[toc]
一、安装要求
在开始之前,部署Kubernetes集群机器需要满足以下几个条件:
- 一台或多台机器,操作系统 CentOS7.x-86_x64
- 硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘30GB或更多
- 集群中所有机器之间网络互通
- 可以访问外网,需要拉取镜像
- 禁止swap分区
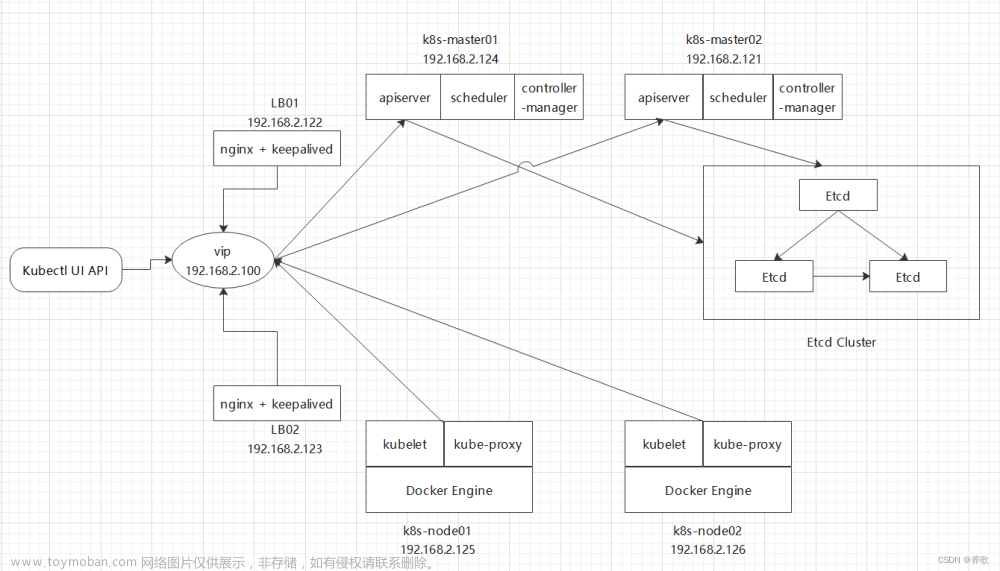
二、准备环境
| 角色 | IP |
|---|---|
| k8s-master1 | 192.168.4.114 |
| k8s-master2 | 192.168.4.119 |
| k8s-master3 | 192.168.4.120 |
| k8s-node1 | 192.168.4.115 |
| k8s-node2 | 192.168.4.116 |
| k8s-node3 | 192.168.4.118 |
#关闭防火墙:
systemctl stop firewalld
systemctl disable firewalld
#关闭selinux:
sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久
setenforce 0 # 临时
#关闭swap:
# 临时关闭
swapoff -a
# 永久
sed -ri 's/.*swap.*/#&/' /etc/fstab
#设置主机名:
hostnamectl set-hostname <hostname>
#在master添加hosts:
cat >> /etc/hosts << EOF
192.168.4.114 k8s-master1
192.168.4.119 k8s-master2
192.168.4.120 k8s-master3
192.168.4.115 k8s-node1
192.168.4.116 k8s-node2
192.168.4.118 k8s-node3
EOF
#将桥接的IPv4流量传递到iptables的链:
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sysctl --system
#重启网络即可
systemctl restart network
#时间同步:
yum install ntpdate -y
ntpdate time.windows.com
#修改时区
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
#修改语言
sudo echo 'LANG="en_US.UTF-8"' >> /etc/profile;source /etc/profile
- 升级内核
#备份
\cp /etc/default/grub /etc/default/grub-bak
#导入公钥
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
#安装yum源
yum install -y https://www.elrepo.org/elrepo-release-7.el7.elrepo.noarch.rpm
#安装内核
yum --enablerepo elrepo-kernel -y install kernel-lt
#设置5.4内核为默认启动内核
grub2-set-default 0
grub2-reboot 0
#查看内核版本
reboot
uname -r
yum update -y
#安装ipvs模块
yum install ipset ipvsadm -y
modprobe br_netfilter
#### 内核5.4 ####
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
EOF
################## 高版本的centos内核nf_conntrack_ipv4被nf_conntrack替换了
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack
三、安装containerd【所有节点】
【代码地址】
- https://github.com/containerd/containerd
1)安装containerd
#移除docker
sudo yum -y remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-selinux \
docker-engine-selinux \
docker-ce-cli \
docker-engine
#查看还有没有存在的docker组件
rpm -qa|grep docker
2)安装Containerd
#安装依赖及常用工具
yum install -y yum-utils device-mapper-persistent-data lvm2 wget vim yum-utils net-tools epel-release
#添加加载的内核模块
cat <<EOF | sudo tee /etc/modules-load.d/containerd.conf
overlay
br_netfilter
EOF
#加载内核模块
modprobe overlay
modprobe br_netfilter
3)配置源
#添加docker源,containerd也是在docker源内的。
【国外docker源】
#yum-config-manager \
# --add-repo \
# https://download.docker.com/linux/centos/docker-ce.repo
#【阿里云源】
cat <<EOF | sudo tee /etc/yum.repos.d/docker-ce.repo
[docker]
name=docker-ce
baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/x86_64/stable/
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg
EOF
#安装containerd
yum -y install containerd.io-1.6.22-3.1.el7.x86_64
# 指定版本使用containerd.io-x.x.x
# 需要升级系统则yum -y update
4)配置containerd
#默认是没有配置文件的,可以像k8s一样获取到一些默认配置。
mkdir -p /etc/containerd
containerd config default > /etc/containerd/config.toml
#配置systemd cgroup驱动(在配置文件中如下位置添加SystemdCgroup = true)
sed -i 's/SystemdCgroup = false/SystemdCgroup = true/g' /etc/containerd/config.toml
grep 'SystemdCgroup = true' -B 7 /etc/containerd/config.toml
5)设置crictl
- 使用除docke以外的CRI时,需要使用crictl来进行镜像管理,相当于docker-cli。
- Containerd只支持通过CRI拉取镜像的mirror,也就是说,只有通过crictl或者Kubernetes调用时mirror才会生效,通过ctr拉取是不会生效的。crictl是k8s内部的镜像管理命令。
cat << EOF >> /etc/crictl.yaml
runtime-endpoint: unix:///var/run/containerd/containerd.sock
image-endpoint: unix:///var/run/containerd/containerd.sock
timeout: 10
debug: false
EOF
6)镜像加速
#修改pause容器为阿里云的地址:
sed -i 's#sandbox_image = "registry.k8s.io/pause:3.6"#sandbox_image = "registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.8"#g' /etc/containerd/config.toml
#编辑Containerd的配置文件 /etc/containerd/config.toml, 在 [plugins."io.containerd.grpc.v1.cri".registry] 下方添加 config_path
[plugins."io.containerd.grpc.v1.cri".registry]
config_path = "/etc/containerd/certs.d"
#替换
sed -i 's#config_path = ""#config_path = "/etc/containerd/certs.d"#g' /etc/containerd/config.toml
#创建目录 /etc/containerd/certs.d/docker.io,在其中添加包含下面内容的 hosts.toml 文件
mkdir -pv /etc/containerd/certs.d/docker.io
cat >/etc/containerd/certs.d/docker.io/hosts.toml <<EOF
[host."https://dbxvt5s3.mirror.aliyuncs.com",host."https://registry.docker-cn.com",host."https://quay.mirrors.ustc.edu.cn",host."https://mn3d3160.mirror.aliyuncs.com"]
capabilities = ["pull"]
EOF
#重启生效
systemctl restart containerd
ctr version
7)启动
#启动服务
systemctl daemon-reload
systemctl enable --now containerd
#重启containerd
systemctl restart containerd
8)其他(不操作)
#如果你的环境中网络代理去访问外网,containerd也需要单独添加代理:
mkdir /etc/systemd/system/containerd.service.d
cat > /etc/systemd/system/containerd.service.d/http_proxy.conf << EOF
[Service]
Environment="HTTP_PROXY=http://<proxy_ip>:<proxy_port>/"
Environment="HTTPS_PROXY=http://<proxy_ip>:<proxy_port>/"
Environment="NO_PROXY=x.x.x.x,x.x.x.x"
EOF
四、部署Keepalived
1)安装
yum install keepalived psmisc -y
mv /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak
2)修改配置
所有master集群节点上,创建并编辑/etc/keepalive/keepalived.conf文件,
- 注意备节点服务器priority值需小于主节点
- 注意修改网卡名称和本服务器匹配
- 注意修改单播的源地址和主机组地址
cat>/etc/keepalived/keepalived.conf<<EOF
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL_A
vrrp_skip_check_adv_addr
#取消严格模式,开启icmp应答和vrrp单播通信(默认组播通信)
#vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
#脚本执行为root用户
script_user root
#非root 用户可以运行具有root 权限的脚本
enable_script_security
}
#定义检测方法
vrrp_script check_k8s {
#使用check_k8s.sh脚本检查k8s进程
script "/etc/keepalived/check_k8s.sh"
interval 2 #检查间隔2s
}
vrrp_instance VI_1 {
#服务器节点角色
state MASTER
#keepalived监听网卡
interface ens160
#虚拟路由器ID
virtual_router_id 52
#优先级(默认为100),越高优先。主节点高于备节点即可###
priority 110
#非抢占模式,防止VIP频繁漂移
nopreempt
#存活通告间隔1s
advert_int 1
authentication {
#认证方式为密码
auth_type PASS
#认证密码为1111,可自定义
auth_pass 1111
}
#配置keepalive vrrp单播的源地址,写本机上的ip即可
unicast_src_ip 192.168.4.114
#配置keepalive vrrp单播的目标地址,如果有多个主机组成集群,把其它主机ip都写上
unicast_peer {
192.168.4.119
192.168.4.120
}
#引用检测方法
track_script {
check_k8s
}
#指定集群虚拟IP地址,即VIP地址。
virtual_ipaddress {
192.168.4.100
}
}
EOF
- 上述问题存在故障,暂时使用下方文件
[root@k8s-master2 ~]# cat /etc/keepalived/keepalived.conf
global_defs {
router_id keepalive-master
}
vrrp_script check_apiserver {
# 检测脚本路径
script "/etc/keepalived/check_k8s.sh"
# 多少秒检测一次
interval 3
# 失败的话权重-2
weight -2
}
vrrp_instance VI-kube-master {
state MASTER # 定义节点角色
interface ens160 # 网卡名称
virtual_router_id 68
priority 90
dont_track_primary
advert_int 3
virtual_ipaddress {
# 自定义虚拟ip
192.168.4.100
}
track_script {
check_k8s.sh
}
}
3)创建判断脚本
#创建check_k8s.sh检测脚本
[root@master1 ~]# vim /etc/keepalived/check_k8s.sh
#!/bin/bash
#获取操作系统盘、数据盘的磁盘容量百分比、K8S服务运行情况
root_percent=`df -h |grep root |awk '{ print $5 }'|awk -F % '{ print $1 }'`
data_percent=`df -h |grep /data$ |awk '{ print $5 }'|awk -F % '{ print $1 }'`
ID0=`ps -ef |grep -E "kube-proxy|kube-apiserver|kubelet|kube-scheduler|kube-scheduler|kube-scheduler" |wc -l`
curl -s 127.0.0.1:6443 >> /dev/null
ID1=`echo $?`
if [ $root_percent -gt 95 ] || [ $data_percent -gt 95 ];then
exit 1;
elif [ "$ID0" -ne 5 ] || [ "$ID1" -ne 0 ];then
exit 2;
else
exit 0;
fi
#加载keepalived.conf配置文件
keepalived -D -f /etc/keepalived/keepalived.conf
#检查keepalived.conf配置文件是否加载成功
keepalived -l
#脚本授权
chmod o+x /etc/keepalived/check_k8s.sh
#开放Keepalived防火墙规则
# firewall-cmd --direct --permanent --add-rule ipv4 filter INPUT 0 --in-interface ens160 --destination 0.0.0.0/0 --protocol vrrp -j ACCEPT
# firewall-cmd --reload
4)配置keepalived日志
#配置keepalived
[root@lb02 ~]# vim /etc/sysconfig/keepalived
KEEPALIVED_OPTIONS="-D -d -S 0"
#配置rsyslog
[root@lb02 ~]# vim /etc/rsyslog.conf
local0.* /var/log/keepalived.log
#重启服务
[root@lb02 ~]# systemctl restart rsyslog
[root@lb02 ~]# systemctl restart keepalived
#查看日志
[root@lb02 ~]# tail -f /var/log/keepalived.log
五、部署kubeadm/kubelet
1)添加kubernetes源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
2)安装kubeadm
由于版本更新频繁,这里指定版本号部署:
yum install -y kubelet-1.25.0 kubeadm-1.25.0 kubectl-1.25.0
systemctl statrt kubelet
systemctl enable kubelet
kubelet --version
3)测试(部署kubeadm可测)
#下载镜像检测containerd是否正常:
crictl pull docker.io/library/nginx:alpine
crictl images ls
crictl rmi docker.io/library/nginx:alpine
#查看是否生效(如果显示了镜像加速地址(路径)则代表生效)
crictl info|grep -A 5 registry
六、部署Kubernetes Master
1)部署kubeadm
kubeadm init \
--kubernetes-version v1.25.0 \
--image-repository registry.aliyuncs.com/google_containers \
--service-cidr=172.18.0.0/16 \
--pod-network-cidr=10.244.0.0/16 \
--control-plane-endpoint=192.168.4.100:6443 \
--cri-socket=/run/containerd/containerd.sock \
--upload-certs \
--v=5
选项说明:
- –image-repository:选择用于拉取镜像的镜像仓库(默认为“k8s.gcr.io” )
- –kubernetes-version:选择特定的Kubernetes版本(默认为“stable-1”)
- –service-cidr:为服务的VIP指定使用的IP地址范围(默认为“10.96.0.0/12”)
- –pod-network-cidr:指定Pod网络的IP地址范围。如果设置,则将自动为每个节点分配CIDR。
- –cri-socket:指定cri为containerd
# 要开始使用集群,您需要以常规用户身份运行以下命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 或者,如果您是root用户,则可以运行允许命令
export KUBECONFIG=/etc/kubernetes/admin.conf
# 加入.bashrc,方便以后连接服务器自动执行
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >>/root/.bashrc
1
- master2和master3添加
kubeadm join 192.168.4.100:6443 --token dggl7z.ghw4vace28dranzt \
--discovery-token-ca-cert-hash sha256:256d6629de1416cddefe77fd4e3a12147d23ee391213b726949cf52975082fd1 \
--control-plane --certificate-key c84c4161c3895904819fb457280da98a3bac58ed389cde14e8825b45d4741b89
2)安装自动补全
# 配置自动补全命令(三台都需要操作)
yum -y install bash-completion
# 设置kubectl与kubeadm命令补全,下次login生效
kubectl completion bash > /etc/bash_completion.d/kubectl
kubeadm completion bash > /etc/bash_completion.d/kubeadm
#退出重新登录生效
exit
3)数据目录修改
- https://blog.csdn.net/qq_39826987/article/details/126473129?spm=1001.2014.3001.5502
七、添加Node节点
- 在192.168.4.114/115/118(Node)执行。
#向集群添加新节点,执行在kubeadm init输出的kubeadm join命令
kubeadm join 192.168.4.100:6443 --token dggl7z.ghw4vace28dranzt \
--discovery-token-ca-cert-hash sha256:256d6629de1416cddefe77fd4e3a12147d23ee391213b726949cf52975082fd1
[root@k8s-master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master1 NotReady control-plane 2m31s v1.25.0
k8s-master2 NotReady <none> 28s v1.25.0
k8s-master3 NotReady <none> 25s v1.25.0
k8s-node1 NotReady <none> 87s v1.25.0
k8s-node2 NotReady <none> 97s v1.25.0
k8s-node3 NotReady <none> 95s v1.25.0
[root@k8s-master1 ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true","reason":""}
#默认token有效期为24小时,当过期之后,该token就不可用了。这时就需要重新创建token,可以直接使用命令快捷生成:
kubeadm token create --print-join-command
【参考添加节点】
- https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-join/
八、部署容器网络(CNI)
1)官网
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/#pod-network
注意:只需要部署下面其中一个,推荐Calico。
Calico是一个纯三层的数据中心网络方案,Calico支持广泛的平台,包括Kubernetes、OpenStack等。
Calico 在每一个计算节点利用 Linux Kernel 实现了一个高效的虚拟路由器( vRouter) 来负责数据转发,而每个 vRouter 通过 BGP 协议负责把自己上运行的 workload 的路由信息向整个 Calico 网络内传播。
此外,Calico 项目还实现了 Kubernetes 网络策略,提供ACL功能。
【官方说明】
- https://docs.projectcalico.org/getting-started/kubernetes/quickstart
【git地址】
- https://github.com/projectcalico/calico
【部署地址】
- https://docs.tigera.io/archive/v3.25/manifests/calico.yaml
【说明】
- https://blog.csdn.net/ma_jiang/article/details/124962352
2)部署修改
# --no-check-certificate
wget https://docs.tigera.io/archive/v3.25/manifests/calico.yaml --no-check-certificate
下载完后还需要修改里面定义Pod网络(CALICO_IPV4POOL_CIDR),与前面kubeadm init指定的一样
修改完后应用清单:
#修改为:
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16"
key: calico_backend
# Cluster type to identify the deployment type
- name: CLUSTER_TYPE
value: "k8s,bgp"
# 下方新增
- name: IP_AUTODETECTION_METHOD
value: "interface=ens160"
# ens160为本地网卡名字
3)更换模式为bgp
#修改CALICO_IPV4POOL_IPIP为Never,不过这种方式只适用于第一次部署,也就是如果已经部署了IPIP模式,这种方式就不奏效了,除非把calico删除,修改。
#更改IPIP模式为bgp模式,可以提高网速,但是节点之前相互不能通信。
- name: CALICO_IPV4POOL_IPIP
value: "Always"
#修改yaml
- name: CALICO_IPV4POOL_IPIP
value: "Never"
【报错】Warning: policy/v1beta1 PodDisruptionBudget is deprecated in v1.21+, unavailable in v1.25+; use policy/v1 PodDisruptionBudget
【原因】api版本已经过期,需要修改下。
将apiVersion: policy/v1beta1 修改为apiVersion: policy/v1
【报错】
Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "0b2f62ae0e97048b9d2b94bd5b2642fd49d1bc977c8db06493d66d1483c6cf45": plugin type="calico" failed (add): stat /var/lib/calico/nodename: no such file or directory: check that the calico/node container is running and has mounted /var/lib/calico/
【解决】
# 下方熙增新增
- name: IP_AUTODETECTION_METHOD
value: "interface=ens160"
# ens160为本地网卡名字
| 源站 | 替换为 |
|---|---|
| cr.l5d.io | l5d.m.daocloud.io |
| docker.elastic.co | elastic.m.daocloud.io |
| docker.io | docker.m.daocloud.io |
| gcr.io | gcr.m.daocloud.io |
| ghcr.io | ghcr.m.daocloud.io |
| k8s.gcr.io | k8s-gcr.m.daocloud.io |
| registry.k8s.io | k8s.m.daocloud.io |
| mcr.microsoft.com | mcr.m.daocloud.io |
| nvcr.io | nvcr.m.daocloud.io |
| quay.io | quay.m.daocloud.io |
| registry.jujucharms.com | jujucharms.m.daocloud.io |
| rocks.canonical.com | rocks-canonical.m.daocloud.io |
#更换镜像
#:%s/docker.io/docker.m.daocloud.io/g
#拉取镜像
crictl pull docker.io/calico/cni:v3.25.0
crictl pull docker.io/calico/node:v3.25.0
crictl pull docker.io/calico/kube-controllers:v3.25.0
#生效
kubectl apply -f calico.yaml
kubectl get pods -n kube-system
4)更改网络模式为ipvs
- 升级之前先确定内核版本为5
#修改网络模式为IPVS
[root@k8s-master ~]# kubectl edit -n kube-system cm kube-proxy
修改:将mode: " "
修改为mode: “ipvs”
:wq保存退出
#看kube-system命名空间下的kube-proxy并删除,删除后,k8s会自动再次生成,新生成的kube-proxy会采用刚刚配置的ipvs模式
kubectl get pod -n kube-system |grep kube-proxy |awk '{system("kubectl delete pod "$1" -n kube-system")}'
#清除防火墙规则
iptables -t filter -F; iptables -t filter -X; iptables -t nat -F; iptables -t nat -X;
systemctl restart containerd
#查看日志,确认使用的是ipvs,下面的命令,将proxy的名字换成自己查询出来的名字即可
[root@k8s-master ~]# kubectl get pod -n kube-system | grep kube-proxy
kube-proxy-2bvgz 1/1 Running 0 34s
kube-proxy-hkctn 1/1 Running 0 35s
kube-proxy-pjf5j 1/1 Running 0 38s
kube-proxy-t5qbc 1/1 Running 0 36s
[root@k8s-master ~]# kubectl logs -n kube-system kube-proxy-pjf5j
I0303 04:32:34.613408 1 node.go:163] Successfully retrieved node IP: 192.168.50.116
I0303 04:32:34.613505 1 server_others.go:138] "Detected node IP" address="192.168.50.116"
I0303 04:32:34.656137 1 server_others.go:269] "Using ipvs Proxier"
I0303 04:32:34.656170 1 server_others.go:271] "Creating dualStackProxier for ipvs"
#通过ipvsadm命令查看是否正常,判断ipvs开启了
[root@k8s-master ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.17.0.1:32684 rr
-> 10.244.36.65:80 Masq 1 0 0
TCP 192.168.50.114:32684 rr
-> 10.244.36.65:80 Masq 1 0 0
TCP 10.96.0.1:443 rr
-> 192.168.50.114:6443 Masq 1 0 0
TCP 10.96.0.10:53 rr
-> 10.244.36.64:53 Masq 1 0 0
-> 10.244.169.128:53 Masq 1 0 0
TCP 10.96.0.10:9153 rr
-> 10.244.36.64:9153 Masq 1 0 0
-> 10.244.169.128:9153 Masq 1 0 0
TCP 10.105.5.170:80 rr
-> 10.244.36.65:80 Masq 1 0 0
UDP 10.96.0.10:53 rr
-> 10.244.36.64:53 Masq 1 0 0
-> 10.244.169.128:53 Masq 1 0 0
5)kube-promethues坑
服务暴露分为两种方式,可以使用ingress或NodePort的方式将服务暴露出去使宿主机可以进行访问。注意如果集群使用的如果是calico网络的话会默认创建出若干条网络规则导致服务暴露后也无法在客户端进行访问。可将网络策略修改或直接删除。文章来源地址https://www.toymoban.com/news/detail-704712.html
root@master01:~# kubectl get networkpolicies.networking.k8s.io -n monitoring
NAME POD-SELECTOR AGE
alertmanager-main app.kubernetes.io/component=alert-router,app.kubernetes.io/instance=main,app.kubernetes.io/name=alertmanager,app.kubernetes.io/part-of=kube-prometheus 14h
blackbox-exporter app.kubernetes.io/component=exporter,app.kubernetes.io/name=blackbox-exporter,app.kubernetes.io/part-of=kube-prometheus 14h
grafana app.kubernetes.io/component=grafana,app.kubernetes.io/name=grafana,app.kubernetes.io/part-of=kube-prometheus 14h
kube-state-metrics app.kubernetes.io/component=exporter,app.kubernetes.io/name=kube-state-metrics,app.kubernetes.io/part-of=kube-prometheus 14h
node-exporter app.kubernetes.io/component=exporter,app.kubernetes.io/name=node-exporter,app.kubernetes.io/part-of=kube-prometheus 14h
prometheus-adapter app.kubernetes.io/component=metrics-adapter,app.kubernetes.io/name=prometheus-adapter,app.kubernetes.io/part-of=kube-prometheus 14h
prometheus-operator app.kubernetes.io/component=controller,app.kubernetes.io/name=prometheus-operator,app.kubernetes.io/part-of=kube-prometheus 14h
root@master01:~# kubectl delete networkpolicies.networking.k8s.io grafana -n monitoring
networkpolicy.networking.k8s.io "grafana" deleted
root@master01:~# kubectl delete networkpolicies.networking.k8s.io alertmanager-main -n monitoring
networkpolicy.networking.k8s.io "alertmanager-main" deleted
- 注:在release-0.11版本之后新增了NetworkPolicy
- 默认是允许自己访问,如果了解NetworkPolicy可以修改一下默认的规则,可以用查看 ls networkPolicy,如果不修改的话则会影响到修改NodePort类型也无法访问
- 如果不会Networkpolicy可以直接删除就行
九、测试kubernetes集群
- 验证Pod工作
- 验证Pod网络通信
- 验证DNS解析
在Kubernetes集群中创建一个pod,验证是否正常运行:
kubectl create deployment nginx --image=nginx:
kubectl expose deployment nginx --port=80 --type=NodePort
kubectl get pod,svc
访问地址:http://NodeIP:Port
#查看日志
journalctl -u kube-scheduler
journalctl -xefu kubelet #实时刷新
journalctl -u kube-apiserver
journalctl -u kubelet |tail
journalctl -xe
【参考】https://blog.csdn.net/agonie201218/article/details/127878279
十、部署 Dashboard
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.3/aio/deploy/recommended.yaml
默认Dashboard只能集群内部访问,修改Service为NodePort类型,暴露到外部:
$ vi recommended.yaml
...
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
ports:
- port: 443
targetPort: 8443
nodePort: 30000
selector:
k8s-app: kubernetes-dashboard
type: NodePort
...
$ kubectl apply -f recommended.yaml
$ kubectl get pods -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
dashboard-metrics-scraper-6b4884c9d5-gl8nr 1/1 Running 0 13m
kubernetes-dashboard-7f99b75bf4-89cds 1/1 Running 0 13m
访问地址:https://NodeIP:30000
创建service account并绑定默认cluster-admin管理员集群角色:
# 创建用户
kubectl create serviceaccount dashboard-admin -n kube-system
# 用户授权
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
#解决WEB页面报错
kubectl create clusterrolebinding system:anonymous --clusterrole=cluster-admin --user=system:anonymous
#访问:https://node节点:30000/
https://192.168.4.115:30000/
# 获取用户Token
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
使用输出的token登录Dashboard。
十一、解决谷歌不能登录dashboard
#查看
kubectl get secrets -n kubernetes-dashboard
#删除默认的secret,用自签证书创建新的secret
kubectl delete secret kubernetes-dashboard-certs -n kubernetes-dashboard
#创建ca
openssl genrsa -out ca.key 2048
openssl req -new -x509 -key ca.key -out ca.crt -days 3650 -subj "/C=CN/ST=HB/L=WH/O=DM/OU=YPT/CN=CA"
openssl x509 -in ca.crt -noout -text
#签发Dashboard证书
openssl genrsa -out dashboard.key 2048
openssl req -new -key dashboard.key -out dashboard.csr -subj "/O=white/CN=dasnboard"
openssl x509 -req -in dashboard.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out dashboard.crt -days 3650
#生成新的secret
kubectl create secret generic kubernetes-dashboard-certs --from-file=dashboard.crt=/opt/dashboard/dashboard.crt --from-file=dashboard.key=/opt/dashboard/dashboard.key -n kubernetes-dashboard
# 删除默认的secret,用自签证书创建新的secret
#kubectl create secret generic #kubernetes-dashboard-certs \
#--from-file=/etc/kubernetes/pki/apiserver.key \
#--from-file=/etc/kubernetes/pki/apiserver.crt \
#-n kubernetes-dashboard
# vim recommended.yaml 加入证书路径
args:
- --auto-generate-certificates
- --tls-key-file=dashboard.key
- --tls-cert-file=dashboard.crt
# - --tls-key-file=apiserver.key
# - --tls-cert-file=apiserver.crt
#重新生效
kubectl apply -f recommended.yaml
#删除pods重新生效
kubectl get pod -n kubernetes-dashboard | grep -v NAME | awk '{print "kubectl delete po " $1 " -n kubernetes-dashboard"}' | sh
访问:https://192.168.4.116:30000/#/login
# 获取用户Token
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
十二、安装metrics
#下载
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.5.0
#改名
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.5.0 k8s.gcr.io/metrics-server/metrics-server:v0.5.0
#删除已经改名镜像
docker rmi -f registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.5.0
#创建目录
mkdir -p /opt/k8s/metrics-server
cd /opt/k8s/metrics-server
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-view: "true"
name: system:aggregated-metrics-reader
rules:
- apiGroups:
- metrics.k8s.io
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- pods
- nodes
- nodes/stats
- namespaces
- configmaps
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
ports:
- name: https
port: 443
protocol: TCP
targetPort: https
selector:
k8s-app: metrics-server
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: metrics-server
strategy:
rollingUpdate:
maxUnavailable: 0
template:
metadata:
labels:
k8s-app: metrics-server
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
- --kubelet-insecure-tls
image: k8s.gcr.io/metrics-server/metrics-server:v0.5.0
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /livez
port: https
scheme: HTTPS
periodSeconds: 10
name: metrics-server
ports:
- containerPort: 443
name: https
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /readyz
port: https
scheme: HTTPS
initialDelaySeconds: 20
periodSeconds: 10
resources:
requests:
cpu: 100m
memory: 200Mi
securityContext:
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
volumeMounts:
- mountPath: /tmp
name: tmp-dir
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-cluster-critical
serviceAccountName: metrics-server
volumes:
- emptyDir: {}
name: tmp-dir
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 100
十三、crictl管理容器
crictl 是 CRI 兼容的容器运行时命令行接口。 你可以使用它来检查和调试 Kubernetes 节点上的容器运行时和应用程序。 crictl 和它的源代码在 cri-tools 代码库。
【视频】https://asciinema.org/a/179047
【使用网址】https://kubernetes.io/zh/docs/tasks/debug-application-cluster/crictl/
十四、常用命令
1、常用命令
#查看master组件状态:
kubectl get cs
#查看node状态:
kubectl get node
#查看Apiserver代理的URL:
kubectl cluster-info
#查看集群详细信息:
kubectl cluster-info dump
#查看资源信息:
kubectl describe <资源> <名称>
#查看K8S信息
kubectl api-resources
2、命令操作+
[root@k8s-master ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused
etcd-0 Healthy {"health":"true"}
#修改yaml,注释掉port
$ vim /etc/kubernetes/manifests/kube-scheduler.yaml
$ vim /etc/kubernetes/manifests/kube-controller-manager.yaml
# - --port=0
#重启
systemctl restart kubelet
#查看master组件
[root@k8s-master ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}
命令区别文章来源:https://www.toymoban.com/news/detail-704712.html
| 命令 | docker | ctr(containerd) | crictl(kubernetes) |
|---|---|---|---|
| 查看运行的容器 | docker ps | ctr task ls/ctr container ls | crictl ps |
| 查看镜像 | docker images | ctr image ls | crictl images |
| 查看容器日志 | docker logs | 无 | crictl logs |
| 查看容器数据信息 | docker inspect | ctr container info | crictl inspect |
| 查看容器资源 | docker stats | 无 | crictl stats |
| 启动/关闭已有的容器 | docker start/stop | ctr task start/kill | crictl start/stop |
| 运行一个新的容器 | docker run | ctr run | 无(最小单元为pod) |
| 修改镜像标签 | docker tag | ctr image tag | 无 |
| 创建一个新的容器 | docker create | ctr container create | crictl create |
| 导入镜像 | docker load | ctr -n k8s.io i import | 无 |
| 导出镜像 | docker save | ctr -n k8s.io i export | 无 |
| 删除容器 | docker rm | ctr container rm | crictl rm |
| 删除镜像 | docker rmi | ctr -n k8s.io i rm | crictl rmi |
| 拉取镜像 | docker pull | ctr -n k8s.io i pull -k | ctictl pull |
| 推送镜像 | docker push | ctr -n k8s.io i push -k | 无 |
| 在容器内部执行命令 | docker exec | 无 | crictl exec |
十五、kube-promethues使用坑
服务暴露分为两种方式,可以使用ingress或NodePort的方式将服务暴露出去使宿主机可以进行访问。注意如果集群使用的如果是calico网络的话会默认创建出若干条网络规则导致服务暴露后也无法在客户端进行访问。可将网络策略修改或直接删除。
root@master01:~# kubectl get networkpolicies.networking.k8s.io -n monitoring
NAME POD-SELECTOR AGE
alertmanager-main app.kubernetes.io/component=alert-router,app.kubernetes.io/instance=main,app.kubernetes.io/name=alertmanager,app.kubernetes.io/part-of=kube-prometheus 14h
blackbox-exporter app.kubernetes.io/component=exporter,app.kubernetes.io/name=blackbox-exporter,app.kubernetes.io/part-of=kube-prometheus 14h
grafana app.kubernetes.io/component=grafana,app.kubernetes.io/name=grafana,app.kubernetes.io/part-of=kube-prometheus 14h
kube-state-metrics app.kubernetes.io/component=exporter,app.kubernetes.io/name=kube-state-metrics,app.kubernetes.io/part-of=kube-prometheus 14h
node-exporter app.kubernetes.io/component=exporter,app.kubernetes.io/name=node-exporter,app.kubernetes.io/part-of=kube-prometheus 14h
prometheus-adapter app.kubernetes.io/component=metrics-adapter,app.kubernetes.io/name=prometheus-adapter,app.kubernetes.io/part-of=kube-prometheus 14h
prometheus-operator app.kubernetes.io/component=controller,app.kubernetes.io/name=prometheus-operator,app.kubernetes.io/part-of=kube-prometheus 14h
root@master01:~# kubectl delete networkpolicies.networking.k8s.io grafana -n monitoring
networkpolicy.networking.k8s.io "grafana" deleted
root@master01:~# kubectl delete networkpolicies.networking.k8s.io alertmanager-main -n monitoring
networkpolicy.networking.k8s.io "alertmanager-main" deleted
- 注:在release-0.11版本之后新增了NetworkPolicy
- 默认是允许自己访问,如果了解NetworkPolicy可以修改一下默认的规则,可以用查看 ls networkPolicy,如果不修改的话则会影响到修改NodePort类型也无法访问
- 如果不会Networkpolicy可以直接删除就行
到了这里,关于高可用containerd搭建K8s集群【v1.25】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!