今天社群中的小伙伴面试遇到了一个问题,如何保证生成式语言模型在同样的输入情况下可以保证同样的输出。
这里面造成问题的因素有两个方面:
一个方面是在forward过程中参数的计算出现了差异,这种情况一般发生在游戏显卡中,游戏显卡无法保证每一次底层算子计算都是成功的,也没有办法保证同输入同输出,这里我们就需要采用具有ecc内存纠错机智的专用显卡用来解决相关的问题。
二个方面发生在进行概率预估时候的算法不同,导致生成的结果不同。
接下来带来今天的核心内容,transformers中的generate函数解析工作的介绍。
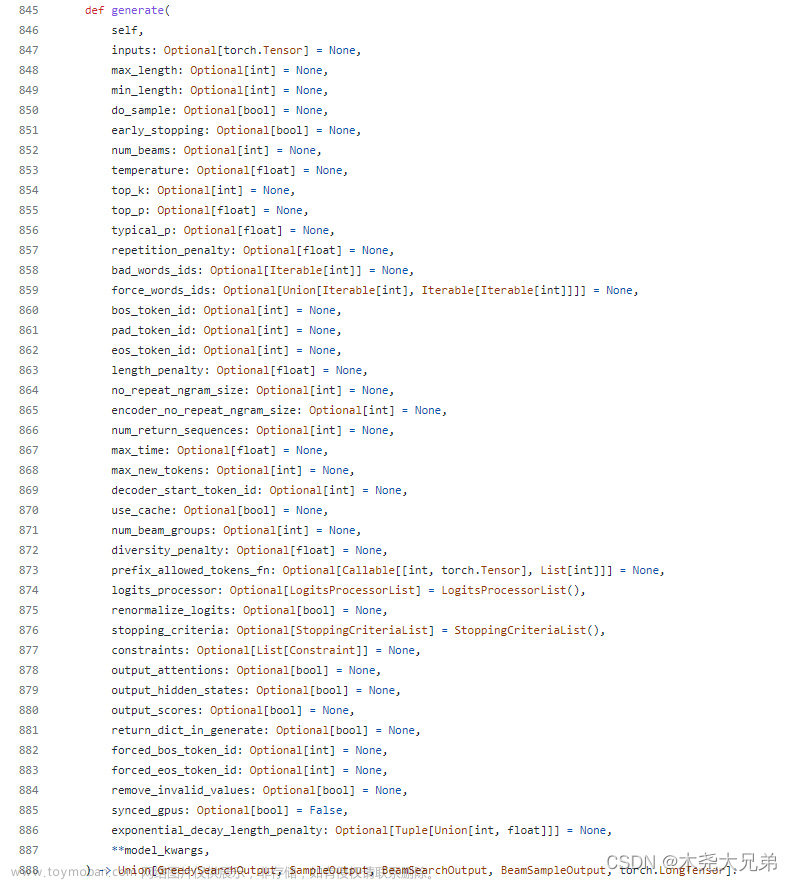
Generates sequences of token ids for models with a language modeling head.
<Tip warning={true}>
Most generation-controlling parameters are set in `generation_config` which, if not passed, will be set to the
model's default generation configuration. You can override any `generation_config` by passing the corresponding
parameters to generate(), e.g. `.generate(inputs, num_beams=4, do_sample=True)`.
For an overview of generation strategies and code examples, check out the [following
guide](../generation_strategies).
</Tip>
Parameters:
inputs (`torch.Tensor` of varying shape depending on the modality, *optional*):
The sequence used as a prompt for the generation or as model inputs to the encoder. If `None` the
method initializes it with `bos_token_id` and a batch size of 1. For decoder-only models `inputs`
should of in the format of `input_ids`. For encoder-decoder models *inputs* can represent any of
`input_ids`, `input_values`, `input_features`, or `pixel_values`.
generation_config (`~generation.GenerationConfig`, *optional*):
The generation configuration to be used as base parametrization for the generation call. `**kwargs`
passed to generate matching the attributes of `generation_config` will override them. If
`generation_config` is not provided, the default will be used, which had the following loading
priority: 1) from the `generation_config.json` model file, if it exists; 2) from the model
configuration. Please note that unspecified parameters will inherit [`~generation.GenerationConfig`]'s
default values, whose documentation should be checked to parameterize generation.
logits_processor (`LogitsProcessorList`, *optional*):
Custom logits processors that complement the default logits processors built from arguments and
generation config. If a logit processor is passed that is already created with the arguments or a
generation config an error is thrown. This feature is intended for advanced users.
stopping_criteria (`StoppingCriteriaList`, *optional*):
Custom stopping criteria that complement the default stopping criteria built from arguments and a
generation config. If a stopping criteria is passed that is already created with the arguments or a
generation config an error is thrown. This feature is intended for advanced users.
prefix_allowed_tokens_fn (`Callable[[int, torch.Tensor], List[int]]`, *optional*):
If provided, this function constraints the beam search to allowed tokens only at each step. If not
provided no constraint is applied. This function takes 2 arguments: the batch ID `batch_id` and
`input_ids`. It has to return a list with the allowed tokens for the next generation step conditioned
on the batch ID `batch_id` and the previously generated tokens `inputs_ids`. This argument is useful
for constrained generation conditioned on the prefix, as described in [Autoregressive Entity
Retrieval](https://arxiv.org/abs/2010.00904).
synced_gpus (`bool`, *optional*, defaults to `False`):
Whether to continue running the while loop until max_length (needed for ZeRO stage 3)
kwargs:
Ad hoc parametrization of `generate_config` and/or additional model-specific kwargs that will be
forwarded to the `forward` function of the model. If the model is an encoder-decoder model, encoder
specific kwargs should not be prefixed and decoder specific kwargs should be prefixed with *decoder_*.
Return:
[`~utils.ModelOutput`] or `torch.LongTensor`: A [`~utils.ModelOutput`] (if `return_dict_in_generate=True`
or when `config.return_dict_in_generate=True`) or a `torch.FloatTensor`.
If the model is *not* an encoder-decoder model (`model.config.is_encoder_decoder=False`), the possible
[`~utils.ModelOutput`] types are:
- [`~generation.GreedySearchDecoderOnlyOutput`],
- [`~generation.SampleDecoderOnlyOutput`],
- [`~generation.BeamSearchDecoderOnlyOutput`],
- [`~generation.BeamSampleDecoderOnlyOutput`]
If the model is an encoder-decoder model (`model.config.is_encoder_decoder=True`), the possible
[`~utils.ModelOutput`] types are:
- [`~generation.GreedySearchEncoderDecoderOutput`],
- [`~generation.SampleEncoderDecoderOutput`],
- [`~generation.BeamSearchEncoderDecoderOutput`],
- [`~generation.BeamSampleEncoderDecoderOutput`]
接下来我们分段来看这个内容。第一段对这个内容的整体做了介绍
将语言模型头用于模型的生成序列的 token ID。
<提示警告={true}>
大多数生成控制参数都设置在 generation_config 中,如果没有传递,则将设置为模型的默认生成配置。您可以通过传递相应的参数来覆盖任何 generation_config,例如 .generate(inputs, num_beams=4, do_sample=True)。
有关生成策略的概述和代码示例,请参见 以下指南。
</提示>
第二段描述了这个方法对应的入参体系
参数:
inputs (torch.Tensor of varying shape depending on the modality,optional):
生成使用的序列或模型输入到编码器。如果None,方法将它初始化为bos_token_id和一个大小为1的批次大小。对于只包含解码器的模型,inputs应该以input_ids的形式输入。对于编码器-解码器模型,inputs可以代表input_ids,input_values,input_features或pixel_values的任何一种。
generation_config (~generation.GenerationConfig,optional):
用于生成的基参数化。如果generation_config不可用,则默认值将使用模型配置中的默认值。如果提供的参数与generation_config中的参数匹配,则将使用这些参数。如果不提供generation_config,则将使用以下加载顺序:1)从generation_config.json模型文件中获取;2)从模型配置中获取。请注意,未指定的参数将继承~generation.GenerationConfig的默认值,其文档应该用于参数化生成。
logits_processor (LogitsProcessorList,optional):
用于补充默认logits处理器的自定义logits处理器。如果提供的logits处理器已经使用了相同的参数或生成配置,则会引发错误。此功能旨在为高级用户提供便利。
stopping_criteria (StoppingCriteriaList,optional):
用于补充默认停止准则的自定义停止准则。如果提供的停止准则已经使用了相同的参数或生成配置,则会引发错误。此功能旨在为高级用户提供便利。
prefix_allowed_tokens_fn (Callable[[int, torch.Tensor], List[int]],optional):
如果提供,则此函数仅约束搜索到的令牌。如果未提供,则不应用任何约束。此函数需要两个参数:批次IDbatch_id和input_ids。它应该返回一个条件为batch_id和以前生成的令牌inputs_ids的令牌列表。此功能可用于约束带前缀的生成,如自回归实体检索中所述。
synced_gpus (bool,*optional,默认为False):
是否继续运行循环直到最大长度(需要ZeRO阶段3)
kwargs:
随机参数化generate_config和/或特定于模型的
第三段是返回参数的介绍
这个函数的返回值是一个包含生成文本的模型输出对象或是一个LongTensor类型的张量。如果模型是非编码解码模型(model.config.is_encoder_decoder=False),则可能的输出类型包括:GreedySearchDecoderOnlyOutput、SampleDecoderOnlyOutput、BeamSearchDecoderOnlyOutput和BeamSampleDecoderOnlyOutput。如果模型是编码解码模型(model.config.is_encoder_decoder=True),则可能的输出类型包括:GreedySearchEncoderDecoderOutput、SampleEncoderDecoderOutput、BeamSearchEncoderDecoderOutput和BeamSampleEncoderDecoderOutput。
那这里引出了核心的生成式解码器的四个算法,分别是GreedySearch、Sample、BeamSearch、BeamSample。
GreedySearch、Sample、BeamSearch 和 BeamSample 都是用于解码自然语言序列的搜索算法,其中 GreedySearch 和 Sample 是基于概率的方法,而 BeamSearch 和 BeamSample 则是基于动态规划的方法。下面详细介绍这四种解码策略。
1.GreedySearch
GreedySearch 算法是一种最简单的解码策略,它每次选择当前概率最高的单词作为输出。也就是说,它每次选择当前概率最高的单词作为输出,直到输出序列达到指定的长度或者达到终止状态。
GreedySearch 算法的优点是简单易懂,计算速度快,但它的缺点是可能无法输出最佳解码序列。在一些特定的情况下,GreedySearch 算法可能会导致输出序列出现错误或不自然。
2.Sample
Sample 算法是基于概率的方法,它在每次选择输出单词时,不仅考虑当前单词的概率,还会考虑前面已经选择的单词的概率。具体来说,Sample 算法会在当前概率最高的单词和概率最高的单词序列(即前面已经选择的单词)之间进行选择。
Sample 算法的优点是可以输出较优的解码序列,但它的缺点是计算时间较长,尤其是在解码长序列时。此外,由于 Sample 算法需要考虑前面已经选择的单词的概率,因此它可能会受到模型预测能力的限制。
3.BeamSearch
BeamSearch 算法是基于动态规划的方法,它通过维护一系列的解码状态来表示当前解码过程中的可能状态。在每次选择输出单词时,它会从当前解码状态中选择概率最高的状态作为输出,然后更新解码状态。
BeamSearch 算法的优点是可以输出较优的解码序列,并且计算时间相对较短,尤其是在解码长序列时。此外,由于 BeamSearch 算法可以维护多个解码状态,因此它具有一定的容错能力,可以在一定程度上避免由于模型预测能力的限制而导致的输出错误。
4.BeamSample
BeamSample 算法是基于 BeamSearch 的一种变体,它与 BeamSearch 算法类似,但在选择输出单词时,它不仅考虑当前单词的概率,还会考虑前面已经选择的单词的概率。具体来说,它会从当前解码状态中选择概率最高的状态作为输出,然后更新解码状态。
BeamSample 算法的优点是可以输出较优的解码结果,因为它考虑了前面已经选择的单词的概率。此外,由于 BeamSample 算法可以处理较长的句子,因此在处理长文本时,它通常比 BeamSearch 算法更有效。
在自然语言处理中, BeamSample 算法可以用于语音识别、机器翻译、对话系统等多种任务。例如,在语音识别中, BeamSample 算法可以帮助识别系统从一系列可能的语音输出中选择最可能的输出,从而提高识别精度。
这里有小伙伴有疑问了,我们经常设置的top-k和top-t又去哪里了呢。我们别着急接着往下看。
from transformers.generation import GenerationConfig
在这个参数下,我们可以看到生成配置的参数都有哪些。接下来我们详细的看一下,这个类中都有哪些参数。
Class that holds a configuration for a generation task. A `generate` call supports the following generation methods
for text-decoder, text-to-text, speech-to-text, and vision-to-text models:
- *greedy decoding* by calling [`~generation.GenerationMixin.greedy_search`] if `num_beams=1` and
`do_sample=False`
- *contrastive search* by calling [`~generation.GenerationMixin.contrastive_search`] if `penalty_alpha>0.`
and `top_k>1`
- *multinomial sampling* by calling [`~generation.GenerationMixin.sample`] if `num_beams=1` and
`do_sample=True`
- *beam-search decoding* by calling [`~generation.GenerationMixin.beam_search`] if `num_beams>1` and
`do_sample=False`
- *beam-search multinomial sampling* by calling [`~generation.GenerationMixin.beam_sample`] if
`num_beams>1` and `do_sample=True`
- *diverse beam-search decoding* by calling [`~generation.GenerationMixin.group_beam_search`], if
`num_beams>1` and `num_beam_groups>1`
- *constrained beam-search decoding* by calling [`~generation.GenerationMixin.constrained_beam_search`], if
`constraints!=None` or `force_words_ids!=None`
这段描述了几种算法的配置情况
类用于保存生成任务的配置。调用generate支持以下对于text-decoder、text-to-text、speech-to-text和vision-to-text模型的生成方法:
如果num_beams=1且do_sample=False,则使用贪婪搜索,调用~generation.GenerationMixin.greedy_search。
如果penalty_alpha>0且top_k>1,则使用对比搜索,调用~generation.GenerationMixin.contrastive_search。
如果num_beams=1且do_sample=True,则使用多概率采样,调用~generation.GenerationMixin.sample。
如果num_beams>1且do_sample=False,则使用beam搜索,调用~generation.GenerationMixin.beam_search。
如果num_beams>1且do_sample=True,则使用beam搜索多概率采样,调用~generation.GenerationMixin.beam_sample。
如果num_beams>1且num_beam_groups>1,则使用分群束搜索,调用~generation.GenerationMixin.group_beam_search。
如果num_beams>1且constraints!=None或force_words_ids!=None,则使用约束束搜索,调用~generation.GenerationMixin.constrained_beam_search。
接下来我们继续看注释中还提供了哪些信息
You do not need to call any of the above methods directly. Pass custom parameter values to 'generate'. To learn
more about decoding strategies refer to the [text generation strategies guide](./generation_strategies).
Arg:
> Parameters that control the length of the output
max_length (`int`, *optional*, defaults to 20):
The maximum length the generated tokens can have. Corresponds to the length of the input prompt +
`max_new_tokens`. Its effect is overridden by `max_new_tokens`, if also set.
max_new_tokens (`int`, *optional*):
The maximum numbers of tokens to generate, ignoring the number of tokens in the prompt.
min_length (`int`, *optional*, defaults to 0):
The minimum length of the sequence to be generated. Corresponds to the length of the input prompt +
`min_new_tokens`. Its effect is overridden by `min_new_tokens`, if also set.
min_new_tokens (`int`, *optional*):
The minimum numbers of tokens to generate, ignoring the number of tokens in the prompt.
early_stopping (`bool` or `str`, *optional*, defaults to `False`):
Controls the stopping condition for beam-based methods, like beam-search. It accepts the following values:
`True`, where the generation stops as soon as there are `num_beams` complete candidates; `False`, where an
heuristic is applied and the generation stops when is it very unlikely to find better candidates;
`"never"`, where the beam search procedure only stops when there cannot be better candidates (canonical
beam search algorithm).
max_time(`float`, *optional*):
The maximum amount of time you allow the computation to run for in seconds. generation will still finish
the current pass after allocated time has been passed.
如果我们不进行上述配置,也可以直接调用进行生成。
在使用这个模型进行文本生成时,您也可以不直接调用上述方法。而是将自定义参数值传递给'generate'方法。
参数说明:
max_length:控制生成输出的长度,默认为 20。它的值对应于输入提示的长度加上max_new_tokens。如果同时设置了max_new_tokens,则它的效果将被覆盖。
max_new_tokens:控制要生成的令牌数量,忽略提示中的令牌数量。它的值默认为 0。
min_length:控制生成序列的最小长度,默认为 0。它的值对应于输入提示的长度加上min_new_tokens。如果同时设置了min_new_tokens,则它的效果将被覆盖。
min_new_tokens:控制要生成的令牌数量,忽略提示中的令牌数量。它的值默认为 0。
early_stopping:控制基于 beam 的方法(如 beam-search)的停止条件。它接受以下值:True,表示生成在有num_beams个完整候选项时停止;False,表示应用启发式方法,在找到更好候选项的可能性很小时停止;"never",表示 beam 搜索过程仅在无法找到更好候选项时停止(经典 beam 搜索算法)。
max_time:允许计算运行的最大时间,单位为秒。如果分配的时间已过,生成过程仍会完成当前迭代。
> Parameters that control the generation strategy used
do_sample (`bool`, *optional*, defaults to `False`):
Whether or not to use sampling ; use greedy decoding otherwise.
num_beams (`int`, *optional*, defaults to 1):
Number of beams for beam search. 1 means no beam search.
num_beam_groups (`int`, *optional*, defaults to 1):
Number of groups to divide `num_beams` into in order to ensure diversity among different groups of beams.
[this paper](https://arxiv.org/pdf/1610.02424.pdf) for more details.
penalty_alpha (`float`, *optional*):
The values balance the model confidence and the degeneration penalty in contrastive search decoding.
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should use the past last key/values attentions (if applicable to the model) to
speed up decoding.
这个注释是用于控制生成策略的参数。它包含了以下几个参数:
- do_sample(可选,默认为False):是否使用采样;否则使用贪婪解码。
- num_beams(可选,默认为1):束搜索的束数。1表示不使用束搜索。
- num_beam_groups(可选,默认为1):将num_beams分成若干组,以确保不同束组的多样性。更多详细信息请参考这篇论文(This Paper)。
- penalty_alpha(可选):在对比搜索解码中,平衡模型置信度和退化惩罚的值。
- use_cache(可选,默认为True):模型是否应使用过去的最后一个键/值注意力(如果适用于模型)来加速解码。
> Parameters for manipulation of the model output logits
temperature (`float`, *optional*, defaults to 1.0):
The value used to modulate the next token probabilities.
top_k (`int`, *optional*, defaults to 50):
The number of highest probability vocabulary tokens to keep for top-k-filtering.
top_p (`float`, *optional*, defaults to 1.0):
If set to float < 1, only the smallest set of most probable tokens with probabilities that add up to
`top_p` or higher are kept for generation.
typical_p (`float`, *optional*, defaults to 1.0):
Local typicality measures how similar the conditional probability of predicting a target token next is to
the expected conditional probability of predicting a random token next, given the partial text already
generated. If set to float < 1, the smallest set of the most locally typical tokens with probabilities that
add up to `typical_p` or higher are kept for generation. See [this
paper](https://arxiv.org/pdf/2202.00666.pdf) for more details.
epsilon_cutoff (`float`, *optional*, defaults to 0.0):
If set to float strictly between 0 and 1, only tokens with a conditional probability greater than
`epsilon_cutoff` will be sampled. In the paper, suggested values range from 3e-4 to 9e-4, depending on the
size of the model. See [Truncation Sampling as Language Model
Desmoothing](https://arxiv.org/abs/2210.15191) for more details.
eta_cutoff (`float`, *optional*, defaults to 0.0):
Eta sampling is a hybrid of locally typical sampling and epsilon sampling. If set to float strictly between
0 and 1, a token is only considered if it is greater than either `eta_cutoff` or `sqrt(eta_cutoff) *
exp(-entropy(softmax(next_token_logits)))`. The latter term is intuitively the expected next token
probability, scaled by `sqrt(eta_cutoff)`. In the paper, suggested values range from 3e-4 to 2e-3,
depending on the size of the model. See [Truncation Sampling as Language Model
Desmoothing](https://arxiv.org/abs/2210.15191) for more details.
diversity_penalty (`float`, *optional*, defaults to 0.0):
This value is subtracted from a beam's score if it generates a token same as any beam from other group at a
particular time. Note that `diversity_penalty` is only effective if `group beam search` is enabled.
repetition_penalty (`float`, *optional*, defaults to 1.0):
The parameter for repetition penalty. 1.0 means no penalty. See [this
paper](https://arxiv.org/pdf/1909.05858.pdf) for more details.
encoder_repetition_penalty (`float`, *optional*, defaults to 1.0):
The paramater for encoder_repetition_penalty. An exponential penalty on sequences that are not in the
original input. 1.0 means no penalty.
length_penalty (`float`, *optional*, defaults to 1.0):
Exponential penalty to the length that is used with beam-based generation. It is applied as an exponent to
the sequence length, which in turn is used to divide the score of the sequence. Since the score is the log
likelihood of the sequence (i.e. negative), `length_penalty` > 0.0 promotes longer sequences, while
`length_penalty` < 0.0 encourages shorter sequences.
no_repeat_ngram_size (`int`, *optional*, defaults to 0):
If set to int > 0, all ngrams of that size can only occur once.
bad_words_ids(`List[List[int]]`, *optional*):
List of token ids that are not allowed to be generated. In order to get the token ids of the words that
should not appear in the generated text, use `tokenizer(bad_words, add_prefix_space=True,
add_special_tokens=False).input_ids`.
force_words_ids(`List[List[int]]` or `List[List[List[int]]]`, *optional*):
List of token ids that must be generated. If given a `List[List[int]]`, this is treated as a simple list of
words that must be included, the opposite to `bad_words_ids`. If given `List[List[List[int]]]`, this
triggers a [disjunctive constraint](https://github.com/huggingface/transformers/issues/14081), where one
can allow different forms of each word.
renormalize_logits (`bool`, *optional*, defaults to `False`):
Whether to renormalize the logits after applying all the logits processors or warpers (including the custom
ones). It's highly recommended to set this flag to `True` as the search algorithms suppose the score logits
are normalized but some logit processors or warpers break the normalization.
constraints (`List[Constraint]`, *optional*):
Custom constraints that can be added to the generation to ensure that the output will contain the use of
certain tokens as defined by `Constraint` objects, in the most sensible way possible.
forced_bos_token_id (`int`, *optional*, defaults to `model.config.forced_bos_token_id`):
The id of the token to force as the first generated token after the `decoder_start_token_id`. Useful for
multilingual models like [mBART](../model_doc/mbart) where the first generated token needs to be the target
language token.
forced_eos_token_id (`Union[int, List[int]]`, *optional*, defaults to `model.config.forced_eos_token_id`):
The id of the token to force as the last generated token when `max_length` is reached. Optionally, use a
list to set multiple *end-of-sequence* tokens.
remove_invalid_values (`bool`, *optional*, defaults to `model.config.remove_invalid_values`):
Whether to remove possible *nan* and *inf* outputs of the model to prevent the generation method to crash.
Note that using `remove_invalid_values` can slow down generation.
exponential_decay_length_penalty (`tuple(int, float)`, *optional*):
This Tuple adds an exponentially increasing length penalty, after a certain amount of tokens have been
generated. The tuple shall consist of: `(start_index, decay_factor)` where `start_index` indicates where
penalty starts and `decay_factor` represents the factor of exponential decay
suppress_tokens (`List[int]`, *optional*):
A list of tokens that will be suppressed at generation. The `SupressTokens` logit processor will set their
log probs to `-inf` so that they are not sampled.
begin_suppress_tokens (`List[int]`, *optional*):
A list of tokens that will be suppressed at the beginning of the generation. The `SupressBeginTokens` logit
processor will set their log probs to `-inf` so that they are not sampled.
forced_decoder_ids (`List[List[int]]`, *optional*):
A list of pairs of integers which indicates a mapping from generation indices to token indices that will be
forced before sampling. For example, `[[1, 123]]` means the second generated token will always be a token
of index 123.
在解释这些参数之前,让我们先了解一下这些参数在模型输出 logits(未归一化的概率)的操作中的作用。
temperature (浮点数,可选,默认为 1.0):
这个值用于调整下一个令牌的概率。通过改变这个值,你可以控制生成的文本的随机性。较大的 temperature 值会导致生成的文本更加随机,而较小的 temperature 值则会生成更加确定性的文本。
top_k (整数,可选,默认为 50):
这个参数决定了在 top-k 过滤中保留的最高概率词汇令牌的数量。top-k 过滤是一种技术,用于在生成过程中过滤掉不太可能的令牌。
top_p (浮点数,可选,默认为 1.0):
如果设置为小于 1 的浮点数,那么只有最可能的令牌集合,其概率之和达到或超过 top_p,才会在生成过程中保留。
typical_p (浮点数,可选,默认为 1.0):
局部典型性衡量在给定部分文本生成条件下,预测下一个令牌的概率与随机预测下一个令牌的概率的相似程度。如果设置为小于 1 的浮点数,那么只有最局部典型的令牌集合,其概率之和达到或超过 typical_p,才会在生成过程中保留。
epsilon_cutoff (浮点数,可选,默认为 0.0):
如果设置为在 0 和 1 之间的浮点数,那么只有条件概率大于 epsilon_cutoff 的令牌才会被采样。这个参数可以用来控制生成过程中令牌的选择。
eta_cutoff (浮点数,可选,默认为 0.0):
eta 采样是一种局部典型采样和 epsilon 采样的混合。如果设置为在 0 和 1 之间的浮点数,那么一个令牌只有在它大于 eta_cutoff 或 sqrt(eta_cutoff) * exp(-entropy(softmax(next_token_logits))) 时才会被考虑。后者直观上是预期下一个令牌概率,乘以 sqrt(eta_cutoff)。有关更多详细信息,请参阅 Truncation Sampling as Language Model Desmoothing。
diversity_penalty (浮点数,可选,默认为 0.0):
如果生成的某个时间点的令牌与同一组其他束的令牌相同,将从束的分数中减去 diversity_penalty。请注意,只有当 group beam search 启用时,diversity_penalty 才有效。
repetition_penalty (浮点数,可选,默认为 1.0):
重复惩罚参数。1.0 表示没有惩罚。有关更多详细信息,请参阅 this paper。
encoder_repetition_penalty (浮点数,可选,默认为 1.0):
编码器重复惩罚参数。对不是原始输入中的序列施加指数惩罚。1.0 表示没有惩罚。
length_penalty (浮点数,可选,默认为 1.0):
用于基于束生成的指数惩罚。它作为序列长度的指数使用,进而用于除以序列的分数。因为分数是序列的对数似然(即负数),所以 length_penalty > 0.0 促进较长序列,而 length_penalty < 0.0 鼓励较短序列。
no_repeat_ngram_size (整数,可选,默认为 0):
如果设置大于 0,那么在生成过程中,不会重复任何长度为 no_repeat_ngram_size 的 n-gram。这个参数主要用于控制生成文本的多样性,避免重复的 n-gram 导致生成的文本过于单一。
bad_words_ids:一个列表,包含不允许生成的 token ID。如果你想获取不应该出现在生成文本中的单词的 token ID,可以使用 tokenizer(bad_words, add_prefix_space=True, add_special_tokens=False).input_ids。
force_words_ids:一个列表,包含必须生成的 token ID。如果给出的是一个 List[List[int]],那么它被视为一个简单的必须包含的单词列表,与 bad_words_ids 相反。如果给出的是一个 List[List[List[int]]],则会触发一个 析构约束,其中可以允许每个单词的不同形式。
renormalize_logits:一个布尔值,表示是否在应用所有 logits 处理器或 warpers(包括自定义的)后归一化 logits。建议将此标志设置为 True,因为搜索算法假定分数 logits 是归一化的,但一些 logits 处理器或 warpers 会破坏归一化。
constraints:一个包含自定义约束的列表,可以添加到生成中,以确保输出在最合适的方式包含由 Constraint 对象定义的某些 token。
forced_bos_token_id:一个整数,表示在 decoder_start_token_id 之后强制生成的第一个 token 的 ID。这对于多语言模型(如 mBART)很有用,因为第一个生成的 token 应该是目标语言的 token。
forced_eos_token_id:当达到 max_length 时强制生成的最后一个 token 的 ID。可以使用一个列表来设置多个 end-of-sequence token。
remove_invalid_values:一个布尔值,表示是否移除模型可能产生的 nan 和 inf 输出,以防止生成方法崩溃。需要注意的是,使用 remove_invalid_values 可能会降低生成速度。
exponential_decay_length_penalty:一个元组,用于在生成一定数量的 token 后添加一个指数增长的长度惩罚。元组应该是 (start_index, decay_factor) 的形式,其中 start_index 表示惩罚开始的位置,decay_factor 表示指数衰减因子。
suppress_tokens:一个列表,包含在生成过程中将被抑制的 token。SupressTokens logit 处理器会将这些 token 的 log 概率设置为 -inf,以便它们不会被采样。
begin_suppress_tokens:一个列表,包含在生成开始时将被抑制的 token。SupressBeginTokens logit 处理器会将这些 token 的 log 概率设置为 -inf,以便它们不会被采样。文章来源:https://www.toymoban.com/news/detail-706914.html
forced_decoder_ids:一个列表,包含表示生成索引和 token 索引映射的整数对。例如,[[1, 123]] 表示第二个生成的 token 总是索引为 123 的 token。文章来源地址https://www.toymoban.com/news/detail-706914.html
到了这里,关于【nlp-with-transformers】|Transformers中的generate函数解析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!