🍋引言
在机器学习模型中,过拟合和欠拟合是两种常见的问题。它们在模型训练和预测过程中扮演着重要的角色。了解过拟合和欠拟合的概念、影响、解决方法以及研究现状和趋势,对于提高机器学习模型性能和实用性具有重要意义。
🍋过拟合和欠拟合的概念
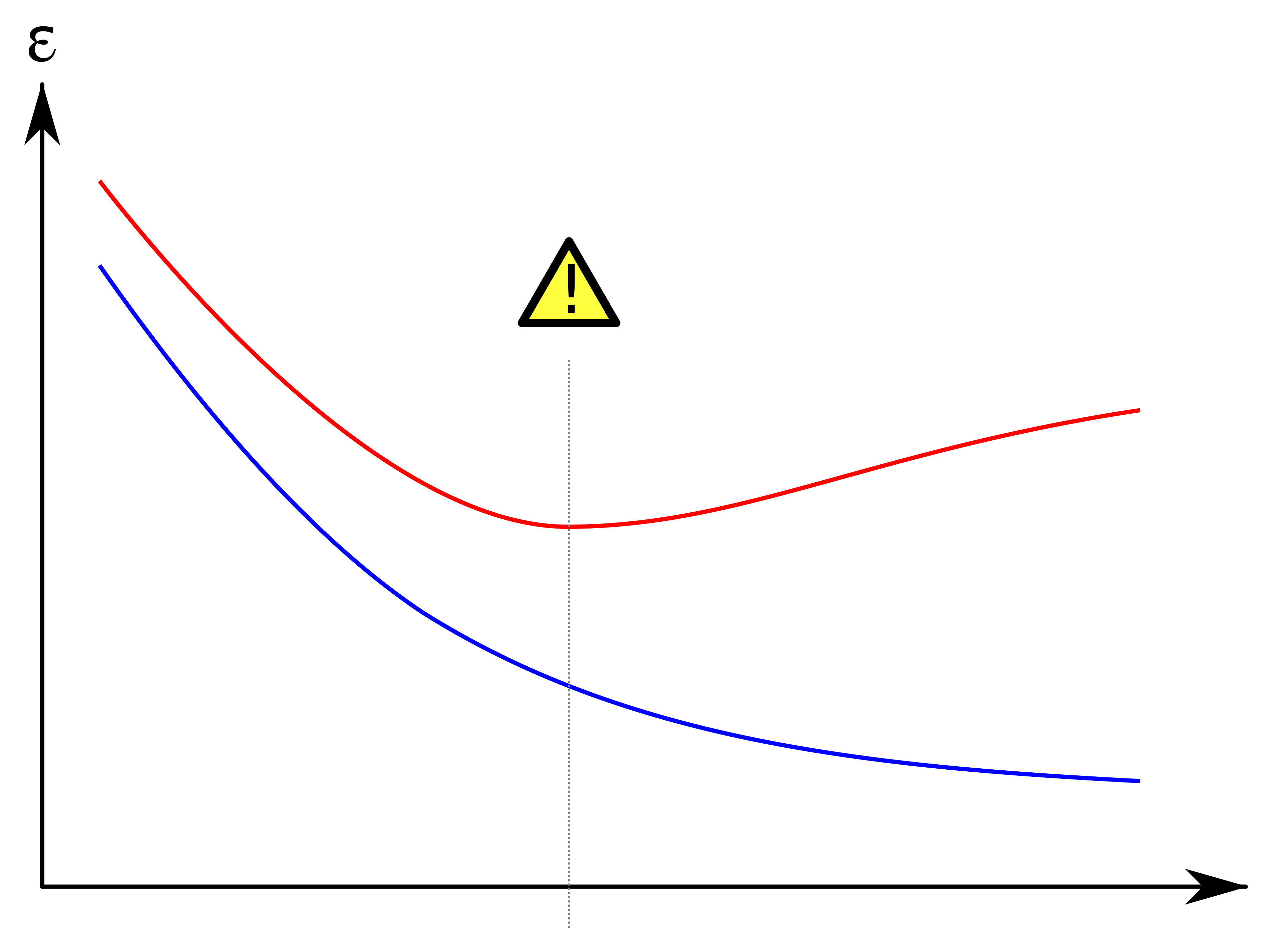
过拟合是指机器学习模型在训练数据上表现优良,但在测试数据上表现较差的现象。这意味着模型在训练数据集上学习了过多的特定细节,以至于在新的、未见过的数据上无法泛化。
相反,欠拟合是指机器学习模型在训练数据上和测试数据上都表现较差的现象。这意味着模型没有足够的学习能力来捕捉数据中的关键特征和模式。
🍋过拟合和欠拟合的影响与危害
过拟合和欠拟合都会对机器学习模型的性能产生负面影响。过拟合会导致模型在测试数据上的性能下降,使得模型无法泛化到实际应用场景。欠拟合则会使模型在训练数据上和测试数据上的性能都较差,无法准确预测新数据的标签或类别。
此外,过拟合和欠拟合还可能使模型对新数据的适应能力下降,导致在实际应用中效果不佳。因此,了解如何避免过拟合和欠拟合对于提高机器学习模型的性能至关重要。
🍋过拟合和欠拟合的原因与解决方法
过拟合和欠拟合的原因各不相同,但都与模型的复杂度和训练数据的量有关。过拟合通常由于模型复杂度过高,导致在训练数据上过度拟合,无法泛化到测试数据。解决方法包括简化模型、增加数据量、使用正则化方法等。
欠拟合则通常由于模型复杂度过低,无法捕捉到数据中的关键特征和模式。解决方法包括增加模型复杂度、使用集成学习方法、改进特征工程等。
🍋过拟合和欠拟合的研究现状与发展趋势
过拟合和欠拟合作为机器学习领域的重要研究课题,已经得到了广泛的关注和研究。目前,研究者们正在不断探索新的方法和技术来解决这些问题。
在未来,过拟合和欠拟合的研究将更加深入。一方面,研究者们将尝试开发更加高效的正则化方法和集成学习算法,以进一步提高模型的泛化能力和性能。另一方面,随着深度学习等新型算法的不断发展,如何将其应用于解决过拟合和欠拟合问题也将成为研究的重要方向。
🍋过拟合&欠拟合—案例
我们围绕上篇多项式回归,来介绍一下过拟合和欠拟合的案例
上篇其实已经展示了欠拟合
欠拟合比较好整,可以用多种方式提高模型的准确率,但是过拟合呢,下面我来简单介绍一下
首先导入一些必要的库
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import PolynomialFeatures
然后我们还是准备之前的数据,这里我们设置了一个随机种子,保证大家的数据一致性,方便检阅
x = np.random.uniform(-3,3,size=100)
X = x.reshape(-1,1)
np.random.seed(666)
y = 0.5*x**2+x+3+np.random.normal(0,1,size=100)
X_train,X_test,y_train,y_test = train_test_split(X,y)
接下来我们定义两个函数polynomialRegression和plot_model,下面我一一解释
首先是polynomialRegression函数,其实就是之前的管道,它可以将输入数据转换为指定的多项式次数,然后对其进行标准化,并最后拟合一个线性回归模型
def polynomialRegression(degree):
return Pipeline([
('poly',PolynomialFeatures(degree=degree)),
('std_scaler',StandardScaler()),
('lin_reg',LinearRegression())
])
再创建一个plot_model函数,用来进行绘制
def plot_model(poly_reg):
y_predict = poly_reg.predict(X)
plt.scatter(X,y)
plt.plot(np.sort(x),y_predict[np.argsort(x)],color='r')
plt.show()
我们接受训练好的模型poly_reg。这里的np.argsort(x)返回的是x排序后的索引,因此y_predict[np.argsort(x)]可以得到排序后的预测值。
接下来我们分别使用二次、十次、五十次、一百次多项式进行拟合数据
poly_reg = polynomialRegression(2)
poly_reg.fit(X,y)
y_predict = poly_reg.predict(X)
print(mean_squared_error(y,y_predict))
plot_model(poly_reg)
运行结果如下
poly_reg = polynomialRegression(10)
poly_reg.fit(X,y)
y_predict = poly_reg.predict(X)
print(mean_squared_error(y,y_predict))
plot_model(poly_reg)
运行结果如下
poly_reg = polynomialRegression(50)
poly_reg.fit(X,y)
y_predict = poly_reg.predict(X)
print(mean_squared_error(y,y_predict))
plot_model(poly_reg)
运行结果如下
poly_reg = polynomialRegression(100)
poly_reg.fit(X,y)
y_predict = poly_reg.predict(X)
print(mean_squared_error(y,y_predict))
plot_model(poly_reg)
运行结果如下
我们不难看出,目的为了拟合所有的特征点,导致模型变得过于复杂,这种情况就叫过拟合
接下来我们将训练好的模型进行预测并绘制(这里使用的是一百次)
x_plot = np.linspace(-3,3,100).reshape(100,1)
y_plot = poly_reg.predict(x_plot)
plt.scatter(x,y)
plt.plot(x_plot,y_plot,color='r')
plt.axis([-3,3,-1,10])
plt.show()
运行结果如下
可以看出很糟糕,这就是过拟合带来的后果。就像识别一只猫和一只狗,过拟合会导致猫换个色就识别不出来是猫了,欠拟合则会阴差阳错的将猫识别为狗
🍋总结
过拟合和欠拟合是机器学习过程中的两个重要概念,对于提高模型的性能和实用性具有重要意义。了解过拟合和欠拟合的概念、影响、解决方法以及研究现状和发展趋势,有助于我们在实际应用中更好地应对和解决这些问题。
未来,过拟合和欠拟合的研究将继续深入发展,研究者们将不断探索新的方法和技术以解决这些问题。随着机器学习技术的广泛应用,过拟合和欠拟合的研究也将具有更加实际的应用价值。 文章来源:https://www.toymoban.com/news/detail-709062.html
文章来源:https://www.toymoban.com/news/detail-709062.html
挑战与创造都是很痛苦的,但是很充实。文章来源地址https://www.toymoban.com/news/detail-709062.html
到了这里,关于过拟合和欠拟合:机器学习模型中的两个重要概念的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!