案例1-TOP N个数据的值
输入数据:
1,1768,50,155
2,1218,600,211
3,2239,788,242
4,3101,28,599
5,4899,290,129
6,3110,54,1201
7,4436,259,877
8,2369,7890,27处理代码:
def main(args: Array[String]): Unit = {
//创建SparkContext对象
val conf:SparkConf = new SparkConf()
conf.setAppName("test1").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
var index: Int = 0
//通过加载本地文件系统的数据创建RDD对象
val rdd: RDD[String] = sc.textFile("data/file1.txt")
rdd.filter(line=>line.split(",").length == 4)
.map(line=>line.split(",")(2))
.map(word=>(word.toInt,1))
.sortByKey(false)
.map(kv=>kv._1).take(5)
.foreach(key=>{
index += 1
println(index + s"\t$key")
}
)
//关闭SparkContext对象
sc.stop()
}代码解析:
-
sc.textFile("data/file1.txt"):通过加载本地文件来创建RDD对象 -
rdd.filter(line=>line.split(",").length == 4):确保数据的完整性 -
map(line=>line.split(",")(2)):通过逗号将一行字符串分隔开来组成一个Array数组并取出数组中第3个严肃 -
map(word=>(word.toInt,1)):因为我们的sortByKey方法是针对键值对进行操作的,所以必须把我们上面取出来的值转为(值,x)形式的键值对。
-
sortByKey(false):设置参数为false表示降序排列。
-
map(kv=>kv._1).take(5):取出top五。
运行结果:
1 7890
2 788
3 600
4 290
5 259案例2-文件排序
要求:输入三个文件(每行一个数字),要求输出一个文件,文件内文本格式为(序号 数值)。
rdd.map(num => (num.toInt,1))
.partitionBy(new HashPartitioner(1))
.sortByKey().map(t=>{
index += 1
(index,t._1)
}).foreach(println) //只有调用 行动操作语句 才会触发真正的从头到尾的计算
我们会发现,如果我们不调用 foreach 这个行动操作而是直接在转换操作中进行输出的话,这样是输出不来结果的,所以我们必须要调用行动操作。
而且,我们必须对分区进行归并,因为在分布式环境下,只有把多个分区合并成一个分区,才能使得结果整体有序。(这里尽管我们是本地测试,数据源是一个目录下的文件,但是我们也要考虑到假如是在分布式环境下的情况)
运行结果:
(1,1)
(2,4)
(3,5)
(4,12)
(5,16)
(6,25)
(7,33)
(8,37)
(9,39)
(10,40)
(11,45)案例3-二次排序
要求:对格式为(数值 数值)类型的数据进行排序,假如第一个数值相同,则比较第二个数值。
import com.study.spark.core.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
class SecondarySortKey(val first:Int,val second:Int) extends Ordered[SecondarySortKey] with Serializable {
override def compare(other: SecondarySortKey): Int = {
if (this.first - other.first != 0) {
this.first - other.first
}else{
this.second-other.second
}
}
}
object SecondarySortKey{
def main(args: Array[String]): Unit = {
val conf:SparkConf = new SparkConf()
conf.setAppName("test3").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val rdd: RDD[String] = sc.textFile("data/sort/test03.txt")
val rdd2: RDD[(SecondarySortKey, String)] = rdd.map(line => (new SecondarySortKey(line.split(" ")(0).toInt, line.split(" ")(1).toInt), line))
rdd2.sortByKey(false).map(t=>t._2).foreach(println)
sc.stop()
}
}这里我们使用了自定义的类并继承了Ordered 和 Serializable 这两个特质,为了实现自定义的排序规则。 其中,Ordered 特质的混入需要重写它的 compare 方法来实现我们的自定义比较规则,而 Serializable 的混入作用是使得我们的对象可以序列化,以便在网络中可以传输。
运行结果:
8 3
5 6
5 3
4 9
4 7
3 2
1 6案例4-平均成绩
给出三门成绩的三个文件,要求算出每位学生的平均成绩。
//读入数据
val rdd: RDD[String] = sc.textFile("data/rdd/test3")
rdd.map(line=>(line.split(" ")(0),line.split(" ")(1).toInt))
.map(t=>(t._1,(t._2,1)))
.reduceByKey((t1,t2)=>(t1._1+t2._1,t1._2+t2._2))
.mapValues(t=>t._1/t._2.toFloat)
.foreach(println)运行结果:
(小新,88.333336)
(小丽,88.666664)
(小明,89.666664)
(小红,83.666664)综合案例
输入数据格式:(姓名,课程名,成绩)
Aaron,OperatingSystem,100
Aaron,Python,50
Aaron,ComputerNetwork,30
Aaron,Software,94
Abbott,DataBase,18
Abbott,Python,82
Abbott,ComputerNetwork,76
Abel,Algorithm,30
Abel,DataStructure,38
Abel,OperatingSystem,38
...import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object RDDPractice {
def main(args: Array[String]): Unit = {
val conf:SparkConf = new SparkConf()
conf.setAppName("test-last").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val rdd: RDD[String] = sc.textFile("data/chapter5-data1.txt")
//(1)该系共有多少名学生
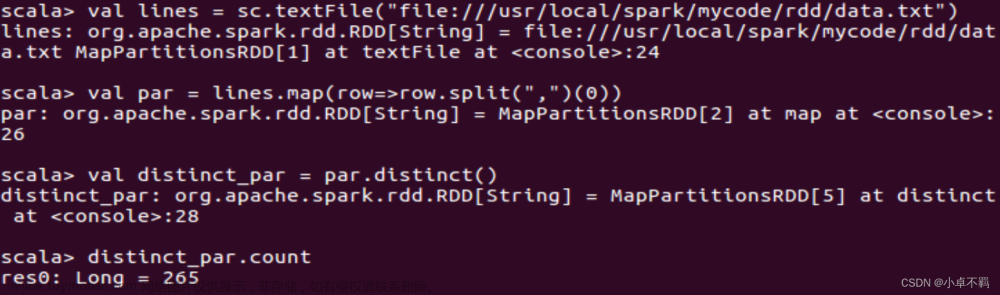
val nums: Long = rdd.map(line => line.split(",")(0)).distinct().count()
println("该系一共 "+nums+" 名学生")
//(2)该系共开设多少门课程
val course_nums: Long = rdd.map(line => line.split(",")(1)).distinct().count()
println("该系一共 "+course_nums+" 门课程")
//(3)学生 Tom 的总成绩和平均成绩分别是多少
val score: Double = rdd.filter(line => line.contains("Tom")).map(line => line.split(",")(2).toInt).sum()
val avg: Double = score/rdd.filter(line => line.contains("Tom")).map(line=>line.split(",")(1)).count()
println("Tom 的总成绩为 "+score+",平均成绩为 "+avg)
//(4)求每名同学的选修的课程门数
rdd.map(line=>(line.split(",")(0),line.split(",")(1))) //(学生名,课程名)
.mapValues(v => (v,1)) //(学生名,(课程名,1))
.reduceByKey((k,v)=>("",k._2+v._2)) //(学生名,("",1+1+1)) 合并课程总数
.mapValues(x => x._2) //(学生名,课程总数)
.foreach(println)
//(5)该系DataBase课程共有多少人选修
val l = rdd.filter(line => line.split(",")(1) == "DataBase").count()
println("选修DataBase课程的人数为 "+l)
//(6)各门课程的平均分是多少
//(学生,课程名,成绩)=>课程总成绩/该课程的学生数
val res: RDD[(String, Float)] = rdd.map(line => (line.split(",")(1), line.split(",")(2).toInt)) //(课程名,成绩)
.combineByKey(
score => (score, 1), //(成绩,1)
(acc: (Int, Int), score) => (acc._1 + score, acc._2 + 1), //(成绩1+成绩2,1+1)
(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2) //(成绩+成绩,1+1)
).map({
case (key, value) => (key, value._1 / value._2.toFloat) //(课程名,总课程成绩/课程人数)
})
res.saveAsTextFile("data/rdd/practice")
sc.stop()
}
}
运行结果:
该系一共 265 名学生
该系一共 8 门课程
Tom 的总成绩为 154.0,平均成绩为 30.8
(Ford,3)
(Lionel,4)
(Verne,3)
(Lennon,4)
(Joshua,4)
(Marvin,3)
(Marsh,4)
(Bartholomew,5)
(Conrad,2)
(Armand,3)
(Jonathan,4)
(Broderick,3)
(Brady,5)
(Derrick,6)
(Rod,4)
(Willie,4)
(Walter,4)
(Boyce,2)
(Duncann,5)
(Elvis,2)
(Elmer,4)
(Bennett,6)
(Elton,5)
(Jo,5)
(Jim,4)
(Adonis,5)
(Abel,4)
(Peter,4)
(Alvis,6)
(Joseph,3)
(Raymondt,6)
(Kerwin,3)
(Wright,4)
(Adam,3)
(Borg,4)
(Sandy,1)
(Ben,4)
(Miles,6)
(Clyde,7)
(Francis,4)
(Dempsey,4)
(Ellis,4)
(Edward,4)
(Mick,4)
(Cleveland,4)
(Luthers,5)
(Virgil,5)
(Ivan,4)
(Alvin,5)
(Dick,3)
(Bevis,4)
(Leo,5)
(Saxon,7)
(Armstrong,2)
(Hogan,4)
(Sid,3)
(Blair,4)
(Colbert,4)
(Lucien,5)
(Kerr,4)
(Montague,3)
(Giles,7)
(Kevin,4)
(Uriah,1)
(Jeffrey,4)
(Simon,2)
(Elijah,4)
(Greg,4)
(Colin,5)
(Arlen,4)
(Maxwell,4)
(Payne,6)
(Kennedy,4)
(Spencer,5)
(Kent,4)
(Griffith,4)
(Jeremy,6)
(Alan,5)
(Andrew,4)
(Jerry,3)
(Donahue,5)
(Gilbert,3)
(Bishop,2)
(Bernard,2)
(Egbert,4)
(George,4)
(Noah,4)
(Bruce,3)
(Mike,3)
(Frank,3)
(Boris,6)
(Tony,3)
(Christ,2)
(Ken,3)
(Milo,2)
(Victor,2)
(Clare,4)
(Nigel,3)
(Christopher,4)
(Robin,4)
(Chad,6)
(Alfred,2)
(Woodrow,3)
(Rory,4)
(Dennis,4)
(Ward,4)
(Chester,6)
(Emmanuel,3)
(Stan,3)
(Jerome,3)
(Corey,4)
(Harvey,7)
(Herbert,3)
(Maurice,2)
(Merle,3)
(Les,6)
(Bing,6)
(Charles,3)
(Clement,5)
(Leopold,7)
(Brian,6)
(Horace,5)
(Sebastian,6)
(Bernie,3)
(Basil,4)
(Michael,5)
(Ernest,5)
(Tom,5)
(Vic,3)
(Eli,5)
(Duke,4)
(Alva,5)
(Lester,4)
(Hayden,3)
(Bertram,3)
(Bart,5)
(Adair,3)
(Sidney,5)
(Bowen,5)
(Roderick,4)
(Colby,4)
(Jay,6)
(Meredith,4)
(Harold,4)
(Max,3)
(Scott,3)
(Barton,1)
(Elliot,3)
(Matthew,2)
(Alexander,4)
(Todd,3)
(Wordsworth,4)
(Geoffrey,4)
(Devin,4)
(Donald,4)
(Roy,6)
(Harry,4)
(Abbott,3)
(Baron,6)
(Mark,7)
(Lewis,4)
(Rock,6)
(Eugene,1)
(Aries,2)
(Samuel,4)
(Glenn,6)
(Will,3)
(Gerald,4)
(Henry,2)
(Jesse,7)
(Bradley,2)
(Merlin,5)
(Monroe,3)
(Hobart,4)
(Ron,6)
(Archer,5)
(Nick,5)
(Louis,6)
(Len,5)
(Randolph,3)
(Benson,4)
(John,6)
(Abraham,3)
(Benedict,6)
(Marico,6)
(Berg,4)
(Aldrich,3)
(Lou,2)
(Brook,4)
(Ronald,3)
(Pete,3)
(Nicholas,5)
(Bill,2)
(Harlan,6)
(Tracy,3)
(Gordon,4)
(Alston,4)
(Andy,3)
(Bruno,5)
(Beck,4)
(Phil,3)
(Barry,5)
(Nelson,5)
(Antony,5)
(Rodney,3)
(Truman,3)
(Marlon,4)
(Don,2)
(Philip,2)
(Sean,6)
(Webb,7)
(Solomon,5)
(Aaron,4)
(Blake,4)
(Amos,5)
(Chapman,4)
(Jonas,4)
(Valentine,8)
(Angelo,2)
(Boyd,3)
(Benjamin,4)
(Winston,4)
(Allen,4)
(Evan,3)
(Albert,3)
(Newman,2)
(Jason,4)
(Hilary,4)
(William,6)
(Dean,7)
(Claude,2)
(Booth,6)
(Channing,4)
(Jeff,4)
(Webster,2)
(Marshall,4)
(Cliff,5)
(Dominic,4)
(Upton,5)
(Herman,3)
(Levi,2)
(Clark,6)
(Hiram,6)
(Drew,5)
(Bert,3)
(Alger,5)
(Brandon,5)
(Antonio,3)
(Elroy,5)
(Leonard,2)
(Adolph,4)
(Blithe,3)
(Kenneth,3)
(Perry,5)
(Matt,4)
(Eric,4)
(Archibald,5)
(Martin,3)
(Kim,4)
(Clarence,7)
(Vincent,5)
(Winfred,3)
(Christian,2)
(Bob,3)
(Enoch,3)
选修DataBase课程的人数为 126各门课程的平均分是多少,输出文件:
(CLanguage,50.609375)
(Software,50.909092)
(Python,57.82353)
(Algorithm,48.833332)
(DataStructure,47.572517)
(DataBase,50.539684)
(ComputerNetwork,51.90141)
(OperatingSystem,54.9403)解析
(1)该系共有多少名学生
首先使用map 转换操作从数据中提取出来所有的学生姓名,然后使用转换操作 distinct 函数去重,最后使用行动操作 count 进行统计。
//(1)该系共有多少名学生
val nums: Long = rdd.map(line => line.split(",")(0)).distinct().count()
(2)该系共开设多少门课程
同(1),不同的是我们提取的是所有的课程名。
//(2)该系共开设多少门课程
val course_nums: Long = rdd.map(line => line.split(",")(1)).distinct().count()
(3)学生 Tom 的总成绩和平均成绩分别是多少
对于总成绩,使用过滤函数 filter 提取出含有"Tom"的数据行,然后将一行字符串转为多个字段并取出成绩字段的值并求和。
对于平均成绩,我们计算出科目的数量然后用总成绩除以它即可。
//(3)学生 Tom 的总成绩和平均成绩分别是多少
val score: Double = rdd.filter(line => line.contains("Tom")).map(line => line.split(",")(2).toInt).sum()
val avg: Double = score/rdd.filter(line => line.contains("Tom")).map(line=>line.split(",")(1)).count()
println("Tom 的总成绩为 "+score+",平均成绩为 "+avg)(4)求每名同学的选修的课程门数
先取出学生名和课程名,把学生名最为key,课程名通过mapValues函数转为(课程名,1)的形式,对于相同的学生,通过reduceByKey函数累加它的课程数,通过mapValues函数将键值对形式的value转为单个的值-课程总数。
//(4)求每名同学的选修的课程门数
rdd.map(line=>(line.split(",")(0),line.split(",")(1))) //(学生名,课程名)
.mapValues(v => (v,1)) //(学生名,(课程名,1))
.reduceByKey((k,v)=>("",k._2+v._2)) //(学生名,("",1+1+1)) 合并课程总数
.mapValues(x => x._2) //(学生名,课程总数)
.foreach(println)(5)该系DataBase课程共有多少人选修
直接通过 count 函数对字段1为"DataBase"的数据行进行统计。
//(5)该系DataBase课程共有多少人选修
val l = rdd.filter(line => line.split(",")(1) == "DataBase").count()
(6)各门课程的平均分是多少
通过combineByKey函数通过对每个key(课程)对应的value(成绩)转为(成绩,1)的形式,
然后对相同的key(课程)的值(成绩,1)进行合并,将成绩和次数进行累加,
对于不同分区的数据也是一样,对成绩和次数都进行累加,
最后按照要求的格式输出(课程名,总成绩/总次数=课程平均成绩)文章来源:https://www.toymoban.com/news/detail-706345.html
//(6)各门课程的平均分是多少
//(学生,课程名,成绩)=>课程总成绩/该课程的学生数
val res: RDD[(String, Float)] = rdd.map(line => (line.split(",")(1), line.split(",")(2).toInt)) //(课程名,成绩)
.combineByKey(
score => (score, 1), //(成绩,1)
(acc: (Int, Int), score) => (acc._1 + score, acc._2 + 1), //(成绩1+成绩2,1+1)
(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2) //(成绩+成绩,1+1)
).map({
case (key, value) => (key, value._1 / value._2.toFloat) //(课程名,总课程成绩/课程人数)
})除此之外,也可以用reduceByKey来进行解决,二者的原理是一样的:文章来源地址https://www.toymoban.com/news/detail-706345.html
rdd.map(line => (line.split(",")(1), line.split(",")(2).toInt))
.map(t => (t._1, (t._2, 1)))
.reduceByKey((t1, t2) => (t1._1 + t2._1, t1._2 + t2._2))
.map(t => (t._1, t._2._1 / t._2._2.toFloat)) //这行代码可以用mapValues()替换,因为我们本来就是只对value进行操作,key不需要改变
.foreach(println)到了这里,关于Spark【RDD编程(四)综合案例】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!