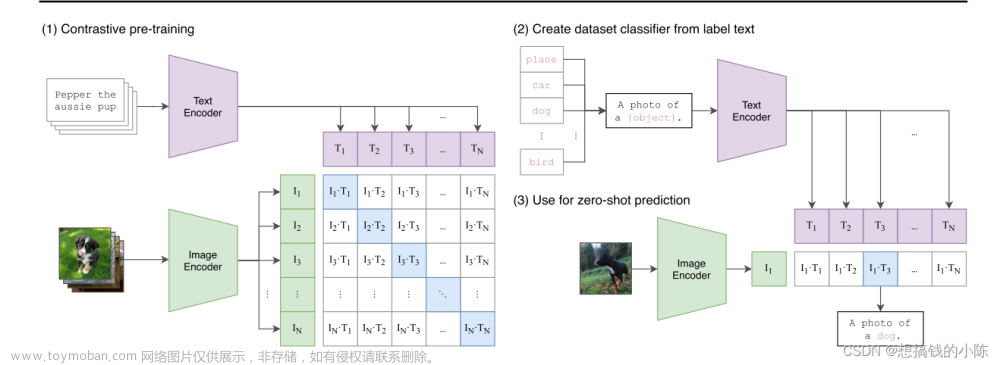
概念
是一个由 OpenAI 开发的深度学习模型,它融合了文本和图像的信息,以便同时理解和生成文本和图像。CLIP 可以执行各种任务,包括图像分类、文本描述生成、图像生成以文本描述等。
多模态 CLIP 的核心思想是使用对比学习来训练一个模型,使其能够理解文本和图像之间的关系。它使用了大量的文本和图像数据对模型进行预训练,然后可以通过微调来适应特定的任务。文章来源:https://www.toymoban.com/news/detail-705088.html
CLIP 的多模态能力使其非常强大,可以用于各种应用,例如图像搜索、文本到图像的生成、图像到文本的描述生成、情感分析等等。这使得它成为了深度学习领域中一个重要的多模态模型。文章来源地址https://www.toymoban.com/news/detail-705088.html
代码实现
import torch
import clip
from PIL import Image
# 加载 CLIP 模型和标记器
device = "cuda" if torch.cuda.is_available() else "cpu"
model, transform = clip.load("ViT-B/32", device=device)
# 图像和文本输入
image_path = "your_image.jpg"
text_input = ["a photo of a cat", "a painting of a sunset"]
# 对图像进行预处理
image = transform(Image.open(image_path)).unsqueeze(0).to(device)
# 对文本进行编码
text_inputs = torch.cat([clip.tokenize(text) for text in text_input]).to(device)
# 获取 CLIP 模型的编码
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text_inputs)
# 计算图像和文本之间的相似性
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
# 输出相似性得分
print("Similarity scores between image and text:")
for i, text in enumerate(text_input):
print(f"{text}: {similarity[0, i].item():.2f}")
到了这里,关于CLIP(Contrastive Language-Image Pretraining)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!