目录
1、消费者、消费组
2、心跳机制
3、消费者常见参数配置
4、订阅
5、反序列化
基本概念
自定义反序列化器
6、位移提交
6.1、自动提交
6.2、手动提交
同步提交
异步提交
7、再均衡
7.1、定义与基本概念
7.2、缺陷
7.3、如何避免再均衡
7.4、如何进行组内分区分配
7.5、谁来执行再均衡和消费组管理
8、消费者拦截器
作用
自定义消费者拦截器
1、消费者、消费组
- 消费者从订阅的主题消费消息,消费消息的偏移量保存在kafka中的__consumer_offsets的主题中。
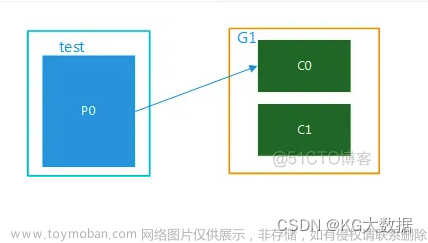
- 多个消费同一个主题的消费者,可以通过group.id配置,加入到同一个消费组中。消费组均衡地给消费者分配分区,每个分区只由消费组中的一个消费者消费,防止重复消费。
- 同一个消费组里:一个分区只会对应一个消费者,但一个消费者可以消费多个分区。
- group_id一半设置为应用或者业务的逻辑名称。

2、心跳机制


- 消费者宕机,退出消费组,触发再平衡,重新给消费组中的消费者分配分区;
- broker宕机,分区3重选leader副本,出发再平衡,重新分配分区3消息。
心跳机制,就是consumer和broker之间的健康检查。consumer和broker之间保持长连接,通过心跳机制检测对方是否健康。心跳检测相关参数如下所示:

在broker端,可配置sessionTimeoutMs参数,如果consumer心跳超期,broker会把消费者从消费组中移除,并触发再平衡,重新分配分区;
在consumer端,可配置sessionTimeoutMs和rebalanceTimeoutMs参数,如果broker心跳超期,consumer则会告知broker主动退出消费组,并触发再平衡。
3、消费者常见参数配置

4、订阅

主题、分区(leader和follower分区)、消费者、消费组、订阅。
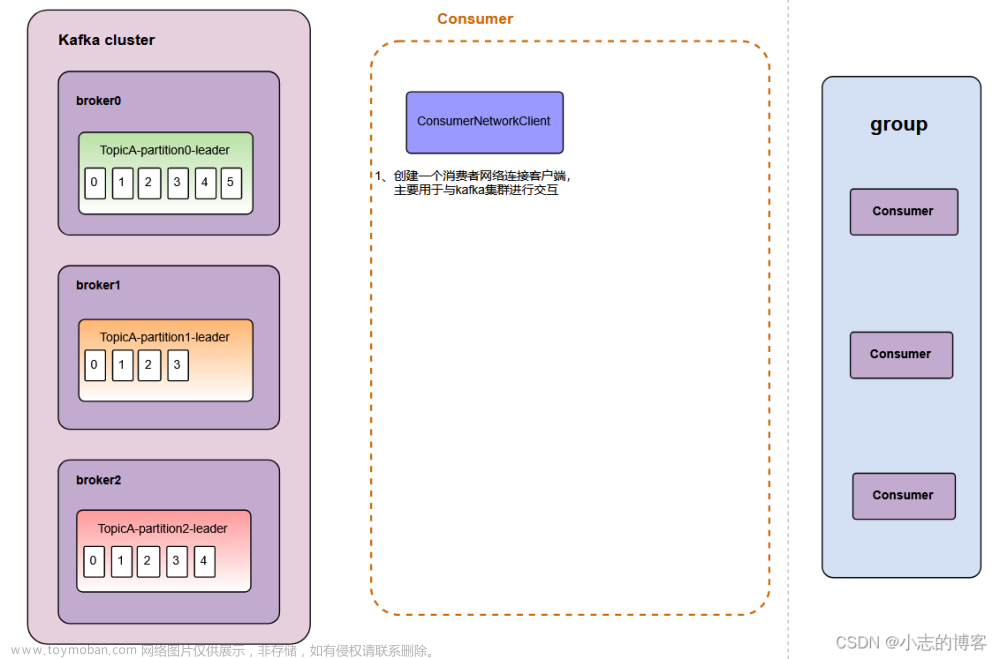
- 主题:topic,用于分类管理消息的逻辑单元,可以用于区分业务类型;
- 分区:partition,同一个topic的消息,会被分散到多个分区中,不同分区通常在不同broker上,方便水平扩展。分区可分为leader分区和follower分区,leader分区用于与生产者/消费者通信,follower分区用于备份leader分区的数据;
- 消费者:与分区长连接,用于消费分区中的消息;
- 消费组:消费组中可能会有多个消费者,保证一个消费组获取到特定主题的全部消息。消费组可以保证一个主题的分区只会被消费组中的一个消费者消费;
- 订阅:消费者订阅主题,并将消费者加入到消费组中,采用pull模式,从broker分区中读取消息。kafka的消费者只有pull模式,该模式下消费者可以自主控制消费消息的速率。
5、反序列化
基本概念
- 在Kafka中保存的数据都是字节数组。
- 消息者接收消息后,需要将消息反序列化为指定的数据格式进行处理。
- 消费者通过key.deserializer和value.deserializer指定key和value的序列化器。
- Kafka使用org.apache.kafka.common.serialization.Deserializer<T>接口定义序列化器。
- Kafka已实现的序列化器有:ByteArrayDeserializer、ByteBufferDeserializer、BytesDeserializer、DoubleDeserializer、FloatDeserializer、IntegerDeserializer、StringDeserializer、LongDeserializer、ShortDeserializer。
自定义反序列化器
实现org.apache.kafka.common.serialization.Deserializer<T>接口,并实现其中的deserializer方法。
public class UserDeserializer implements Deserializer<User> {
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
}
@Override
public User deserialize(String topic, byte[] data) {
ByteBuffer allocate = ByteBuffer.allocate(data.length);
allocate.put(data);
allocate.flip();
int userId = allocate.getInt();
int length = allocate.getInt();
System.out.println(length);
String username = new String(data, 8, length);
return new User(userId, username);
}
@Override
public void close() {
}
}6、位移提交
- 位移 = kafka分区消息的偏移量。
- kafka中有一个主题,专门用于保存消费者的偏移量。
- 消费者与分区一一对应,消费者在消费分区消息时,需要向kafka提交自己的位移(偏移量)信息,kafka只记录该消费者在对应分区的偏移量信息。
- 消费者向kafka提交偏移量的过程,叫做位移提交。
- 位移提交,分为自动提交和手动提交;也分为同步提交和异步提交。
6.1、自动提交
- 开启⾃动提交: enable.auto.commit=true,kafka默认为自动提交。
- 配置⾃动提交间隔:Consumer端: auto.commit.interval.ms ,默认 5s。
- Consumer 每 5s 提交一次offset
- 假设提交 offset 后的 3s 发⽣了 Rebalance
- Rebalance 之后的所有 Consumer 从上⼀次提交的 offset 处继续消费
- 因此 Rebalance 发⽣前 3s 的消息会被重复消费
6.2、手动提交
同步提交
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
process(records); // 处理消息
try {
consumer.commitSync();
} catch (CommitFailedException e) {
handle(e); // 处理提交失败异常
}
}- 使⽤ KafkaConsumer#commitSync(),会提交 KafkaConsumer#poll() 返回的最新 offset
- ⼿动同步提交可以控制offset提交的时机和频率
- 调⽤ commitSync 时,Consumer 处于阻塞状态,直到 Broker 返回结果
- 会影响 TPS
- 如果提交间隔过长,consumer重启后,会有更多的消息被重复消费。
异步提交
while (true) {
ConsumerRecords<String, String> records = consumer.poll(3_000);
process(records); // 处理消息
consumer.commitAsync((offsets, exception) -> {
if (exception != null) {
handle(exception);
}
});
}- 使⽤ KafkaConsumer#commitAsync():会提交 KafkaConsumer#poll() 返回的最新 offset
- commitAsync出现问题不会⾃动重试,可通过异步提交与同步提交相结合的方式解决。
7、再均衡
7.1、定义与基本概念
也叫做重平衡,主要是为了让消费组下的消费者来重新分配主题下的每一个分区。再均衡的触发条件有如下三个:
- 消费组内成员变更(增加和减少消费者),⽐如消费者宕机退出消费组,或者新增一个消费者。
- 主题的分区数发⽣变更,kafka⽬前只⽀持增加分区,当增加的时候就会触发再均衡。
- 订阅的主题发⽣变化,比如消费者组使⽤正则表达式订阅主题,⽽恰好⼜新建了对应的主题,就会触发再均衡。
7.2、缺陷
7.3、如何避免再均衡
- session.timout.ms:控制⼼跳超时时间,推荐设置为6s;
- heartbeat.interval.ms:控制⼼跳发送频率,频率越高越不容易误判,但也会消耗更多资源,推荐设置为2s;
- max.poll.interval.ms:控制poll的间隔,消费者poll数据后,需要⼀些处理,再进⾏拉取。如果两次拉取时间间隔超过这个参数设置的值,那么消费者就会被踢出消费者组。推荐为消费者处理消息最长耗时 + 1分钟。
7.4、如何进行组内分区分配
有三种分配策略:RangeAssignor和RoundRobinAssignor以及StickyAssignor。
7.5、谁来执行再均衡和消费组管理
kafka里有一个角色,叫做Group Coordinator,用于执行消费组的管理。
Group Coordinator——每个消费组分配一个消费组协调器⽤于组管理和位移管理。当消费组的第一个消费者启动的时候,它会去和Kafka Broker确定谁是它们组的组协调器。之后该消费组内所有消费者和该组协调器协调通信。
8、消费者拦截器
作用
- 消费者在拉取了分区消息后,会先通过反序列化对key和value进行处理;
- 然后可通过设置消费者拦截器对消息进行处理,允许更改消费者接收到的消息,或者做一些监控、日志处理;
- 应用程序处理消费者拉取的分区消息;
自定义消费者拦截器
ConsumerInterceptor方法抛出的异常会被捕获、记录,但是不会向下传播。如果用户配置了错误的key或value类型参数,消费者不会抛出异常,而仅仅是记录下来。
自定义消费者拦截器需要实现org.apache.kafka.clients.consumer.ConsumerInterceptor<K, V> 接口,并实现其中的configure()、onConsume()、onCommit()、close()方法,其中:
- onConsume():该方法在poll方法返回之前调用,调用结束后poll方法就返回消息了。可通过该方法修改消费者消息,返回新的消息。
- onCommit():当消费者提交偏移量时,调用该方法。
- close():用于关闭该拦截器用到的资源,如打开的文件、连接的数据库等。
- configure():用于获取消费者的参数配置。
public class MyInterceptor implements ConsumerInterceptor<String, String> {
@Override
public ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> records) {
// poll方法返回结果之前最后要调用的方法
System.out.println("MyInterceptor -- 开始");
// 消息不做处理,直接返回
return records;
}
@Override
public void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets) {
// 消费者提交偏移量的时候,经过该方法
System.out.println("MyInterceptor -- 结束");
}
@Override
public void close() {
// 用于关闭该拦截器用到的资源,如打开的文件,连接的数据库等
}
@Override
public void configure(Map<String, ?> configs) {
// 用于获取消费者的设置参数
configs.forEach((k, v) -> {
System.out.println(k + "\t" + v);
});
}
}以上内容为个人学习理解,如有问题,欢迎在评论区指出。文章来源:https://www.toymoban.com/news/detail-705694.html
部分内容截取自网络,如有侵权,联系作者删除。文章来源地址https://www.toymoban.com/news/detail-705694.html
到了这里,关于kafka学习-消费者的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!