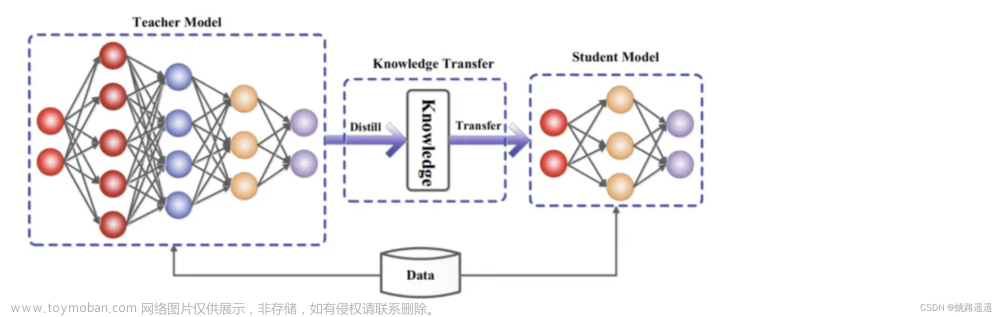
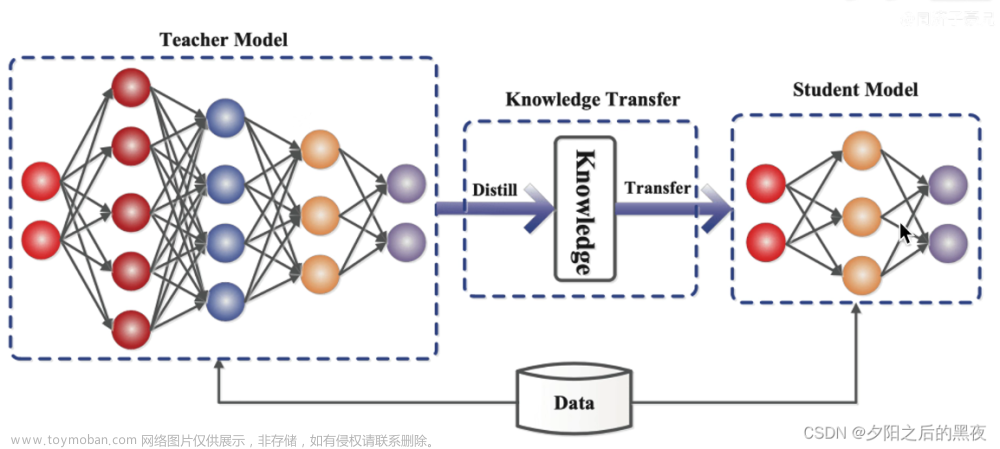
知识蒸馏----教师和学生模型:将已训练完善的模型作为教师模型,通过控制“温度”从模型的输出结果中“蒸馏”出“知识”用于学生模型的训练,并希望轻量级的学生模型能够学到教师模型的“知识”,达到和教师模型相同的表现。

本质上属于迁移学习
优点:
1.节省成本。由于使用现有的已经训练好的模型模型,将其中蕴含的信息用于指导新的训练阶段,避免了重新学习耗费的时间。
2.保护隐私。将模型和知识表示进行分离,从而在训练过程中将教师模型作为“黑盒”处理,可以避免直接暴露敏感数据,达到隐私保护效果.
3.模型简单。将复杂的深层网络模型向浅层的小型网络模型迁移知识。

分类:
离线蒸馏:老师模型传授给学生模型,不参与训练。
在线蒸馏:老师模型没有预训练,准备和学生模型一同进行训练,在一同训练的过程中来指导学生模型进行学习,完成知识蒸馏。文章来源:https://www.toymoban.com/news/detail-705919.html
自蒸馏:老师模型和学生模型是一个模型,也就是一个模型来指导自己进行学习,完成知识蒸馏文章来源地址https://www.toymoban.com/news/detail-705919.html
到了这里,关于知识蒸馏学习的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!