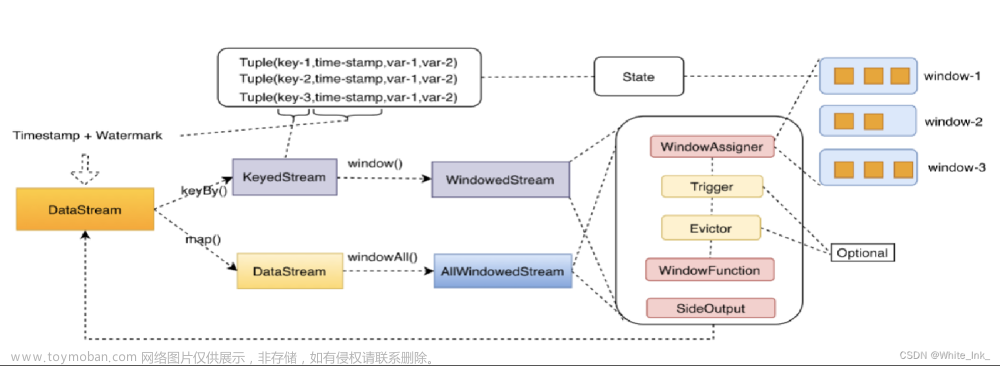
一.countWindow和countWindowall区别
1.countWindow:
如果您使用 countWindow(5),这意味着您将数据流划分成多个大小为 5 的窗口。划分后的窗口如下:
- 窗口 1:
[1, 2, 3, 4, 5] - 窗口 2:
[6, 7, 8, 9, 10]
当每个窗口中的元素数量达到 5 时,将触发计算。这意味着窗口 1 中的计算会在处理 5 个元素后触发,窗口 2 中的计算会在处理 10 个元素后触发。
2.countWindowAll:
假设您有一个数据流,其中的数据元素逐个增加:[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]。
现在,我们使用 countWindowAll(5) 来观察这个数据流。
-
初始状态:当数据流中的元素数量达到 5 时,即
[1, 2, 3, 4, 5],将会触发第一次计算。 -
后续状态:现在,数据流中的元素数量已经超过 5 了,但由于
countWindowAll会持续监视整个数据流,所以并不会立即触发第二次计算。数据流继续增加。 -
再次触发计算:当数据流中的元素数量达到 10,即
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10],将会触发第二次计算。这是因为虽然数据流中的元素已经超过 5,但是countWindowAll是持续监视整个数据流的元素数量,只有在数据流中的元素数量从不小于 5 变为不小于 10 时,才会再次触发计算。
综上所述,countWindowAll 会持续监视整个数据流的元素数量,只有当元素数量达到阈值并且之前没有达到过,才会触发计算。这使得 countWindowAll 不仅触发一次计算,而是每次在元素数量达到阈值时都会触发计算。
二.countWindow和countWindowall代码验证
1.countWindow
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class WordCountWithCountWindow {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> text = env.socketTextStream("localhost", 9999);
DataStream<Tuple2<String, Integer>> counts = text
.flatMap(new Tokenizer())
.keyBy(0)
.countWindow(5) // 使用 countWindow
.sum(1);
counts.print();
env.execute("WordCountWithCountWindow");
}
public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
String[] words = value.toLowerCase().split("\\W+");
for (String word : words) {
if (word.length() > 0) {
out.collect(new Tuple2<>(word, 1));
}
}
}
}
}
2.countWindowAll
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class WordCountWithCountWindowAll {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> text = env.socketTextStream("localhost", 9999);
DataStream<Tuple2<String, Integer>> counts = text
.flatMap(new Tokenizer())
.countWindowAll(5) // 使用 countWindowAll
.sum(1);
counts.print();
env.execute("WordCountWithCountWindowAll");
}
public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
String[] words = value.toLowerCase().split("\\W+");
for (String word : words) {
if (word.length() > 0) {
out.collect(new Tuple2<>(word, 1));
}
}
}
}
}
三.countWindow和countWindowall两种方式对比
countWindow:
应用场景:
- 滑动窗口聚合:适用于需要对连续的数据元素进行滑动窗口聚合计算的场景,例如每处理固定数量的数据点就进行一次平均值、总和等计算。
- 数据流分段处理:适用于将数据流划分为连续的段进行处理的场景,例如每处理一段数据就执行某种操作。
- 实时流式处理:在实时数据流处理中,将数据分批次处理,以平稳地处理不断流入的数据。
优势:
- 更精细的控制:可以将数据流划分为多个小窗口,对每个小窗口进行独立的计算,具有更精细的控制。
- 灵活性:窗口大小可调整,适应不同大小的数据处理需求。
- 内存管理:每个小窗口的数据量较小,可能更适合内存管理。
劣势:文章来源:https://www.toymoban.com/news/detail-706005.html
- 窗口间隔:可能需要更多的逻辑来管理不同窗口之间的数据和计算。
countWindowAll:
应用场景:
- 批量数据处理:适用于需要将整个数据集视为一个窗口进行处理的场景,通常用于有限的数据集或一次性处理。
- 实时报警与监控:适用于监控数据流,一旦累计的数据达到阈值,即触发报警或监控。
- 小数据集处理:对于较小的数据集,将其作为一个整体进行处理可能更合适。
优势:
- 简单性:将整个数据流作为一个窗口,简化了窗口管理和数据处理逻辑。
- 全局计算:可以在全局范围内进行计算,不需要关注窗口间隔。
劣势:
- 内存需求:对于大规模的数据流,可能需要更多内存来处理整个数据流。
- 处理延迟:需要等待整个数据流中的数据达到一定数量才会触发计算,可能会引入一定的处理延迟。
综上所述,选择使用 countWindow 还是 countWindowAll 取决于您的数据处理需求、数据流的规模以及对计算控制和延迟的关注程度。在实际应用中,您可能会根据具体情况选择合适的窗口类型。文章来源地址https://www.toymoban.com/news/detail-706005.html
到了这里,关于Flink-Window详细讲解-countWindow的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!