深度学习推荐系统(五)Deep&Crossing模型及其在Criteo数据集上的应用
在2016年, 随着微软的Deep Crossing, 谷歌的Wide&Deep以及FNN、PNN等一大批优秀的深度学习模型被提出, 推荐系统全面进入了深度学习时代, 时至今日, 依然是主流。 推荐模型主要有下面两个进展:
-
与传统的机器学习模型相比, 深度学习模型的表达能力更强, 能够挖掘更多数据中隐藏的模式
-
深度学习模型结构非常灵活, 能够根据业务场景和数据特点, 灵活调整模型结构, 使模型与应用场景完美契合
深度学习推荐模型,以多层感知机(MLP)为核心, 通过改变神经网络结构进行演化。
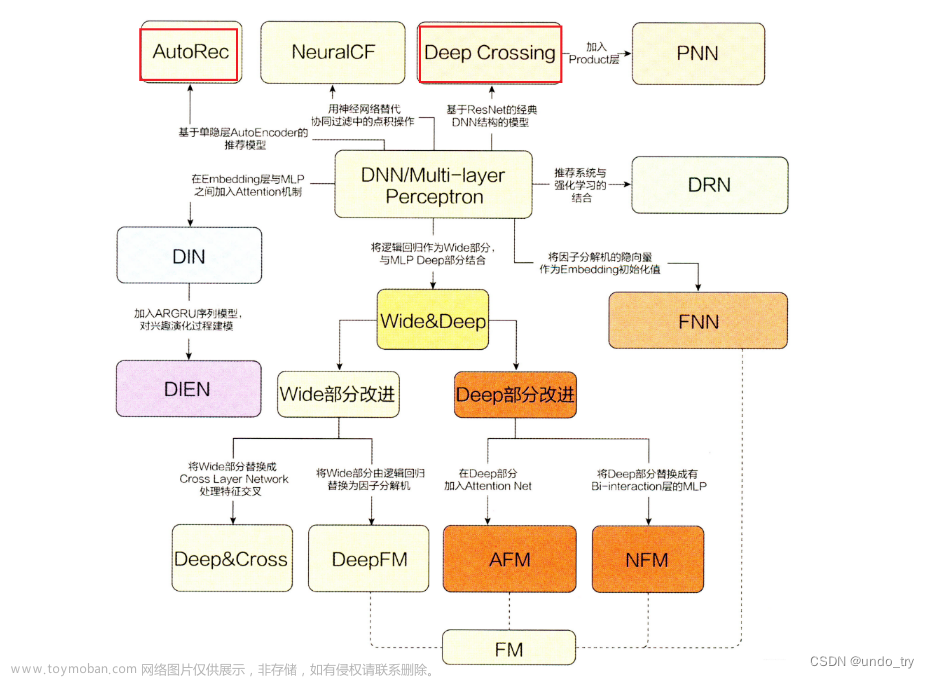
1 Deep&Crossing模型原理
1.1 Deep&Crossing模型提出的背景
-
Wide&Deep 模型的提出不仅综合了
记忆能力和泛化能力,而且开启了不同网络结构融合的新思路。 -
在 Wide&Deep 模型之后,有越来越多的工作集中于分别改进Wide&Deep模型的 Wide部分或是 Deep 部分。
-
典型的工作是2017年由斯坦福大学和谷歌的研究人员提出的 Deep&Cross模型(简称DCN)。
-
Deep&Cross 模型的主要思路是使用 Cross 网络替代原来的 Wide 部分。由于 Deep 部分的设计思路并没有本质的改变,最主要的创新点是Cross 部分的设计思路。
1.2 Deep&Crossing的模型结构
DCN模型的结构非常简洁,从下往上依次为:Embedding和Stacking层、Cross网络层与Deep网络层并列、输出合并层,得到最终的预测结果。
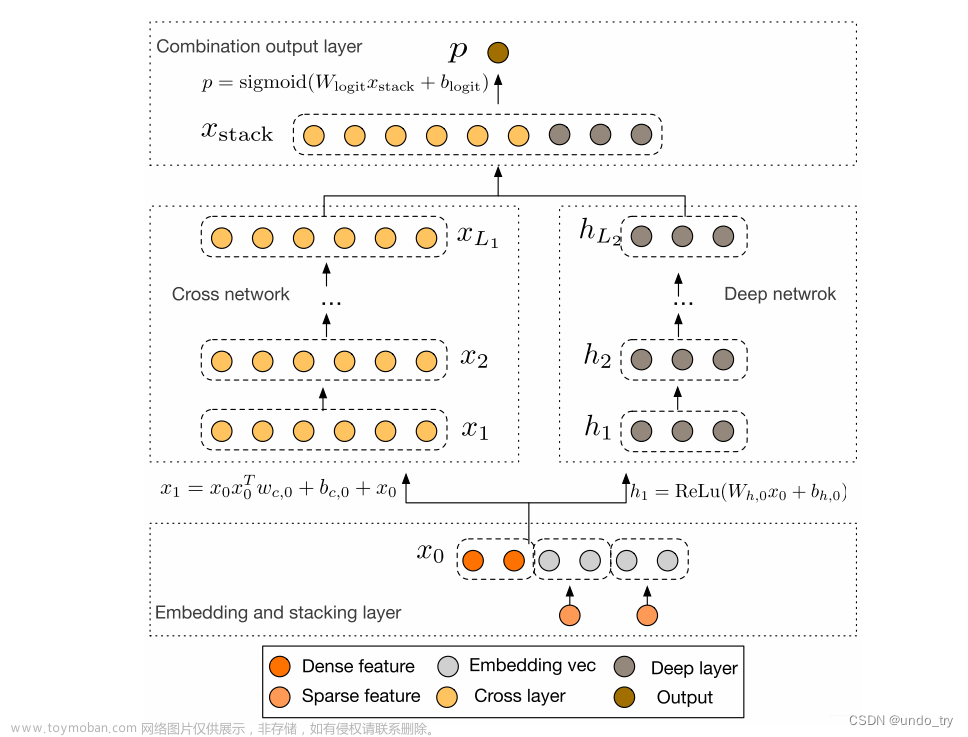
1.2.1 Embedding and stacking layer
Embedding层作用依然是把稀疏离散的类别型特征变成低维密集型。
然后需要将所有的密集型特征(数值型特征)与通过embedding转换后的特征进行联合(Stacking)。

1.2.2 Cross NetWork模型

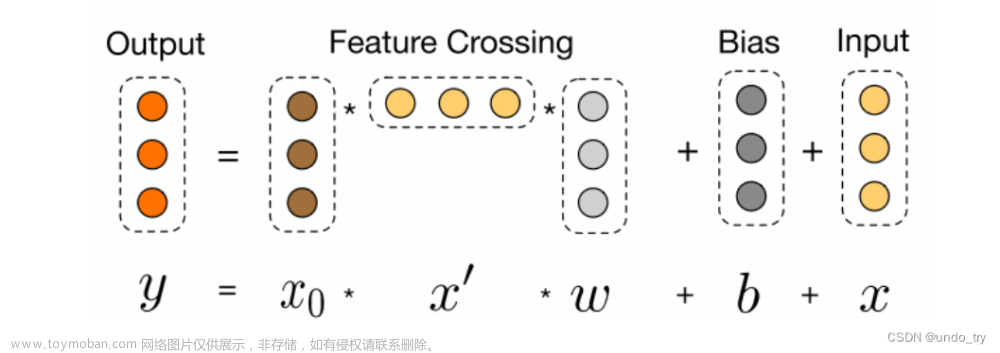
举例说明
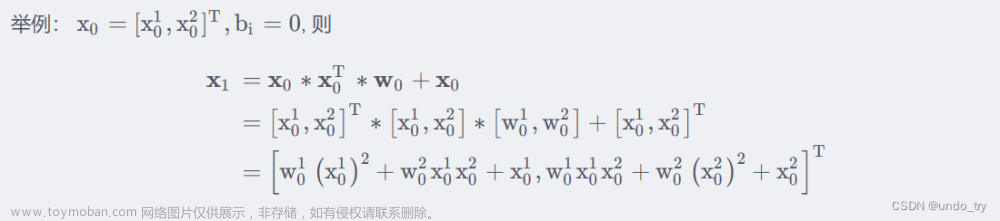
可以看到
-
x1中包含了所有的x0的1,2阶特征的交互。
第l层特征对应的最高的叉乘阶数为l+1 -
Cross网络的参数是共享的, 每一层的这个权重特征之间共享, 这个可以使得模型泛化到看不见的特征交互作用, 并且对噪声更具有鲁棒性。
-
Deep Network及组合层比较简单,不再赘述。
1.3 Deep&Crossing模型代码复现
import torch.nn as nn
import torch.nn.functional as F
import torch
class CrossNetwork(nn.Module):
"""
Cross Network
"""
def __init__(self, layer_num, input_dim):
super(CrossNetwork, self).__init__()
self.layer_num = layer_num
# 定义网络层的参数
self.cross_weights = nn.ParameterList([
nn.Parameter(torch.rand(input_dim, 1))
for i in range(self.layer_num)
])
self.cross_bias = nn.ParameterList([
nn.Parameter(torch.rand(input_dim, 1))
for i in range(self.layer_num)
])
def forward(self, x):
# x是(batchsize, dim)的形状, 先扩展一个维度到(batchsize, dim, 1)
x_0 = torch.unsqueeze(x, dim=2)
x = x_0.clone()
xT = x_0.clone().permute((0, 2, 1)) # (batchsize, 1, dim)
for i in range(self.layer_num):
x = torch.matmul(torch.bmm(x_0, xT), self.cross_weights[i]) + self.cross_bias[i] + x # (batchsize, dim, 1)
xT = x.clone().permute((0, 2, 1)) # (batchsize, 1, dim)
x = x.squeeze(2) # (batchsize, dim)
return x
class Dnn(nn.Module):
"""
Dnn part
"""
def __init__(self, hidden_units, dropout=0.):
"""
hidden_units: 列表, 每个元素表示每一层的神经单元个数, 比如[256, 128, 64], 两层网络, 第一层神经单元128, 第二层64, 第一个维度是输入维度
dropout: 失活率
"""
super(Dnn, self).__init__()
self.dnn_network = nn.ModuleList(
[nn.Linear(layer[0], layer[1]) for layer in list(zip(hidden_units[:-1], hidden_units[1:]))])
self.dropout = nn.Dropout(p=dropout)
def forward(self, x):
for linear in self.dnn_network:
x = linear(x)
x = F.relu(x)
x = self.dropout(x)
return x
class DCN(nn.Module):
def __init__(self, feature_info, hidden_units, layer_num, embed_dim=8,dnn_dropout=0.):
"""
feature_info: 特征信息(数值特征, 类别特征, 类别特征embedding映射)
hidden_units: 列表, 隐藏单元的个数(多层残差那里的)
layer_num: cross network的层数
embed_dim: embedding维度
dnn_dropout: Dropout层的失活比例
"""
super(DCN, self).__init__()
self.dense_features, self.sparse_features, self.sparse_features_map = feature_info
# embedding层, 这里需要一个列表的形式, 因为每个类别特征都需要embedding
self.embed_layers = nn.ModuleDict(
{
'embed_' + str(key): nn.Embedding(num_embeddings=val, embedding_dim=embed_dim)
for key, val in self.sparse_features_map.items()
}
)
# 统计embedding_dim的总维度
# 一个离散型(类别型)变量 通过embedding层变为10纬
embed_dim_sum = sum([embed_dim] * len(self.sparse_features))
# 总维度 = 数值型特征的纬度 + 离散型变量经过embedding后的纬度
dim_sum = len(self.dense_features) + embed_dim_sum
hidden_units.insert(0, dim_sum)
# 1、cross Network
# layer_num是交叉网络的层数, hidden_units[0]表示输入的整体维度大小
self.cross_network = CrossNetwork(layer_num, hidden_units[0])
# 2、Deep Network
self.dnn_network = Dnn(hidden_units,dnn_dropout)
# 最后一层线性层,输入纬度是(cross Network输出纬度 + Deep Network输出纬度)
self.final_linear = nn.Linear(hidden_units[-1] + hidden_units[0], 1)
def forward(self, x):
# 1、先把输入向量x分成两部分处理、因为数值型和类别型的处理方式不一样
dense_input, sparse_inputs = x[:, :len(self.dense_features)], x[:, len(self.dense_features):]
# 2、转换为long形
sparse_inputs = sparse_inputs.long()
# 2、不同的类别特征分别embedding
sparse_embeds = [
self.embed_layers['embed_' + key](sparse_inputs[:, i]) for key, i in
zip(self.sparse_features_map.keys(), range(sparse_inputs.shape[1]))
]
# 3、把类别型特征进行拼接,即emdedding后,由3行转换为1行
sparse_embeds = torch.cat(sparse_embeds, axis=-1)
# 4、数值型和类别型特征进行拼接
x = torch.cat([sparse_embeds, dense_input], axis=-1)
# cross Network
cross_out = self.cross_network(x)
# Deep Network
deep_out = self.dnn_network(x)
# Concatenate
total_x = torch.cat([cross_out, deep_out], axis=-1)
# out
outputs = F.sigmoid(self.final_linear(total_x))
return outputs
if __name__ == '__main__':
x = torch.rand(size=(1, 5), dtype=torch.float32)
feature_info = [
['I1', 'I2'], # 连续性特征
['C1', 'C2', 'C3'], # 离散型特征
{
'C1': 20,
'C2': 20,
'C3': 20
}
]
# 建立模型
hidden_units = [128, 64, 32]
net = DCN(feature_info, hidden_units,layer_num=2)
print(net)
print(net(x))
DCN(
(embed_layers): ModuleDict(
(embed_C1): Embedding(20, 8)
(embed_C2): Embedding(20, 8)
(embed_C3): Embedding(20, 8)
)
(cross_network): CrossNetwork(
(cross_weights): ParameterList(
(0): Parameter containing: [torch.FloatTensor of size 26x1]
(1): Parameter containing: [torch.FloatTensor of size 26x1]
)
(cross_bias): ParameterList(
(0): Parameter containing: [torch.FloatTensor of size 26x1]
(1): Parameter containing: [torch.FloatTensor of size 26x1]
)
)
(dnn_network): Dnn(
(dnn_network): ModuleList(
(0): Linear(in_features=26, out_features=128, bias=True)
(1): Linear(in_features=128, out_features=64, bias=True)
(2): Linear(in_features=64, out_features=32, bias=True)
)
(dropout): Dropout(p=0.0, inplace=False)
)
(final_linear): Linear(in_features=58, out_features=1, bias=True)
)
tensor([[0.9349]], grad_fn=<SigmoidBackward0>)
2 Deep&Crossing模型在Criteo数据集的应用
数据的预处理可以参考
深度学习推荐系统(二)Deep Crossing及其在Criteo数据集上的应用_undo_try的博客-CSDN博客文章来源:https://www.toymoban.com/news/detail-706267.html
2.1 准备训练数据
import pandas as pd
import torch
from torch.utils.data import TensorDataset, Dataset, DataLoader
import torch.nn as nn
from sklearn.metrics import auc, roc_auc_score, roc_curve
import warnings
warnings.filterwarnings('ignore')
# 封装为函数
def prepared_data(file_path):
# 读入训练集,验证集和测试集
train_set = pd.read_csv(file_path + 'train_set.csv')
val_set = pd.read_csv(file_path + 'val_set.csv')
test_set = pd.read_csv(file_path + 'test.csv')
# 这里需要把特征分成数值型和离散型
# 因为后面的模型里面离散型的特征需要embedding, 而数值型的特征直接进入了stacking层, 处理方式会不一样
data_df = pd.concat((train_set, val_set, test_set))
# 数值型特征直接放入stacking层
dense_features = ['I' + str(i) for i in range(1, 14)]
# 离散型特征需要需要进行embedding处理
sparse_features = ['C' + str(i) for i in range(1, 27)]
# 定义一个稀疏特征的embedding映射, 字典{key: value},
# key表示每个稀疏特征, value表示数据集data_df对应列的不同取值个数, 作为embedding输入维度
sparse_feas_map = {}
for key in sparse_features:
sparse_feas_map[key] = data_df[key].nunique()
feature_info = [dense_features, sparse_features, sparse_feas_map] # 这里把特征信息进行封装, 建立模型的时候作为参数传入
# 把数据构建成数据管道
dl_train_dataset = TensorDataset(
# 特征信息
torch.tensor(train_set.drop(columns='Label').values).float(),
# 标签信息
torch.tensor(train_set['Label'].values).float()
)
dl_val_dataset = TensorDataset(
# 特征信息
torch.tensor(val_set.drop(columns='Label').values).float(),
# 标签信息
torch.tensor(val_set['Label'].values).float()
)
dl_train = DataLoader(dl_train_dataset, shuffle=True, batch_size=16)
dl_vaild = DataLoader(dl_val_dataset, shuffle=True, batch_size=16)
return feature_info,dl_train,dl_vaild,test_set
file_path = './preprocessed_data/'
feature_info,dl_train,dl_vaild,test_set = prepared_data(file_path)
2.2 建立Deep&Crossing模型
from _01_DeepAndCrossing import DCN
# 建立模型
hidden_units = [128, 64, 32]
net = DCN(feature_info, hidden_units,layer_num=len(hidden_units))
# 测试一下模型
for feature, label in iter(dl_train):
out = net(feature)
print(feature.shape)
print(out.shape)
print(out)
break
2.3 模型的训练
from AnimatorClass import Animator
from TimerClass import Timer
# 模型的相关设置
def metric_func(y_pred, y_true):
pred = y_pred.data
y = y_true.data
return roc_auc_score(y, pred)
def try_gpu(i=0):
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
def train_ch(net, dl_train, dl_vaild, num_epochs, lr, device):
"""⽤GPU训练模型"""
print('training on', device)
net.to(device)
# 二值交叉熵损失
loss_func = nn.BCELoss()
optimizer = torch.optim.Adam(params=net.parameters(), lr=lr)
animator = Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train auc', 'val loss', 'val auc']
,figsize=(8.0, 6.0))
timer, num_batches = Timer(), len(dl_train)
log_step_freq = 10
for epoch in range(1, num_epochs + 1):
# 训练阶段
net.train()
loss_sum = 0.0
metric_sum = 0.0
for step, (features, labels) in enumerate(dl_train, 1):
timer.start()
# 梯度清零
optimizer.zero_grad()
# 正向传播
predictions = net(features)
loss = loss_func(predictions, labels.unsqueeze(1) )
try: # 这里就是如果当前批次里面的y只有一个类别, 跳过去
metric = metric_func(predictions, labels)
except ValueError:
pass
# 反向传播求梯度
loss.backward()
optimizer.step()
timer.stop()
# 打印batch级别日志
loss_sum += loss.item()
metric_sum += metric.item()
if step % log_step_freq == 0:
animator.add(epoch + step / num_batches,(loss_sum/step, metric_sum/step, None, None))
# 验证阶段
net.eval()
val_loss_sum = 0.0
val_metric_sum = 0.0
for val_step, (features, labels) in enumerate(dl_vaild, 1):
with torch.no_grad():
predictions = net(features)
val_loss = loss_func(predictions, labels.unsqueeze(1))
try:
val_metric = metric_func(predictions, labels)
except ValueError:
pass
val_loss_sum += val_loss.item()
val_metric_sum += val_metric.item()
if val_step % log_step_freq == 0:
animator.add(epoch + val_step / num_batches, (None,None,val_loss_sum / val_step , val_metric_sum / val_step))
print(f'final: loss {loss_sum/len(dl_train):.3f}, auc {metric_sum/len(dl_train):.3f},'
f' val loss {val_loss_sum/len(dl_vaild):.3f}, val auc {val_metric_sum/len(dl_vaild):.3f}')
print(f'{num_batches * num_epochs / timer.sum():.1f} examples/sec on {str(device)}')
lr, num_epochs = 0.001, 10
train_ch(net, dl_train, dl_vaild, num_epochs, lr, try_gpu())
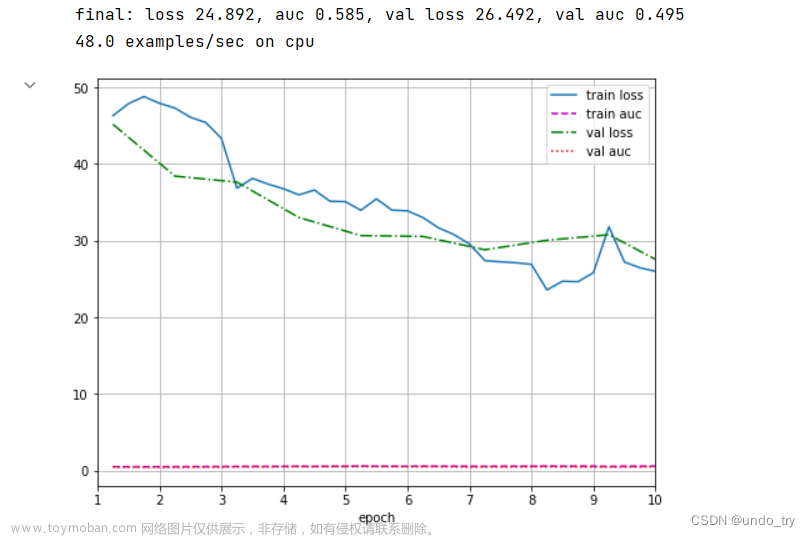 文章来源地址https://www.toymoban.com/news/detail-706267.html
文章来源地址https://www.toymoban.com/news/detail-706267.html
2.4 模型的预测
y_pred_probs = net(torch.tensor(test_set.values).float())
y_pred = torch.where(
y_pred_probs>0.5,
torch.ones_like(y_pred_probs),
torch.zeros_like(y_pred_probs)
)
y_pred.data[:10]
到了这里,关于深度学习推荐系统(五)Deep&Crossing模型及其在Criteo数据集上的应用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!