一、Linux环境准备
1.1 虚拟机安装
相关软件下载准备:(推荐)
- 虚拟机运行环境:VMware 16.1.1
- 映像文件:CentOS-7-x86_64-DVD-1810.iso
- 远程登录工具:Xshell-7.0.0090.exe
- Xftp传输工具:Xftp-7.0.0111p.exe
首先掌握VMware的下载与安装,有linux学习基础的同学可以略看。
参考链接:https://mp.weixin.qq.com/s/CUiauodcjCFPIXEFEx8fOw
【软件名称】: VMware 16.1.1
【软件大小】:568MB
【系统要求】:win7/win8\win10/win11或以上
【下载链接】:https://pan.baidu.com/s/1bY1swCAxWjTIpOROlXaqnQ?pwd=1234
【提取码】:1234
1.对下载的压缩包进行解压缩
2.打开解压后的压缩包,进行如下步骤
3.下一步
4.接受许可,下一步
5.更改软件安装目录(自己在某个盘新建一个干净的文件夹),下一步
6. 取消红框内的勾选框,点下一步
7. 点下一步
8.点击安装
9.输入许可证激活
输入以下三个中任意一个即可,输入后,点完成即可。
ZF3R0-FHED2-M80TY-8QYGC-NPKYF
YF390-0HF8P-M81RQ-2DXQE-M2UT6
ZF71R-DMX85-08DQY-8YMNC-PPHV8
10.安装成功,桌面显示图标。
11.打开WMware16虚拟机,右键以管理员身份运行。
12.首页创建新的虚拟机,接下来按照截图步骤创建虚拟机。
13
14 关于硬件兼容性,根据安装时系统自动选择的版本项,不用变
15
16
17.
18.
19
20
21
22
23
24
25
26
27,找到Centos的iso镜像文件保存位置,并选择它。
28
29
30
31
32
33
34
35
36
37.设置root用户的密码为123456;设置普通用户的用户名(~自定义)和密码(123456)
38
39
mkdir -p /export/data
mkdir -p /export/servers
mkdir -p /export/software

1.2 Linux系统网络配置
详细步骤如下:
- 虚拟机首页菜单栏,找到【编辑】右键,选择【虚拟网络编辑器】

2.修改子网IP
3.选择【NAT设置】
4.将网关IP改为:192.168.121.2
5. DHCP设置
ip信息修改为红色框内的内容
之后点击【应用】,【确定】
6.查看IP配置文件并修改ip配置信息
vim /etc/sysconfig/network-scripts/ifcfg-ens33
修改配置文件时:
• 将DHCP自动分配模式改为static
• 添加ip地址,网络类型、网络范围和网络位(即ip地址前三部分)必须和虚拟网络编辑器中相同,主机位(最后一部分)自定义,这里hadoop01用的IP为 192.168.121.134。
• 添加网关和域名解析器,和虚拟网络编辑器中相同。
执行过程:(提醒,网络配置信息不能出错,出错了后面网络会不通)

7.配置好后,输入如下命令,重启网络。
service network restart

8. 重启后,请再次查看网络ip,确定ip地址修改成功,之后测试是否能够上网。
终端输入命令:
ipconfig
出现如下信息,表示网络配置成功。
Ping百度看是否能ping通。
输入命令:
ping www.baidu.com

9. 接下来修改主机名和hosts映射文件
&查看主机名
输入如下命令:
hostname

显示出当前虚拟机的主机名为:hadoop01
&修改hadoop01的hosts映射文件
注:后续在hadoop搭建阶段虚拟机比较多,每次访问类似192.168.121.134的ip地址比较麻烦,通常会采用主机名的方式进行配置。
输入如下命令:
vi /etc/hosts
添加下面三条:(其实就是三台虚拟机IP及各自对应的主机名)
192.168.121.134 hadoop01
192.168.121.135 hadoop02
192.168.121.136 hadoop03

&修改Windows的hosts文件
提醒!!!Windows的hosts文件一般保存在C:\Windows\System32\drivers\etc下,打开hosts文件添加如下内容并保存。
因为C盘里面的文件,修改一些文件需要权限比较高,如果无法保存成功,建议怎么做呢?首先,可以复制hosts文件到桌面,在桌面打开hosts文件修改并保存,之后覆盖原文件。
将hosts文件复制到桌面一份。
添加如下三行映射内容
192.168.121.134 hadoop01
192.168.121.135 hadoop02
192.168.121.136 hadoop03

将桌面保存后的hosts文件复制到此路径下,C:\Windows\System32\drivers\etc,覆盖掉原来的hosts文件。
.。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
接下来打开Windows的命令提示符窗口,进行测试,直接ping主机名,如果成功,说明修改完成。如下图:
10. 关闭防火墙,防止防火墙开机自启动
hadoop01虚拟机下分别执行下面两条命令:
systemctl stop firewalld
systemctl disable firewalld.service
11. 创建一个普通用户,方便后期登录普通用户加sudo命令执行root权限
• 执行下面命令创建普通用户并修改其密码,用户名为user,密码为123456
useradd user
passwd user
• 执行如下命令,修改相应的配置文件,提高user用户权限,使其具有root对等权限
vim /etc/sudoers
添加如下内容:(缩进根据文本内容自主调整)
user ALL=(ALL) NOPASSWD:ALL
注意!!!!user这一行必须放在%wheel这一行下面
• 创建在/opt下创建两个文件夹并修改所属主和所属组
】首先创建module和software文件夹
mkdir /opt/module
mkdir /opt/software
】其次修改新创建的文件夹所属主和所属组为user用户
chown user:user /opt/module
chown user:user /opt/software
】最后输入命令ll:查看module和software的所属主和所属组
ll

12.安装epel-release,相当于是一个软件仓库
yum install -y epel-release
13.重启虚拟机
reboot
1.3 虚拟机克隆
克隆过程如下:






hadoop02克隆完成;
接下来克隆hadoop03。(和克隆hadoop02一样的操作)


注意!!!hadoop03文件夹就是前面提前在E盘建好的。选择此路径即可。


到此,三台虚拟机克隆完成;
有时候为了方便管理,我们进行如下步骤;

将三台虚拟机拖进新建的文件夹中,并排好顺序即可。
到此虚拟机克隆完成。------------------------------------------------------------------------------
hadoop02和hadoop03克隆完成以后需要参照虚拟机hadoop01的执行过程,配置一些信息。
首先,对于hadoop02,hadoop03:修改其ip配置文件:
vim /etc/sysconfig/network-scripts/ifcfg-ens33
hadoop02主机
hadoop03主机
其次****修改主机名为hadoop02,【因为】hadoop02是克隆来的,所以对与hadoop02来说,主机名现在依然是hadoop01,所以需要修改为hadoop02。hadoop03也同样如此。
vi etc/hostname
hadoop02主机
hadoop03主机
再次,由于hosts映射文件已经在hadoop01中修改过,即IP与主机名的映射关系,所以在hadoop02,hadoop03这里就不用修改了。
最后,查看网络IP,确定各个主机IP对应是否正确,并测试能否连接外网
- hadoop01的IP为192.168.121.134
- hadoop02的IP为192.168.121.135
- hadoop03的IP为192.168.121.136
注意:一定确保各个主机IP配置正确,且能正常连网。
1.4 SSH服务配置
1. 查看虚拟机是否已经安装了ssh服务。
ps -e | grep sshd

已经安装有了,因此不需要额外的操作就可以做一个远程连接。
如果没有安装,则执行如下命令:
yum install openssh-server
- 在这里借助一款虚拟机远程连接工具【Xshell】,
版本Xftp-7.0.0134p.exe和Xshell-7.0.0134p.exe的软件安装过程,这里不再详述。
远程连接过程如下:

3. 接下来:
输入相应的用户名:root
输入相应的密码:123456
三台虚拟机连接后的效果:
利用xftp,方面Window和虚拟机之间传输文件。
1.新建连接。
2. 输入【名称】,【主机名】
确定后,输入相应的用户名root和密码123456
三台虚拟机连接完成后如下:
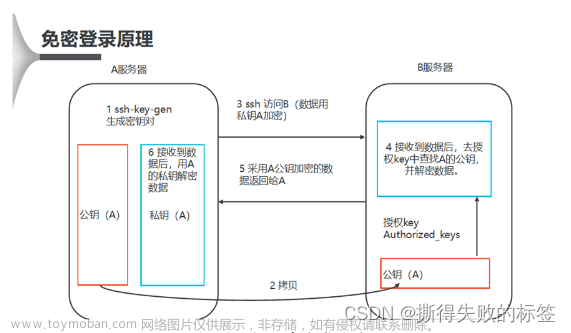
3. 三台主机之间的免密登录。
第一台:hadoop01:
输入命令生成密钥对:
ssh-keygen -t rsa

输入以下命令,查看生成的公私钥对:
cd .ssh
ls

同样在hadoop02、hadoop03执行上述同样的操作生成密钥对。
确保三台虚拟机中,都生成了各种的公私钥对。
接下来:
将三台虚拟机的公钥拷贝到一台机器上
- 对于hadoop01机器:执行命令:
ssh-copy-id hadoop01 - 对于hadoop02机器:执行命令:
ssh-copy-id hadoop01 - 对于hadoop03机器:执行命令:
ssh-copy-id hadoop01
在hadoop01虚拟机中,定位到目录.ssh下面,输入ls,可以查看到出现一个文件authorized_keys,此文件保存的就是三台机器的公钥
再接下来
将此文件authorized_keys发送给其它机器。
scp /root/.ssh/authorized_keys hadoop02:/root/.ssh
scp /root/.ssh/authorized_keys hadoop03:/root/.ssh

最后试试免密登录是否成功。
即利用ssh+【主机名】,无需输入密码,即可实现对应主机登录,方便后续操作。
二、JDK的安装配置
安装JDK。
1. 利用xftp软件,将下载好的压缩包上传到虚拟机中。,直接选中【目标文件】左右拖拽即可实现文件快速传输。因此将Windows下保存的jdk的压缩包拖入到右侧的虚拟机下,路径为:/export/software(提前在虚拟机中建好的文件路径)
2. 先定位到/export/software/目录下,然后ll查看压缩包是否存在,之后利用下面的tar命令进行解压缩
cd /export/software/
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /export/servers/

3. 查看解压缩后的jdk文件夹,并利用mv命令对文件夹进行重命名。
cd /export/servers/
ls
mv jdk1.8.0_161/ jdk

4. 配置JDK环境变量
vim /etc/profile
添加如下内容:
#JAVA_HOME
export JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin

5.编辑保存好后,重启使配置文件生效。
source /etc/profile
6. jdk的环境验证
java -version

三、Hadoop安装及配置
- 将hadoop2.7.4的安装包拖入到hadoop01的路径/export/software下。

2.在xshell下的hadoop01节点,定位到此目录/export/software
cd /export/software
之后解压hadoop压缩包。解压后的目标路径为/export/servers
tar -zxvf hadoop-2.7.4.tar.gz -C /export/servers/

解压成功后,进入到/export/servers目录下
cd /export/servers
ls
#查看解压后的hadoop文件。

3. 配置Hadoop系统环境变量
vim /etc/profile
添加如下内容:
export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH

#输入如下命令,使配置文件生效
source /etc/profile
#查看hadoop版本
hadoop version

4. 接下俩可以随意查看一下hadoop压缩包里面都有哪一些文件
查看一些重要的配置文件,如下:
接下来hadoop集群的搭建需要用到这些文件。
5. 配置Hadoop集群主节点。
(1).修改hadoop-env.sh文件。
命令:
vim hadoop-env.sh
添加如下内容:
export JAVA_HOME=/export/servers/jdk

(2).修改core-site.xml文件
命令:
vim core-site.xml
添加内容如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.7.4/tmp</value>
</property>
</configuration>

(3). 修改hdfs-site.xml文件
命令:
vim hdfs-site.xml
添加如下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:50090</value>
</property>
</configuration>

(4). 修改mapred-site.xml
#这里我们首先需要拷贝下mapred-site.xml.template文件,命名为mapred-site.xml
命令如下:
cp mapred-site.xml.template mapred-site.xml
接下来编辑此文件
命令:
vim mapred-site.xml
添加的内容如下:(指定MapReduce运行时的框架,这里指定在Yarn上)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>

(5).修改yarn-site.xml
#Yarn 分布式资源调度系统。
命令:
vim yarn-site.xml
添加的内容如下:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>

(6)修改slaves文件,打开该配置文件,先删除里面的内容(默认是localhost)。
命令:
vim slaves
然后添加如下内容:
hadoop01
hadoop02
hadoop03
到此一些集群主节点hadoop01中一些配置配置文件配置完成。
接下来将配置好的文件分发到另外两个节点下hadoop02和hadoop03。
#执行如下四条命令进行分发
> scp /etc/profile hadoop02:/etc/profile
> scp /etc/profile hadoop03:/etc/profile
> scp -r /export/ hadoop02:/
> scp -r /export/ hadoop03:/
执行结束后:还需要在hadoop02和hadoop03上执行命令:
source /etc/profile
到此整个hadoop集群的配置就结束了。
还没结束,,,
6.格式化文件系统(在主节点上执行。即hadoop01这台虚拟机上执行)
hdfs namenode -format
注意!!!格式化文件系统这个操作只能在第一次启动hdfs集群时来操作,后面不能再进行格式化)
成功被格式化:
7. 启动和关闭Hadoop集群
包含HDFS集群和YARN两个集群框架
启动有两种方式:
- 1 单节点逐个启动
- 2. 使用脚本一键启动
这里使用第二种方式,第一种方式自主学习。
使用脚本一键启动文章来源:https://www.toymoban.com/news/detail-706128.html
start-dfs.sh或stop-dfs.sh #启动或关闭所有HDFS服务进程
start-yarn.sh或stop-yarn.sh #启动或关闭所有YARN服务进程
对于hadoop01:
对于hadoop02:

对于hadoop03:
注:jps命令是查看开启的进程。
确保:
hadoop01有5个,hadoop02有4个,hadoop03有3个
8.最后,查看HDFS和YARN集群状态
在浏览器访问hadoop01:50070或者192.168.121.134:50070(格式为:主机名或IP地址+端口号)查看HDFS集群状态
浏览器搜索hadoop01:8088或者192.168.121.134:8088(格式为:主机名或IP地址+端口号)可查看YARN集群管理页面.
至此,hadoop集群搭建成功!!!文章来源地址https://www.toymoban.com/news/detail-706128.html
到了这里,关于Hadoop集群部署-(完全分布式模式,hadoop-2.7.4)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!