Kafka 连接器提供从 Kafka topic 中消费和写入数据的能力。
前面已经介绍了flink sql创建表的语法及说明:【flink sql】创建表
这篇博客聊聊怎么通过flink sql连接kafka
创建kafka表示例
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = 'master.fuyun:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
)
kafka中可用的元数据
以下的连接器元数据可以在表定义中通过元数据列的形式获取。
R/W 列定义了一个元数据是可读的(R)还是可写的(W)。 只读列必须声明为 VIRTUAL 以在 INSERT INTO 操作中排除它们。
| 键 | 数据类型 | 描述 | R/W |
|---|---|---|---|
| topic | STRING NOT NULL | Kafka 记录的 Topic 名。 | R |
| partition | INT NOT NULL | Kafka 记录的 partition ID。 | R |
| headers | MAP NOT NULL | 二进制 Map 类型的 Kafka 记录头(Header)。 | R/W |
| leader-epoch | INT NULL | Kafka 记录的 Leader epoch(如果可用)。 | R |
| offset | BIGINT NOT NULL | Kafka 记录在 partition 中的 offset。 | R |
| timestamp | TIMESTAMP_LTZ(3) NOT NULL | Kafka 记录的时间戳。 | R/W |
| timestamp-type | STRING NOT NULL | Kafka 记录的时间戳类型。可能的类型有 “NoTimestampType”, “CreateTime”(会在写入元数据时设置),或 “LogAppendTime”。 | R |
以下扩展的 CREATE TABLE 示例展示了使用这些元数据字段的语法:
CREATE TABLE KafkaTable (
`event_time` TIMESTAMP(3) METADATA FROM 'timestamp',
`partition` BIGINT METADATA VIRTUAL, -- 可以省略 from ......
`offset` BIGINT METADATA VIRTUAL,
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = 'master.fuyun:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
);
如果元数据名称和字段名称是一致的,可以省略 from ......
格式元信息
连接器可以读出消息格式的元数据。格式元数据的配置键以 ‘value.’ 作为前缀。
以下示例展示了如何获取 Kafka 和 Debezium 的元数据字段:
CREATE TABLE KafkaTable (
`event_time` TIMESTAMP(3) METADATA FROM 'value.source.timestamp' VIRTUAL, -- from Debezium format
`origin_table` STRING METADATA FROM 'value.source.table' VIRTUAL, -- from Debezium format
`partition_id` BIGINT METADATA FROM 'partition' VIRTUAL, -- from Kafka connector
`offset` BIGINT METADATA VIRTUAL, -- from Kafka connector
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = 'master.fuyun:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'value.format' = 'debezium-json'
);
连接器参数
| 参数 | 是否必选 | 默认值 | 数据类型 | 描述 |
|---|---|---|---|---|
| connector | 必选 | (无) | String | 指定使用的连接器,Kafka 连接器使用 ‘kafka’。 |
| topic | required for sink | (无) | String | 当表用作 source 时读取数据的 topic 名。亦支持用分号间隔的 topic 列表,如 ‘topic-1;topic-2’。注意,对 source 表而言,‘topic’ 和 ‘topic-pattern’ 两个选项只能使用其中一个。当表被用作 sink 时,该配置表示写入的 topic 名。注意 sink 表不支持 topic 列表。 |
| topic-pattern | 可选 | (无) | String | 匹配读取 topic 名称的正则表达式。在作业开始运行时,所有匹配该正则表达式的 topic 都将被 Kafka consumer 订阅。注意,对 source 表而言,‘topic’ 和 ‘topic-pattern’ 两个选项只能使用其中一个。 |
| properties.bootstrap.servers | 必选 | (无) | String | 逗号分隔的 Kafka broker 列表。 |
| properties.group.id | required by source | (无) | String | Kafka source 的 consumer 组 id,对于 Kafka sink 可选填。 |
| properties.* | 可选 | (无) | String | 可以设置和传递任意 Kafka 的配置项。后缀名必须匹配在 Kafka 配置文档 中定义的配置键。Flink 将移除 “properties.” 配置键前缀并将变换后的配置键和值传入底层的 Kafka 客户端。例如,你可以通过 ‘properties.allow.auto.create.topics’ = ‘false’ 来禁用 topic 的自动创建。但是某些配置项不支持进行配置,因为 Flink 会覆盖这些配置,例如 ‘key.deserializer’ 和 ‘value.deserializer’。 |
| format | 必选 | (无) | String | 用来序列化或反序列化 Kafka 消息的格式。 请参阅 格式 页面以获取更多关于格式的细节和相关配置项。 注意:该配置项和 ‘value.format’ 二者必需其一。 |
| key.format | 可选 | (无) | String | 用来序列化和反序列化 Kafka 消息键(Key)的格式。 请参阅 格式 页面以获取更多关于格式的细节和相关配置项。 注意:如果定义了键格式,则配置项 ‘key.fields’ 也是必需的。 否则 Kafka 记录将使用空值作为键。 |
| key.fields | 可选 | [] | List | 表结构中用来配置消息键(Key)格式数据类型的字段列表。默认情况下该列表为空,因此消息键没有定义。 列表格式为 ‘field1;field2’。 |
| key.fields-prefix | 可选 | (无) | String | 为所有消息键(Key)格式字段指定自定义前缀,以避免与消息体(Value)格式字段重名。默认情况下前缀为空。 如果定义了前缀,表结构和配置项 ‘key.fields’ 都需要使用带前缀的名称。 当构建消息键格式字段时,前缀会被移除,消息键格式将会使用无前缀的名称。 请注意该配置项要求必须将 ‘value.fields-include’ 配置为 ‘EXCEPT_KEY’。 |
| value.format | 必选 | (无) | String | 序列化和反序列化 Kafka 消息体时使用的格式。 请参阅 格式 页面以获取更多关于格式的细节和相关配置项。 注意:该配置项和 ‘format’ 二者必需其一。 |
| value.fields-include | 可选 | ALL | 枚举类型 可选值:[ALL, EXCEPT_KEY] | 定义消息体(Value)格式如何处理消息键(Key)字段的策略。 默认情况下,表结构中 ‘ALL’ 即所有的字段都会包含在消息体格式中,即消息键字段在消息键和消息体格式中都会出现。 |
| scan.startup.mode | 可选 | group-offsets | String | Kafka consumer 的启动模式。有效值为:‘earliest-offset’,‘latest-offset’,‘group-offsets’,‘timestamp’ 和 ‘specific-offsets’。 请参阅下方 起始消费位点 以获取更多细节。 |
| scan.startup.specific-offsets | 可选 | (无) | String | 在使用 ‘specific-offsets’ 启动模式时为每个 partition 指定 offset,例如 ‘partition:0,offset:42;partition:1,offset:300’。 |
| scan.startup.timestamp-millis | 可选 | (无) | Long | 在使用 ‘timestamp’ 启动模式时指定启动的时间戳(单位毫秒)。 |
| scan.topic-partition-discovery.interval | 可选 | (无) | Duration | Consumer 定期探测动态创建的 Kafka topic 和 partition 的时间间隔。 |
| sink.partitioner | 可选 | ‘default’ | String | Flink partition 到 Kafka partition 的分区映射关系,可选值有: default:使用 Kafka 默认的分区器对消息进行分区。 fixed:每个 Flink partition 最终对应最多一个 Kafka partition。 round-robin:Flink partition 按轮循(round-robin)的模式对应到 Kafka partition。只有当未指定消息的消息键时生效。 自定义 FlinkKafkaPartitioner 的子类:例如 ‘org.mycompany.MyPartitioner’。 |
| sink.semantic | 可选 | at-least-once | String | 定义 Kafka sink 的语义。有效值为 ‘at-least-once’,‘exactly-once’ 和 ‘none’。请参阅下方 一致性保证 以获取更多细节。 |
| sink.parallelism | 可选 | (无) | Integer | 定义 Kafka sink 算子的并行度。默认情况下,并行度由框架定义为与上游串联的算子相同。 |
特性
消息键(Key)与消息体(Value)的格式
Kafka 消息的消息键和消息体部分都可以使用某种 格式 来序列化或反序列化成二进制数据。
消息体格式
CREATE TABLE KafkaTable (,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp',
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING
) WITH (
'connector' = 'kafka',
...
'format' = 'json',
'json.ignore-parse-errors' = 'true'
)
消息体格式将配置为以下的数据类型:
ROW<`user_id` BIGINT, `item_id` BIGINT, `behavior` STRING>
消息键和消息体格式
以下示例展示了如何配置和使用消息键和消息体格式。 格式配置使用 ‘key’ 或 ‘value’ 加上格式识别符作为前缀。
CREATE TABLE KafkaTable (
`ts` TIMESTAMP(3) METADATA FROM 'timestamp',
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING
) WITH (
'connector' = 'kafka',
...
'key.format' = 'json',
'key.json.ignore-parse-errors' = 'true',
'key.fields' = 'user_id;item_id',
'value.format' = 'json',
'value.json.fail-on-missing-field' = 'false',
'value.fields-include' = 'ALL'
)
消息键格式包含了在 ‘key.fields’ 中列出的字段(使用 ‘;’ 分隔)和字段顺序。 因此将配置为以下的数据类型:
ROW<`user_id` BIGINT, `item_id` BIGINT>
由于消息体格式配置为 ‘value.fields-include’ = ‘ALL’,所以消息键字段也会出现在消息体格式的数据类型中:
ROW<`user_id` BIGINT, `item_id` BIGINT, `behavior` STRING>
重名的格式字段
如果消息键字段和消息体字段重名,连接器无法根据表结构信息将这些列区分开。 ‘key.fields-prefix’ 配置项可以在表结构中为消息键字段指定一个唯一名称,并在配置消息键格式的时候保留原名。
以下示例展示了在消息键和消息体中同时包含 version 字段的情况:
CREATE TABLE KafkaTable (
`k_version` INT,
`k_user_id` BIGINT,
`k_item_id` BIGINT,
`version` INT,
`behavior` STRING
) WITH (
'connector' = 'kafka',
...
'key.format' = 'json',
'key.fields-prefix' = 'k_',
'key.fields' = 'k_version;k_user_id;k_item_id',
'value.format' = 'json',
'value.fields-include' = 'EXCEPT_KEY'
)
消息体格式必须配置为 ‘EXCEPT_KEY’ 模式。格式将被配置为以下的数据类型:
消息键格式:
ROW<`version` INT, `user_id` BIGINT, `item_id` BIGINT>
消息体格式:
ROW<`version` INT, `behavior` STRING>
Topic 和 Partition 的探测
topic 和 topic-pattern 配置项决定了 source 消费的 topic 或 topic 的匹配规则。topic 配置项可接受使用分号间隔的 topic 列表,例如 topic-1;topic-2。 topic-pattern配置项使用正则表达式来探测匹配的 topic。例如 topic-pattern设置为 test-topic-[0-9],则在作业启动时,所有匹配该正则表达式的 topic(以 test-topic-开头,以一位数字结尾)都将被 consumer 订阅。
为允许 consumer 在作业启动之后探测到动态创建的 topic,请将 scan.topic-partition-discovery.interval配置为一个非负值。这将使 consumer 能够探测匹配名称规则的 topic 中新的 partition。
注意 topic 列表和 topic 匹配规则只适用于 source。对于 sink 端,Flink 目前只支持单一 topic。
起始消费位点
scan.startup.mode 配置项决定了 Kafka consumer 的启动模式。有效值为:
-
group-offsets:从 Zookeeper/Kafka 中某个指定的消费组已提交的偏移量开始。 -
earliest-offset:从可能的最早偏移量开始。 -
latest-offset:从最末尾偏移量开始。 -
timestamp:从用户为每个 partition 指定的时间戳开始。 -
specific-offsets:从用户为每个 partition 指定的偏移量开始。
默认值group-offsets表示从 Zookeeper/Kafka 中最近一次已提交的偏移量开始消费。
如果使用了 timestamp,必须使用另外一个配置项 scan.startup.timestamp-millis 来指定一个从格林尼治标准时间 1970 年 1 月 1 日 00:00:00.000 开始计算的毫秒单位时间戳作为起始时间。
如果使用了 specific-offsets,必须使用另外一个配置项 scan.startup.specific-offsets 来为每个 partition 指定起始偏移量, 例如,选项值 partition:0,offset:42;partition:1,offset:300 表示 partition 0 从偏移量 42 开始,partition 1 从偏移量 300 开始。
Sink 分区
配置项 sink.partitioner 指定了从 Flink 分区到 Kafka 分区的映射关系。 默认情况下,Flink 使用 Kafka 默认分区器 来对消息分区。默认分区器对没有消息键的消息使用 粘性分区策略(sticky partition strategy) 进行分区,对含有消息键的消息使用 murmur2 哈希算法计算分区。
为了控制数据行到分区的路由,也可以提供一个自定义的 sink 分区器。‘fixed’ 分区器会将同一个 Flink 分区中的消息写入同一个 Kafka 分区,从而减少网络连接的开销。
一致性保证
默认情况下,如果查询在 启用 checkpoint 模式下执行时,Kafka sink 按照至少一次(at-lease-once)语义保证将数据写入到 Kafka topic 中。
当 Flink checkpoint 启用时,kafka 连接器可以提供精确一次(exactly-once)的语义保证。
除了启用 Flink checkpoint,还可以通过传入对应的 sink.semantic 选项来选择三种不同的运行模式:
-
none:Flink 不保证任何语义。已经写出的记录可能会丢失或重复。 -
at-least-once(默认设置):保证没有记录会丢失(但可能会重复)。 -
exactly-once:使用 Kafka 事务提供精确一次(exactly-once)语义。当使用事务向 Kafka 写入数据时,请将所有从 Kafka 中消费记录的应用中的isolation.level配置项设置成实际所需的值(read_committed或read_uncommitted,后者为默认值)。
请参阅 Kafka 文档 以获取更多关于语义保证的信息。
Source 按分区 Watermark
Flink 对于 Kafka 支持发送按分区的 watermark。Watermark 在 Kafka consumer 中生成。 按分区 watermark 的合并方式和在流 shuffle 时合并 Watermark 的方式一致。 Source 输出的 watermark 由读取的分区中最小的 watermark 决定。 如果 topic 中的某些分区闲置,watermark 生成器将不会向前推进。 你可以在表配置中设置 table.exec.source.idle-timeout 选项来避免上述问题。
请参阅 Kafka watermark 策略 以获取更多细节。文章来源:https://www.toymoban.com/news/detail-709574.html
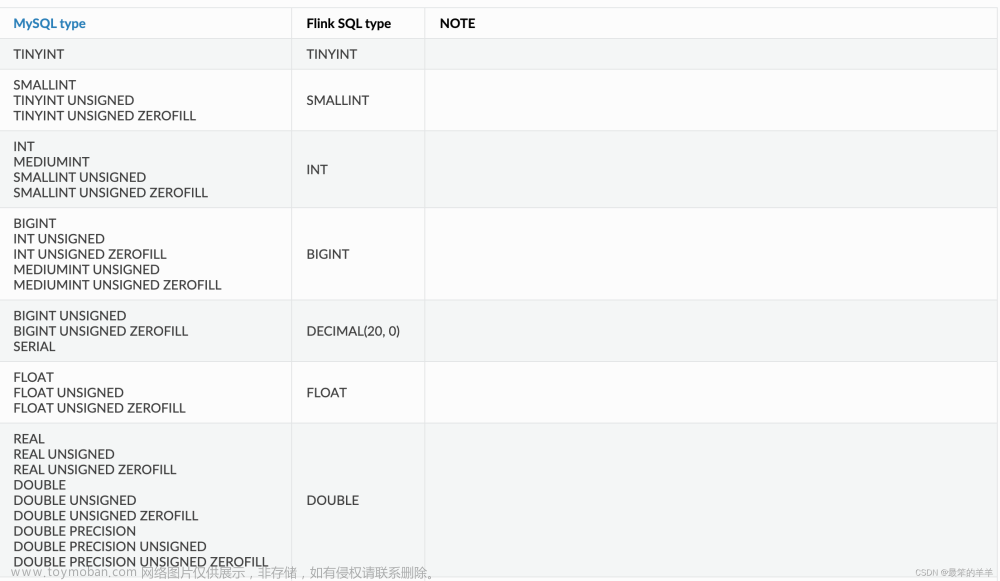
数据类型映射
Kafka 将消息键值以二进制进行存储,因此 Kafka 并不存在 schema 或数据类型。Kafka 消息使用格式配置进行序列化和反序列化,例如 csv,json,avro。 因此,数据类型映射取决于使用的格式。请参阅 格式 页面以获取更多细节。文章来源地址https://www.toymoban.com/news/detail-709574.html
到了这里,关于【flink sql】kafka连接器的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!




![流批一体计算引擎-7-[Flink]的DataStream连接器](https://imgs.yssmx.com/Uploads/2024/01/402531-1.png)



