1. Redis的数据结构有哪些
1. 字符串(String):
字符串是Redis最基本的数据结构。它可以存储任意类型的数据,包括文本、整数或二进制数据。字符串类型的值最大可以达到512MB。
SET name "John" GET name ``` 将字符串"John"存储在键名为"name"的字符串类型数据结构中,并通过GET命令获取它。
2. 列表(List):
列表是一个有序的字符串集合。它允许在列表的两端进行元素的插入和删除操作,支持按照索引获取元素,还提供了一些其他操作如获取子列表、插入元素等。
LPUSH fruits "apple" LPUSH fruits "banana" LRANGE fruits 0 -1 ``` 使用LPUSH命令将"apple"和"banana"两个字符串插入名为"fruits"的列表中,然后使用LRANGE命令获取整个列表的元素。
3. 集合(Set):
集合是一个无序的、唯一的元素集合。它支持添加、删除和检查元素的操作,还提供了集合的并、交、差等操作。
SADD tags "redis" SADD tags "database" SMEMBERS tags ``` 使用SADD命令将"redis"和"database"两个字符串添加到名为"tags"的集合中,并使用SMEMBERS命令获取集合中的所有元素。
4. 有序集合(Sorted Set):
有序集合是一个有序的、唯一的元素集合。每个元素都会关联一个分数(score),用于排序。可以对有序集合中的元素按照分数范围或成员进行查询。
ZADD leaderboard 1000 "player1" ZADD leaderboard 800 "player2" ZRANGE leaderboard 0 -1 WITHSCORES ``` 使用ZADD命令将"player1"和"player2"两个玩家以分数1000和800的形式添加到名为"leaderboard"的有序集合中,并使用ZRANGE命令按照分数范围获取有序集合中的所有元素及其分数。
5. 哈希(Hash):
哈希是一个键值对集合。在Redis中,每个哈希可以存储多个字段和对应的值。哈希适用于存储对象,可以像操作数据库中的行一样对哈希进行存取操作。
HSET user:id1 name "Alice" HSET user:id1 age 25 HGETALL user:id1 ``` 使用HSET命令将"name"字段设为"Alice"、"age"字段设为25,并使用HGETALL命令获取名为"user:id1"的哈希中的所有字段和对应的值。
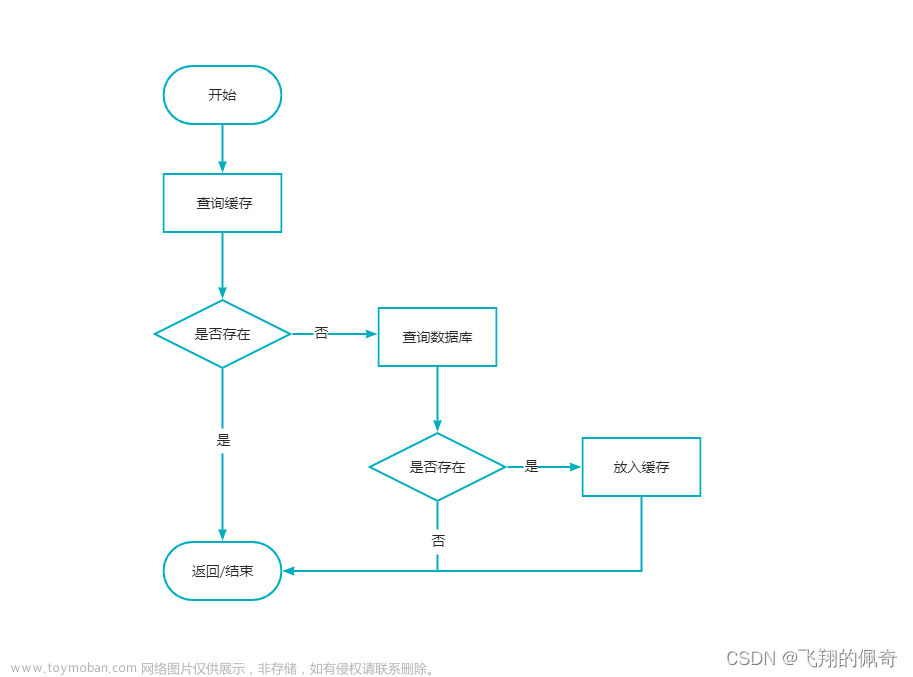
2. Redis 中的缓存雪崩,击穿,穿透是什么
缓存雪崩(Cache Avalanche):
缓存雪崩指的是在某个时间点,缓存中大量的数据同时过期或失效,导致大量的请求直接访问后端数据库。这会导致数据库负载突然增加,引起数据库性能问题,甚至导致数据库崩溃。
原因:
缓存数据设置了相同的过期时间,一旦这些数据同时过期,会导致大量请求直接访问数据库。
缓存服务器宕机或发生故障,无法提供缓存服务。
解决方案:
为缓存数据设置随机的过期时间,避免同时失效。
使用多级缓存架构,如热点数据预热、使用本地缓存等。
监控缓存的健康状况,及时发现故障并修复。
2. 缓存击穿(Cache Breakdown):
缓存击穿指的是某个热点数据失效时,恰好有大量并发请求同时访问该数据,导致请求直接访问数据库。与缓存雪崩不同的是,缓存击穿只是某个特定的数据失效,而不是所有的缓存数据。
原因:
热点数据失效,导致并发请求直接访问数据库。
恶意请求或异常情况,针对某个特定的缓存数据进行大量请求。
解决方案:
使用互斥锁或分布式锁来控制并发请求,只有一个请求能够重新生成缓存数据。
提前异步更新缓存,避免数据失效时的并发请求。
3. 缓存穿透(Cache Penetration):
缓存穿透指的是请求访问一个不存在于缓存中的数据,由于缓存无法命中,请求直接访问后端数据库。这可能是恶意请求或者查询不存在的数据。
原因:
恶意请求:攻击者故意发送大量的请求,查询不存在的数据,以此来对系统造成压力。
查询不存在的数据:应用程序中未对请求的数据进行有效的校验,导致查询不存在的数据。
解决方案:
使用布隆过滤器(Bloom Filter)等技术来过滤掉不存在的数据请求。
对请求的数据进行有效的校验,如校验请求的参数、ID等,避免查询不存在的数据。
3. 数据库的存储过程是什么
存储过程是一种非常有用的工具。它是一组预定义的数据库操作步骤,被封装在一个可重复使用的单元中,以便在需要时被调用执行。存储过程通常由SQL语句和控制结构(例如条件语句和循环)组成,可以接受输入参数并返回结果。
存储过程的设计思想类似于我们平时做的烹饪食谱。假设你想要做一道红烧肉,你可以编写一个详细的步骤清单,列出从准备食材到最后上桌的所有步骤。每次你想要做红烧肉时,只需按照清单上的步骤逐一执行即可。
在数据库中,存储过程的作用类似于这个烹饪食谱。它允许你定义一个包含一系列数据库操作的过程,例如插入、更新、删除或查询数据。一旦你定义了存储过程,你可以通过简单地调用存储过程的名称来执行其中的操作。
CREATE PROCEDURE GetUsersByAge
@Age INT
AS
BEGIN
SELECT Name, Age, Email
FROM Users
WHERE Age = @Age
END
在上面的代码中,我们首先使用CREATE PROCEDURE语句创建了一个名为"GetUsersByAge"的存储过程。它接受一个@Age参数,用于指定要查询的年龄。
在存储过程的主体部分,我们使用SELECT语句从"Users"表中选择满足指定年龄的用户信息,并将结果返回。
完成后,我们可以通过以下方式调用这个存储过程:
EXEC GetUsersByAge @Age = 25
4. 视图和表的区别
表是数据库中的实际对象,用于存储和组织数据,而视图是基于一个或多个表的查询结果构建而成的虚拟表。表存储了实际的数据,而视图仅存储了查询定义。
表可以直接进行数据的增删改查操作,而视图提供了对数据的抽象视图,可以进行筛选、排序、连接等操作,并以表的形式返回结果。此外,
视图还提供了更细粒度的数据安全性和权限控制。
5. count(*) 和count(1) 的区别
COUNT(*)是一种通用的写法,它用于计算满足条件的所有行的数量,包括那些具有NULL值的行。它会对表中的每一行进行计数,不考虑具体的列值。因此,COUNT(*)会扫描整个表,并返回表中的总行数。
COUNT(1)是一种优化的写法,它通过使用常量值1来进行计数。因为每一行都存在一个常量值1,所以COUNT(1)实际上是对每一行进行计数。与COUNT(*)相比,使用COUNT(1)可以稍微提高一点性能,因为它不会关心具体的列值或NULL值,只需简单地计算行的数量。
尽管在大多数情况下,COUNT(*)和COUNT(1)的效果是相同的,但在某些特定数据库中,优化器可能对它们进行不同的优化处理,可能会有微小的性能差异。
6. 索引和主键的区别
索引是一种用于提高数据库查询性能的数据结构,它可以加速数据的定位和访问。主键是一种用于标识表中唯一记录的约束,它保证表中每行的唯一性和非空性。索引可以是唯一或非唯一文章来源:https://www.toymoban.com/news/detail-707994.html
的,而主键是一种特殊的唯一索引。索引和主键在数据库中起着不同的作用,并且可以根据具体需求和查询优化的需要来选择使用。文章来源地址https://www.toymoban.com/news/detail-707994.html
到了这里,关于数据库基础面试第四弹的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![java八股文面试[数据库]——MySQL索引的数据结构](https://imgs.yssmx.com/Uploads/2024/02/685933-1.png)