目录
一、分布式计算
二、分布式资源调度
2.1 什么是分布式资源调度
2.2 yarn的架构
2.2.1 核心架构
2.2.2 辅助架构
前面我们提到了Hadoop的三大核心功能:分布式存储、分布式计算和资源调度,分别由Hadoop的三大核心组件可以担任。
即HDFS是分布式存储组件,MapReduce是分布式计算组件,Yarn则是资源调度组件。
本章我们就分布式计算和资源调度进行简单讲解。
一、分布式计算
那么什么是分布式计算呢?
以前我们开发过程中,要进行计算通常都是在一台电脑上完成的。这从某种意义上说,计算的数据量不算特别大。单台机器能够胜任。
但是假如现在有一个1PB的数据需要进行计算,那么单台机器能完成吗?先不说存储的事情,就算能完成,拿现在最强性能的cpu,那也要计算到猴年马月了。
所以单台不够,我们就多台机器同时计算,这就衍生出了分布式计算。
分布式计算的两种模式
分散汇总模式
1. 将数据分片,多台服务器各自负责一部分数据处理
2. 然后将各自的结果,进行汇总处理
3. 最终得到想要的计算结果

中心调度->步骤执行模式
中心调度、步骤执行模式
1. 由一个节点作为中心调度管理者
2. 将任务划分为几个具体步骤
3. 管理者安排每个机器执行任务
4. 最终得到结果数据

中心调度->步骤执行模式
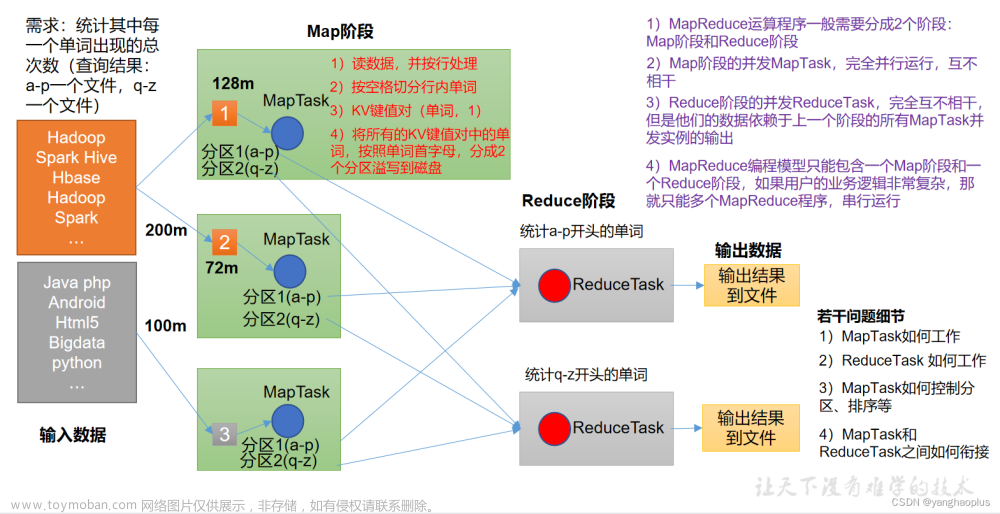
MapReduce
MapReduce是“分散->汇总”模式的分布式计算框架,可供开发人员开发相关程序进行分布式数据计算。
MapReduce提供了2个编程接口:Map和Reduce
Map功能接口提供了“分散”的功能, 由服务器分布式对数据进行处理
Reduce功能接口提供了“汇总(聚合)”的功能,将分布式的处理结果汇总统计
用户如需使用MapReduce框架完成自定义需求的程序开发。只需要使用Java、Python等编程语言,实现Map Reduce功能接口即可。
注:MapReduce尽管可以通过Java、Python等语言进行程序开发,但当下年代基本没人会写它的代码了,因为太过时了。 尽管MapReduce很老了,但现在仍旧活跃在一线,主要是Apache Hive框架非常火,而Hive底层就是使用的MapReduce。 所以对于MapReduce的代码开发,课程会简单扩展一下,但不会深入讲解,对MapReduce的底层原理会放在Hive之后,基于Hive做深入分析。
MapReduce的运行机制:
- 将要执行的需求,分解为多个Map Task和Reduce Task
- 将Map Task 和 Reduce Task分配到对应的服务器去执行
二、分布式资源调度
MapReduce是基于YARN运行的,即没有YARN”无法”运行MapReduce程序。
这里“无法”是加了引号的,这是因为绝大多数的场景都是通过yarn运行MapReduce任务的,不是说没有yarn完全不行,而是非常不方便。离开了它需要我们自行管理资源,自行管理就显得麻烦了。所以95%以上的用户都会选择使用YARN运行MapReduce任务。
2.1 什么是分布式资源调度
那么Yarn作为分布式资源调度组件,它具体有啥作用呢?换句话说什么是资源调度? 我们为什么需要资源调度?

服务器会运行多个程序, 每个程序对资源(CPU内存等)的使用都不同
程序没有节省的概念,有多少就会用多少。
所以,为了提高资源利用率,进行调度就非常有必要了。
YARN 管控整个集群的资源进行调度, 那么应用程序在运行时,就是在YARN的监管(管理)下去运行的。
这就像:全部资源都是公司(YARN)的,由公司分配给个人(具体的程序)去使用。比如,一个具体的MapReduce程序。 我们知道, MapReduce程序会将任务分解为若干个Map任务和Reduce任务。假设,有一个MapReduce程序, 分解了3个Map任务,和1个Reduce任务,那么如何在YARN的监管(管理)下运行呢?
我们直接看下面的动图:

2.2 yarn的架构
yarn分为核心架构和辅助架构
2.2.1 核心架构
类比于HDFS:
HDFS, 主从架构,有2个角色
- 主(Master)角色:NameNode
- 从(Slave)角色 :DataNode
YARN,主从架构,有2个角色
- 主(Master)角色:ResourceManager
- 从(Slave) 角色:NodeManager

ResourceManager:整个集群的资源调度者, 负责协调调度各个程序所需的资源
NodeManager:单个服务器的资源调度者,负责调度单个服务器上的资源提供给应用程序使用。

如何实现服务器上精准分配如下的硬件资源呢?
答:开辟的空间,称之为:容器


2.2.2 辅助架构
Yarn的架构中处理核心角色,ResourceManager和NodeManager外,还可以搭配2个辅助角色使得YARN集群运行更加稳定。
代理服务器(ProxyServer):Web Application Proxy Web应用程序代理
历史服务器(JobHistoryServer): 应用程序历史信息记录服务
代理服务器
代理服务器,即Web应用代理是 YARN 的一部分。默认情况下,它将作为资源管理器(RM)的一部分运行,但是可以配置为在独立模式下运行。使用代理的原因是为了减少通过 YARN 进行基于网络的攻击的可能性。
这是因为, YARN在运行时会提供一个WEB UI站点(同HDFS的WEB UI站点一样)可供用户在浏览器内查看YARN的运行信息。

对外提供WEB 站点会有安全性问题, 而代理服务器的功能就是最大限度保障对WEB UI的访问是安全的。
比如:
- 警告用户正在访问一个不受信任的站点
- 剥离用户访问的Cookie等
- 开启代理服务器,可以提高YARN在开放网络中的安全性 (但不是绝对安全只能是辅助提高一些)
代理服务器默认集成在了ResourceManager中
也可以将其分离出来单独启动,如果要分离代理服务器
1. 在yarn-site.xml中配置 yarn.web-proxy.address 参数即可 (部署环节会使用到)

2. 并通过命令启动它即可 $HADOOP_YARN_HOME/sbin/yarn-daemon.sh start proxyserver(部署环节会使用到)
历史服务器
历史服务器的功能很简单: 记录历史运行的程序的信息以及产生的日志并提供WEB UI站点供用户使用浏览器查看。
程序看日志不是日常操作吗? 为何需要一个单独的历史服务器?
回答这个问题要从YARN的运行机制说起。

 文章来源:https://www.toymoban.com/news/detail-707453.html
文章来源:https://www.toymoban.com/news/detail-707453.html
具体如何使用,我们将在下一章节(yarn部署)讲解。✨文章来源地址https://www.toymoban.com/news/detail-707453.html
到了这里,关于大数据技术之Hadoop:MapReduce与Yarn概述(六)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![【Hadoop】- MapReduce概述[5]](https://imgs.yssmx.com/Uploads/2024/04/857929-1.png)