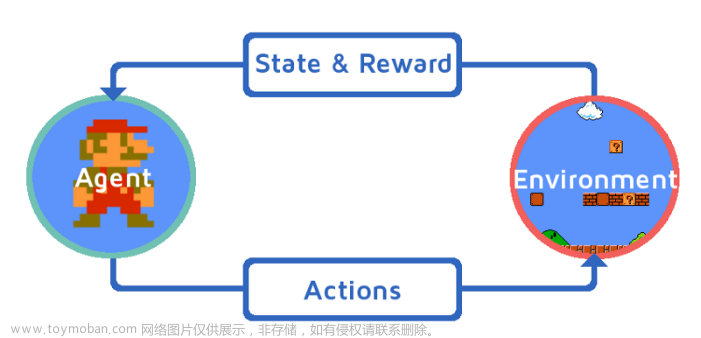
强化学习和前面提到的几种预测模型都不一样,reinforcement learning更多时候使用在控制一些东西上,在算法的本质上很接近我们曾经学过的DFS求最短路径.
强化学习经常用在一些游戏ai的训练,以及一些比如火星登陆器,月球登陆器等等工程领域,强化学习的内容很简单,本质就是获取状态,决定下一步动作,从而得到更好的分数或者收益,亦或者更低一些的损耗.
1.强化学习的准备(一些概念)
强化学习的本质就是通过一些数据训练,让模型知道什么时候采取什么action能获得更好的return,并且修改自身的state,这样的数据可以写成如下格式
第一项为当前的状态 ,
第二项为即将采取的行动 ,
第三项为当前状态得到的奖励 ,
第四项为下一步的动作 ,
这四项就能满足我们对于数据训练和信息检索等等要求 .
回报return:
回报指的是在某个状态,模型能拿到的奖励数值,通常使用R来进行表示. 而r称之为折扣因子,也叫做时间代价.一般情况下,总回报的计算方法为
策略action:
策略指的是不同的动作,更改当前的状态.比如直升机当前状态为收到微风,悬停能拿到更好的稳定性,则策略就算加快尾翼转速.
状态state:
这个就不用多说了
状态价值函数Q(s,a):
状态价值函数的值的含义是,在S状态下,选择a动作,最后能拿到的最大总收益
举个例子,我们现在有这样一个情况
![[machine Learning]强化学习,机器学习,人工智能](https://imgs.yssmx.com/Uploads/2023/09/706328-1.png) 我们设定一个小车或者是一些别的东西,在2345四个状态上能拿到的收益都是0,但是在两侧分别能拿到100和40的奖励数值
我们设定一个小车或者是一些别的东西,在2345四个状态上能拿到的收益都是0,但是在两侧分别能拿到100和40的奖励数值
这个图里,我们在某个位置出发,能达到最大点的情况我们先列出来
![[machine Learning]强化学习,机器学习,人工智能](https://imgs.yssmx.com/Uploads/2023/09/706328-2.png)
(因为只有左右两种走法,很容易计算出来,具体的计算可以用递归实现)
接下来,比如说
Q(3,左)=0+ 0.5*0 + 100* 0.25 =25(我们假设r=0.5)
Q(4,左)=0+ 0.5*0 + 0* 0.25+ 0.125*0 + 0.0625*100=6.25
贝尔曼方程:
贝尔曼方程其实就是一个计算式子,很符合直观逻辑(某种意义上是一个状态转移方程或者递归方程式?)
我们假设
s,a为当前的状态和准备动作,s'和a'为下一个状态和准备动作
这不就是状态转移方程????
2.关于如何获取数据并且训练
一般来说,我们的每个数组都可以凑成一个元组
我们仍然可以用神经网络等等手段进行计算,只要凑出监督学习的数据
这样使用一个元组数据就可以获得一个用来计算的数据
将这些数据投入神经网络进行计算即可.
最后再使用训练好的模型的时候,比如说投入一个s和a,我们可以得到预测的y值
从各种预测的y值中,选择一个最好的情况,与之对应的动作a,就是我们应该采取的方案
(end)写在最后
从八月初开始学习机器学习,中途历经回家,做项目,做课程作业,演示汇报等等一系列杂事,终于是在九月初学习完了机器学习基础.
这一系列的博客最开始使用英语写的,但是因为一些原因,我需要加速学完机器学习,所以后面全部使用中文书写了.后面有机会我会搬到其他地方在换成英语.
这个系列的博客有些理解来自我的个人想法,可能不是很正确,也有很多错误.后面的代码实现我计划使用d2l或者pytorch来完成一些简单的模拟.
emm如果有错误希望能够指出来吧,小白感谢各位大神的指正
2023.9.7文章来源:https://www.toymoban.com/news/detail-706328.html
文章来源地址https://www.toymoban.com/news/detail-706328.html
到了这里,关于[machine Learning]强化学习的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!