上篇文字讲到了可以截屏手机模拟器上的界面并传回电脑上,文章链接
python将手机模拟器截屏并发送至电脑上_小小爬虾的博客-CSDN博客
传回来以后,就可以识别出图片中的文字内容了。
我使用的是Python3.10.4+百度的AipOCR库实现图像文字识别。
1、首先安装库
参考我的文章如何在python3下安装库
记录一下python2和python3在同一台电脑上共存使用并安装各自的库以及各自在pycharm中使用的方法_小小爬虾的博客-CSDN博客
pip3 install baidu-aip -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
pip3 install chardet
2、获取百度文字识别的Key
(1)登陆网址百度文字识别,覆盖全面,响应迅速,准确率超99%-百度AI开放平台
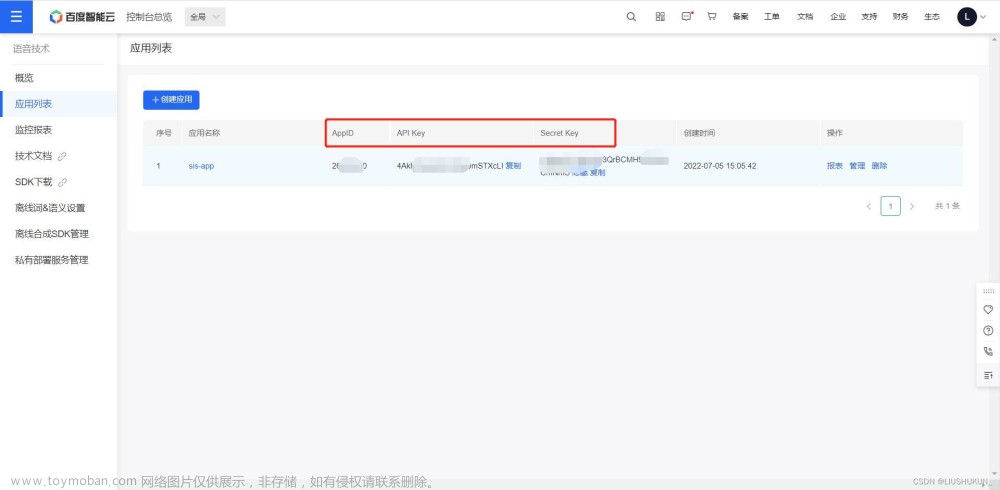
(2)进入控制台https://console.bce.baidu.com/ai/#/ai/speech/app/list
(3)创建应用

(4)写应用名字,接口选择,应用归属,应用描述


(5)创建后返回列表即可得到Key

APP_ID = '39108806'
API_KEY = '6uA3Zfghijklmnopqrstuvw'
SECRET_KEY = 'jV18PFGHIJKLMNOPQRSTUVW'
3、写代码
from aip import AipOcr
#百度识别的KEY
APP_ID = '12345678'
API_KEY = 'abcdefghijklmnopqrstuvw'
SECRET_KEY = 'ABCDEFGHIJKLMNOPQRSTUVW'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
def baidu_ocr_text(img_p_n):
# 百度文本识别AipOcr
image = open(img_p_n, 'rb').read()
#识别模式,有好几种,下面有介绍
msg = client.basicGeneral(image)
text = 'result:\n'
for i in msg.get('words_result'):
text += (i.get('words') + '\n')
print(type(text))
text=text.replace('\u04B0','').replace('\uFFE5','').replace('\u00A5','')
print(text)
def main():
baidu_ocr_text("./img/example.png")
if __name__ == '__main__':
main()百度文字识别有几种模式,经研究如下:
# 标准版
msg = client.basicGeneral(image)
# 高精度版
msg = client.basicAccurate(image)
# 通用文字识别(含位置信息版)
msg = client.general(image)
# 通用文字识别(含位置高精度版)
msg = client.accurate(image)
# 通用文字识别(含生僻字版)
msg = client.enhancedGeneral(image)
#{u'error_code': 6, u'error_msg': u'No permission to access data'},不知道何种原因
#网络图片文字识别
msg = client.webImage(image)
#如果提示{u'error_code': 17, u'error_msg': u'Open api daily request limit reached'},百度识别每日有上限4、给出一张图片(比如手机截屏的图片./img/example.png)

运行程序,结果如图:
 文章来源:https://www.toymoban.com/news/detail-706637.html
文章来源:https://www.toymoban.com/news/detail-706637.html
可见由上至下、由左至右将图片中的文字识别,还是很准确的。文章来源地址https://www.toymoban.com/news/detail-706637.html
到了这里,关于python使用百度AipOCR来实现图像文字识别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!