问题描述
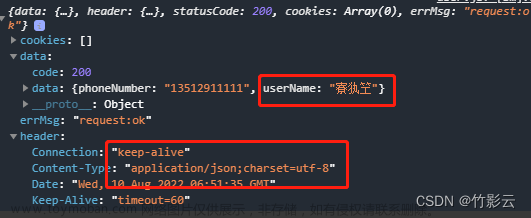
- 情况1:FineBI导入表名中文乱码,字段内容正常
- 情况2:FineBI导入表字段中文乱码,表名内容正常
情况一的解决
- 使用navcat等工具连接node1 mysql数据库,执行下列代码,修改相关字符集格式
- 执行的时机准备数据表阶段和清洗数据阶段都可,需在完成需求生成结果表之前
-- 在Hive的MySQL元数据库中执行
use hive;
-- 1.修改字段注释字符集
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
-- 2.修改表注释字符集
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
-- 3.修改分区表参数,以支持分区键能够用中文表示
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
-- 4.修改索引注解
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
情况二的解决
- 如果出现字段中文乱码,但是通过dataGrip等工具查看表数据中文正常显示,那么就是FineBI连接hive时设置编码utf-8导致出现的问题!
-
设置连接信息编码为自动即可

ETL数据清洗知识
- ETL:
- E,Extract,抽取
- T,Transform,转换
- L,Load,加载
- 从A抽取数据(E),进行数据转换过滤(T),将结果加载到B(L),就是ETL
- 针对大数据中的TEL数据清洗,可以利用分布式计算框架、并行处理、数据采样、数据质量检查等方法,确保数据的质量和准确性。为了满足实时需求,还可以使用流式处理框架。重要的是根据具体的需求和数据特点选择合适的方法和技术。
社交案例参考代码
-- 创建数据库
create database db_msg;
-- 选择数据库
use db_msg;
-- 如果表已存在就删除
drop table if exists db_msg.tb_msg_source ;
-- 建表
create table db_msg.tb_msg_source(
msg_time string comment "消息发送时间",
sender_name string comment "发送人昵称",
sender_account string comment "发送人账号",
sender_sex string comment "发送人性别",
sender_ip string comment "发送人ip地址",
sender_os string comment "发送人操作系统",
sender_phonetype string comment "发送人手机型号",
sender_network string comment "发送人网络类型",
sender_gps string comment "发送人的GPS定位",
receiver_name string comment "接收人昵称",
receiver_ip string comment "接收人IP",
receiver_account string comment "接收人账号",
receiver_os string comment "接收人操作系统",
receiver_phonetype string comment "接收人手机型号",
receiver_network string comment "接收人网络类型",
receiver_gps string comment "接收人的GPS定位",
receiver_sex string comment "接收人性别",
msg_type string comment "消息类型",
distance string comment "双方距离",
message string comment "消息内容"
);
-- 上传数据到HDFS(Linux命令)
--hadoop fs -mkdir -p /chatdemo/data
--hadoop fs -put chat_data-30W.csv /chatdemo/data/
-- 加载数据到表中,基于HDFS加载
load data inpath '/chatdemo/data/chat_data-30W.csv' into table tb_msg_source;
-- 验证数据加载
select * from tb_msg_source tablesample(100 rows);
-- 验证一下表的数量
select count(*) from tb_msg_source;
--问题1:当前数据中,有一些数据的字段为空,不是合法数据
select *
from tb_msg_source
where length(sender_gps)=0;
--问题2∶需求中,需要统计每天、每个小时的消息量,但是数据中没有天和小时字段,只有整体时间字段,不好处理
select msg_time from tb_msg_source limit 10;
--问题3:需求中,需要对经度和维度构建地区的可视化地图,但是数据中GPS经纬度为一个字段,不好处理
select sender_gps from tb_msg_source limit 10;
--需求
--需求1:对字段为空的不合法数据进行过滤 where
--需求2:通过时间字段构建天和小时字段 date hour
--需求3:从GPS的经纬度中提取经度和纬度 split()
--需求4:将ETL以后的结果保存在一张新的Hive表中
drop table if exists db_msg.tb_msg_etl;
--ETL清洗转换(Extract 抽取, Transform 转换,Load 加载)
create table db_msg.tb_msg_etl(
msg_time string comment "消息发送时间",
sender_name string comment "发送人昵称",
sender_account string comment "发送人账号",
sender_sex string comment "发送人性别",
sender_ip string comment "发送人ip地址",
sender_os string comment "发送人操作系统",
sender_phonetype string comment "发送人手机型号",
sender_network string comment "发送人网络类型",
sender_gps string comment "发送人的GPS定位",
receiver_name string comment "接收人昵称",
receiver_ip string comment "接收人IP",
receiver_account string comment "接收人账号",
receiver_os string comment "接收人操作系统",
receiver_phonetype string comment "接收人手机型号",
receiver_network string comment "接收人网络类型",
receiver_gps string comment "接收人的GPS定位",
receiver_sex string comment "接收人性别",
msg_type string comment "消息类型",
distance string comment "双方距离",
message string comment "消息内容",
msg_day string comment "消息日",
msg_hour string comment "消息小时",
sender_lng double comment "经度",
sender_lat double comment "纬度"
);
INSERT OVERWRITE TABLE db_msg.tb_msg_etl
SELECT
*,
DATE(msg_time) AS msg_day,
HOUR(msg_time) AS msg_hour,
SPLIT(sender_gps, ',')[0] AS sender_lng,
SPLIT(sender_gps, ',')[1] AS sender_lat
FROM db_msg.tb_msg_source
WHERE LENGTH(sender_gps) > 0;
--需求
-- 1.统计今日总消息量
create table if not exists tb_rs_total_msg_cnt
comment '每日消总量' AS
select msg_day,count(*) AS total_msg_cnt
from tb_msg_etl group by msg_day;
-- 2.统计今日每小时消息量、发送和接收用户数
create table if not exists tb_rs_hours_msg_cnt
comment "每小时消息量趋势" AS
select
msg_hour,
count(*) as total_msg_cnt,
count(DISTINCT sender_account) as sender_usr_cnt,
count(DISTINCT receiver_account) as receiver_usr_cnt
from tb_msg_etl group by msg_hour;
-- 3.统计今日各地区发送消息数据量
create table if not exists tb_rs_loc_cnt
comment "今日各地区发送消息总量" AS
select
msg_day,
sender_lng,
sender_lat,
count(*) as total_msg_cnt
from tb_msg_etl
group by msg_day,sender_lng,sender_lat;
-- 4.统计今日发送消息和接收消息的用户数
create table if not exists tb_rs_usr_cnt
comment "今日发送消息和接收消息的用户数" AS
select
msg_day,
count(distinct sender_account) as sender_user_cnt,
count(distinct receiver_account) as receiver_user_cnt
from tb_msg_etl
group by msg_day;
-- 5.统计今日发送消息最多的Top10用户
create table if not exists tb_rs_user_sender_msg_top10
comment "今日发送消息最多的Top10用户" AS
select
sender_name,
count(*) as sender_msg_cnt
from tb_msg_etl
group by sender_name
order by sender_msg_cnt desc
limit 10;
-- 6.统计今日接收消息最多的Top10用户
create table if not exists tb_rs_user_receiver_msg_top10
comment "今日接收消息最多的Top10用户" AS
select
receiver_name,
count(*) as receiver_msg_cnt
from tb_msg_etl
group by receiver_name
order by receiver_msg_cnt desc
limit 10;
-- 7.统计发送人的手机型号分布情况
create table if not exists tb_rs_sender_phone_type
comment '发送人手机型号' as
select
sender_phonetype,
count(*) as cnt
from tb_msg_etl
group by sender_phonetype;
-- 8.统计发送人的设备操作系统分布情况
create table if not exists tb_rs_sender_phone_os
comment '发送人手机操作系统' as
select
sender_os,
count(*) as cnt
from tb_msg_etl
group by sender_os;
结果展示

 文章来源地址https://www.toymoban.com/news/detail-705715.html
文章来源地址https://www.toymoban.com/news/detail-705715.html
文章来源:https://www.toymoban.com/news/detail-705715.html
到了这里,关于关于黑马hive课程案例FineBI中文乱码的解决的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!