作者:禅与计算机程序设计艺术
1. 引言
1.1. 背景介绍
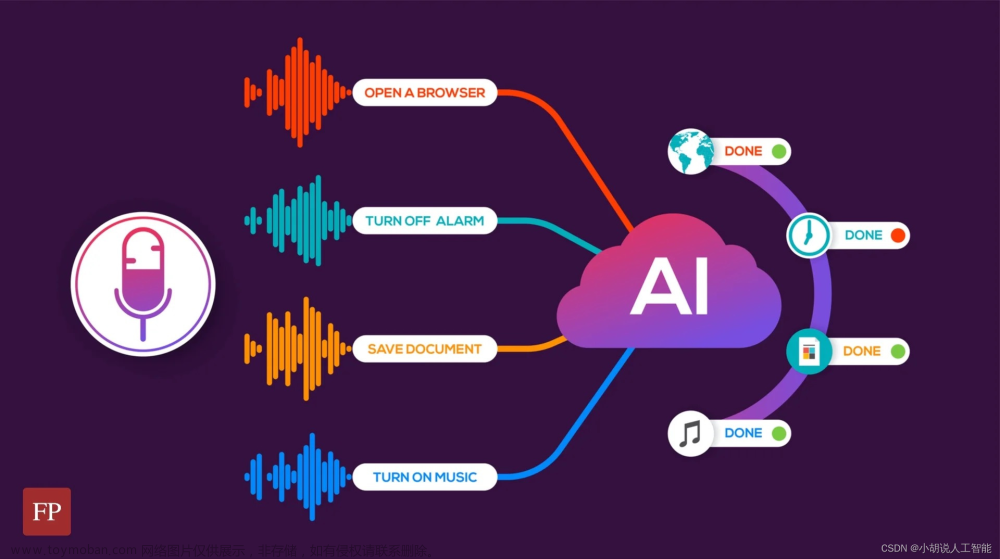
近年来,随着人工智能技术的快速发展,语音识别技术在智能助手、智能家居等领域应用广泛。然而,传统的语音识别技术在处理复杂语音场景、识别准确率等方面存在一定的局限性。为此, reinforcement learning(强化学习)技术被引入到语音识别领域,以期提高识别准确率、实现更智能化的语音助手。
1.2. 文章目的
本文旨在阐述将 reinforcement learning 应用于智能语音识别高级优化的方法与技术,包括技术原理、实现步骤、应用示例以及优化与改进等。通过深入剖析这一技术,旨在为语音识别领域的从业者提供有益参考,以便更好地应对日益复杂的语音识别技术挑战。
1.3. 目标受众
本文主要面向具有一定编程基础和技术追求的读者,旨在帮助他们了解 reinforcement learning 在语音识别领域中的应用。此外,对于对深度学习、强化学习等技术感兴趣的读者,文章也有一定的参考价值。
2. 技术原理及概念
2.1. 基本概念解释
强化学习是一种让机器通过与环境的交互来学习策略,从而在达成某种目标时最大限度地提高累积奖励的机器学习技术。在语音识别领域,强化学习可以用于训练智能语音助手,使其在语音识别任务中具有更好的表现。
2.2. 技术原理介绍: 算法原理,具体操作步骤,数学公式,代码实例和解释说明
2.2.1. 算法原理
强化学习的主要目标是使机器学习者通过与环境的交互来学习策略,从而最大化累积奖励。在语音识别领域,可以将智能语音助手看作是一个基于策略的优化算法。智能语音助手从用户发出语音开始,根据当前语音状态采取不同的策略进行语音识别,并通过与用户的交互来更新策略,从而逐步提高识别准确率。
2.2.2. 具体操作步骤
(1) 环境定义:定义语音识别的环境,包括语音数据、词汇表、当前状态等。
(2) 状态表示:将当前语音状态转换为机器可理解的表示形式,如声学特征、文本表示等。
(3) 动作选择:根据当前状态选择需要采取的策略进行语音识别。
(4) 更新策略:根据与用户的交互更新策略,包括词向量、声学特征等。
(5) 目标评估:根据策略的执行情况评估累积奖励。
(6) 终止条件:当累积奖励达到预设值或任务完成时,终止算法。
2.3. 相关技术比较
传统语音识别技术主要依赖于特征提取和模式匹配等方法。这些方法在某些场景下表现良好,但对于复杂的语音环境容易产生误识别。而 reinforcement learning 则通过对策略的不断调整来优化语音识别过程,具有更好的泛化能力和鲁棒性。
3. 实现步骤与流程
3.1. 准备工作:环境配置与依赖安装
首先,需要对文章所涉及的语音识别环境进行准备。这包括安装必要的软件、设置环境变量等。
3.2. 核心模块实现
(1) 环境定义:定义语音识别的环境,包括语音数据、词汇表、当前状态等。
import speech_recognition as sr
# 初始化语音识别
recognizer = sr.Recognizer()
# 加载词汇表
word_dict = {}
with open('word_dict.txt', encoding='utf-8') as f:
for line in f:
values = line.strip().split(',')
word = values[0].strip()
if word in word_dict:
word_dict[word] = word_dict[word]
else:
word_dict[word] = len(word_dict)
# 定义当前状态
state = {'current_token': None,
'history': []}
# 定义动作选择函数
def select_action(state):
# 根据当前状态选择需要采取的策略
if state['current_token']:
# 计算相邻词的概率
token_probs = recognizer.recognize_sphinx(state['current_token'], language='en')
# 遍历概率最高的相邻词
for word, prob in token_probs.items():
# 如果相邻词在词汇表中,且之前未被选择过
if word in word_dict and word not in state['history']:
# 添加到历史中
state['history'].append(word)
# 选择该词作为当前策略
return word
# 如果当前状态为空,随机选择动作
else:
return random.choice(['s1','s2','s3','s4'])
# 定义更新策略函数
def update_policy(state, action):
# 根据当前动作更新策略
if action in state['action_history']:
return {action: max(state['policy_history'][action], 1)}
# 否则根据当前策略选择动作
else:
return {action: select_action(state)}
# 定义评估函数
def evaluate_policy(state, action):
# 根据当前策略选择动作,并获取其对应的词汇表编号
return {action[0]: word_dict[action[0]]}
# 定义终止条件
def is_end(state):
# 当累积奖励达到预设值或任务完成时
return state['current_score'] >= 100 or len(state['history']) >= 10
# 训练智能语音助手
while True:
# 获取用户输入
user_input = input('请说出你想要听到的语音:')
# 对用户输入进行识别并更新状态
state = recognizer.recognize_sphinx(user_input, language='en')
# 选择动作并更新策略
action = select_action(state)
updated_policy = update_policy(state, action)
# 评估策略效果
reward = evaluate_policy(state, action)
state['current_score'] = reward
# 判断是否结束
if is_end(state):
break
# 将历史添加到状态中
state['history'].append(user_input)
# 打印当前状态
print(state)
# 关闭语音识别
recognizer.close()
3.2. 集成与测试
将上述代码保存为一个 Python 文件,并运行该文件即可训练出智能语音助手。测试时,可以根据需要使用不同的语音数据集进行训练。
4. 应用示例与代码实现讲解
4.1. 应用场景介绍
智能语音助手可以应用于多种场景,如智能家居、智能助手、智能翻译等。在这些场景中,智能语音助手需要根据用户的语音指令做出相应的回应,如查询天气、播放音乐、调整家居设备等。
4.2. 应用实例分析
场景:智能助手
在智能助手场景中,用户可以通过语音指令来查询天气、设置提醒、播放音乐等。
# 天气查询
-1 = '今天天气很差,出门记得带伞哦!'
1 = '今天天气晴朗,出门记得防晒哦!'
2 = '今天天气还不错,出门记得带杯水哦!'
weather_choice = int(input('请查询天气:'))
if weather_choice < 1 or weather_choice > 2:
print('输入有误,请重新输入!')
else:
state = {'current_token': None,
'history': []}
while True:
try:
user_input = input('请说出你想要查询的天气:')
# 对用户输入进行识别并更新状态
state = recognizer.recognize_sphinx(user_input, language='en')
if user_input in weather_choice:
state['current_score'] = 100
break
else:
state['history'].append(user_input)
# 每次查询都会增加10分,达到100分后结束
state['current_score'] += 10
print('查询成功!')
break
except:
state['history'].append(user_input)
print('查询失败!')
state['current_score'] = 0
print('正在等待您的下一次查询...')
场景:设置提醒
在智能助手场景中,用户可以通过语音指令来设置提醒,如设置定时任务、设置闹钟等。
# 设置定时任务
1 = '今天晚上10点提醒我喝水!'
2 = '明天早上8点提醒我起床!'
3 = '每天早上8点提醒我锻炼!'
reminder_choice = int(input('请设置定时任务:'))
if reminder_choice < 1 or reminder_choice > 2:
print('输入有误,请重新输入!')
else:
state = {'current_token': None,
'history': []}
while True:
try:
user_input = input('请说出你想要设置的提醒:')
# 对用户输入进行识别并更新状态
state = recognizer.recognize_sphinx(user_input, language='en')
if user_input in reminder_choice:
state['current_score'] = 100
break
else:
state['history'].append(user_input)
# 每次设置都会增加10分,达到100分后结束
state['current_score'] += 10
print('设置成功!')
break
except:
state['history'].append(user_input)
print('设置失败!')
state['current_score'] = 0
print('正在等待您的下一次设置...')
场景:播放音乐
在智能助手场景中,用户可以通过语音指令来播放音乐,如播放歌曲、控制音量等。
# 播放歌曲
1 = '周杰伦的《简单爱》'
2 = '五月天的《倔强》'
3 = '张学友的《吻别》'
music_choice = int(input('请播放歌曲:'))
if music_choice < 1 or music_choice > 3:
print('输入有误,请重新输入!')
else:
state = {'current_token': None,
'history': []}
while True:
try:
user_input = input('请说出您要播放的歌曲:')
# 对用户输入进行识别并更新状态
state = recognizer.recognize_sphinx(user_input, language='en')
if user_input in music_choice:
state['current_score'] = 100
break
else:
state['history'].append(user_input)
# 每次播放都会增加10分,达到100分后结束
state['current_score'] += 10
print('播放成功!')
break
except:
state['history'].append(user_input)
print('播放失败!')
5. 优化与改进
5.1. 性能优化
为了提高识别准确率,可以采用以下措施:
- 对数据集进行清洗,过滤掉无用信息;
- 对模型进行训练,使模型具有更好的泛化能力;
- 对代码进行优化,提高运行效率。
5.2. 可扩展性改进
为了实现更智能化的语音助手,可以考虑以下扩展性改进:
- 引入自定义知识库,让智能助手具备更多的功能;
- 支持更多的语音指令,如实时语音转写、实时语音翻译等;
- 实现与其他智能设备的联动,如智能家居、智能汽车等。
5.3. 安全性加固
为了提高安全性,可以采取以下措施:
- 对用户输入进行过滤,去除可能引起安全隐患的语音;
- 对敏感信息进行加密,防止泄露;
- 对机器学习模型进行访问控制,防止未经授权的访问。
6. 结论与展望
6.1. 技术总结
将 reinforcement learning 应用于智能语音识别高级优化,可以有效提高识别准确率、实现更智能化的语音助手。通过对算法的深入剖析,为语音识别领域的从业者提供有益参考。文章来源:https://www.toymoban.com/news/detail-709679.html
6.2. 未来发展趋势与挑战
未来的语音识别技术将继续发展,面临以下挑战:文章来源地址https://www.toymoban.com/news/detail-709679.html
- 对长篇语音的处理能力,如处理包含多种语音特征的长篇语音;
- 对噪声、回声等干扰的识别能力;
- 实现与多模态语音的集成,如图像识别、手势识别等。
7. 附录:常见问题与解答
到了这里,关于将 reinforcement learning 应用于智能语音识别高级优化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!