的解剖结构分类为经常出现的模式,并在推理中可以识别图像中的异常(未见过/修改后的模式)。
在两个胸片基准数据集上,使用AUC评估方法,SQUID在无监督异常检测方面超过了13种最先进的方法,且差异至少为5。此外,还创建了一个新的数据集(DigitAnatomy),该数据集将胸部解剖的空间相关性和一致的形状结合在一起。希望DigitAnatomy能够促进异常检测方法的开发、评估和可解释性。
https://github.com/tiangexiang/SQUID

三十、数据集
124、An Image Quality Assessment Dataset for Portraits
对更好的智能手机照片的需求持续增长,特别是在人像摄影领域。因此,制造商在智能手机相机的整个开发过程中使用感知质量标准。这个昂贵的过程可以部分地被基于自动学习的图像质量评估(IQA)方法取代。由于其主观性,有必要估计和保证IQA过程的一致性,这是众包IQA广泛使用的平均意见分数(mean opinion scores, MOS)所缺乏的特征。此外,现有的盲IQA (BIQA)数据集很少关注跨内容评估的难度,这可能会降低标注的质量。
本文介绍PIQ23,一个特定于肖像的IQA数据集,由100部智能手机获取的50个预定义场景的5116张图像组成,涵盖了各种品牌、型号和用例。该数据集包括不同性别和种族的个人,他们明确并知情地同意将他们的照片用于公共研究。它是由30多位图像质量专家收集的三个图像属性的两两比较(PWC)注释的:面部细节保存,面部目标曝光和整体图像质量。对这些标注进行深入的统计分析使我们能够评估它们在PIQ23上的一致性。最后,通过与现有基线的广泛比较表明,语义信息(图像上下文)可用于改进IQA预测。
数据集以及提出的统计分析和BIQA算法在https://github.com/DXOMARKResearch/PIQ2023

125、CelebV-Text: A Large-Scale Facial Text-Video Dataset
文本驱动生成的模式在视频生成和编辑中蓬勃发展。然而,由于缺乏包含高质量视频和高度相关文本的合适数据集,以人脸为中心的文本到视频生成仍然是一个挑战。为了促进人脸文本-视频生成任务的研究,本文提出了一个大规模、多样化、高质量的人脸文本-视频对数据集CelebV-Text。
CelebV-Text包含70,000个具有不同视觉内容的野外人脸视频片段,每个视频片段与使用所提出的半自动文本生成策略生成的20个文本配对。所提供的文本质量很高,准确地描述了静态和动态属性。CelebV-Text优于其他数据集的优势是通过对视频、文本和文本-视频相关性的全面统计分析来证明的。采用具有代表性的方法构造了一个基准,对人脸文本-视频生成任务的评价进行了标准化。所有的数据和模型都是公开的:https://celebv-text.github.io/

126、Human-Art: A Versatile Human-Centric Dataset Bridging Natural and Artificial Scenes
自古以来,人类就以各种形式被记录下来。例如,在照相机发明之前,雕塑和绘画是描绘人类的主要媒介。然而,目前大多数以人类为中心的计算机视觉任务,如人体姿势估计和人体图像生成,都只关注现实世界中的自然图像。人造人,如雕塑、绘画和漫画中的人,通常被忽视,使现有的模型在这些场景中失败。艺术作为对生活的抽象,将人融入自然和人工的场景中。
本文引入Human-Art数据集来桥接自然和人工场景中的相关任务。具体来说,Human-Art包含来自5个自然场景和15个人工场景的超过12.3万个人实例的5万张高质量图像,这些图像用边界框、关键点和2D、3D表示的人类文本信息进行了标注。因此,对于各种下游任务,它是全面和通用的。还为相关任务提供了丰富的基线结果和详细分析,包括人体检测,2D和3D人体姿势估计,图像生成和运动传输。作为一个具有挑战性的数据集,希望Human-Art可以为相关研究提供参考,并开辟新的研究问题。

127、Uncurated Image-Text Datasets: Shedding Light on Demographic Bias
越来越多的人倾向于收集大量未经整理的数据集来训练视觉和语言模型,这引起了人们对公平表示的担忧。众所周知,即使是手工标注的小数据集,如MSCOCO,也会受到社会偏见的影响。这个问题非但没有得到解决,而且可能会变得更糟,因为从互联网上抓取的数据没有得到多少控制。此外,缺乏分析大量图像中社会偏见的工具,使得解决这个问题极具挑战性。
本文第一个贡献是标注了谷歌概念字幕数据集的一部分,该数据集广泛用于训练视觉和语言模型,具有四个人口统计属性和两个上下文属性。第二个贡献是对标注进行全面分析,重点关注不同的人口统计组是如何表示的。最后的贡献在于评估了三种流行的视觉和语言任务:图像描述、文本-图像CLIP嵌入和文本到图像的生成,表明社会偏见是所有这些任务中持续存在的问题。
https://github.com/noagarcia/phase

关注公众号【机器学习与AI生成创作】,更多精彩等你来读
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!
经典GAN不得不读:StyleGAN
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!
一杯奶茶,成为AIGC+CV视觉的前沿弄潮儿!
最新最全100篇汇总!生成扩散模型Diffusion Models
ECCV2022 | 生成对抗网络GAN部分论文汇总
CVPR 2022 | 25+方向、最新50篇GAN论文
ICCV 2021 | 35个主题GAN论文汇总
超110篇!CVPR 2021最全GAN论文梳理
超100篇!CVPR 2020最全GAN论文梳理
拆解组新的GAN:解耦表征MixNMatch
StarGAN第2版:多域多样性图像生成
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 |《计算机视觉中的数学方法》分享
《基于深度学习的表面缺陷检测方法综述》
《零样本图像分类综述: 十年进展》
《基于深度神经网络的少样本学习综述》
《礼记·学记》有云:独学而无友,则孤陋而寡闻文章来源:https://www.toymoban.com/news/detail-704391.html
点击一杯奶茶,成为AIGC+CV视觉的前沿弄潮儿!,加入 AI生成创作与计算机视觉 知识星球!文章来源地址https://www.toymoban.com/news/detail-704391.html
到了这里,关于卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完。的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!