标准 IO
注: 李慧芹老师的视频课程请点这里, 本篇为标准IO一章的笔记, 课上提到过的内容基本都会包含
I/O (Input & Output): 是一切实现的基础
stdio (标准IO)
sysio (系统调用IO / 文件IO)
系统IO是内核接口, 标准IO是C标准库提供的接口, 标准IO内部使用了系统IO
标准IO会合并系统调用, 可移植性好, 因此在两者都可以完成任务的情况下, 优先使用标准IO
stdio 的一系列函数
详细参考man(3);
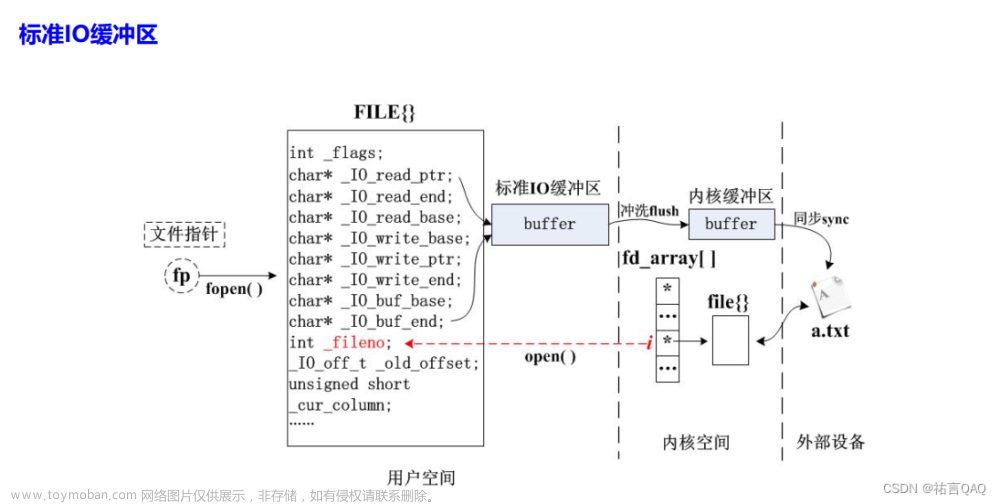
FILE类型贯穿始终, FILE类型是一个结构体
fopen(): 产生FILE
fclose()
fgetc()
fputc()
fgets()
fputs()
fread()
fwrite()
pintf()一族
scanf()一族
fseek()
ftell()
rewind()
fflush()
打开操作
// 打开文件操作, 运行成功时, 返回FILE指针, 失败则返回NULL且设置errno
// params:
// @path: 要打开的文件
// @mode: 打开的权限(如: 只读/读写/只写...)
FILE *fopen(const char *path, const char *mode);
const char *
面试题:
char *ptr = "abc"; ptr[0] = 'x'; // 语句2问: 能否通过语句2得到值为
"xbc"的字符串?
gcc编译会报错(修改常量值), 但Turbo C一类的编译器编译出的程序会运行通过
errno
ubuntu22系统中, 可以执行vim /usr/include/errno.h来查看相关信息
errno曾经是一个全局变量, 但目前已被私有化, 新建test.c:
#include <errno.h>
errno;
执行gcc -E test.c对test.c进行预处理, 会得到:
// MacOS操作系统上的运行结果:
extern int * __error(void);
(*__error());
// Ubuntu22上的运行结果:
(*__errno_location ());
可以看到, errno已经被转化为宏 (而不是int类型全局变量)
再新建测试程序errno.c:
#include <stdlib.h>
#include <stdio.h>
#include <errno.h>
int main(void)
{
FILE *fp;
fp = fopen();
if (fp == NULL)
{
fprintf(stderr, "fopen() failed! errno = %d\n", errno);
exit(1);
}
puts("OK");
exit(0);
}
编译并运行该程序, 输出结果:
fopen() failed! errno = 2
标准C中定义的errno类型:
| 类型 | 序号 | 含义 |
|---|---|---|
| EPERM | 1 | Operation not permitted |
| ENOENT | 2 | No such file or directory |
| ESRCH | 3 | No such process |
| EINTR | 4 | Interrupted system call |
| EIO | 5 | I/O error |
| ENXIO | 6 | No such device or address |
| E2BIG | 7 | Argument list too long |
| ENOEXEC | 8 | Exec format error |
| EBADF | 9 | Bad file number |
| ECHILD | 10 | No child processes |
| EAGAIN | 11 | Try again |
| ENOMEM | 12 | Out of memory |
| EACCES | 13 | Permission denied |
| EFAULT | 14 | Bad address |
| ... | ... | ... |
根据上表中展示的errno类型, 可以得知, 2代表了文件或目录不存在
可以调用perror()或strerror()来将errno转化为error message
mode
mode必须以表格中的字符开头
| 符号 | 模式 |
|---|---|
| r | 以只读形式打开文件, 打开时定位到文件开始处 |
| r+ | 读写形式打开文件, 打开时定位到文件开始处 |
| w | 写形式打开文件, 有则清空, 无则创建 |
| w+ | 读写形式打开文件, 有则清空, 无则创建 |
| a | 追加只写的形式打开文件, 如文件不存在, 则创建文件; 打开时定位到文件末尾处 (文件最后一个有效字节的下一个位置) |
| a+ | 追加读写的形式打开文件, 如文件不存在, 则创建文件; 读位置在文件开始处, 而写位置永远在文件末尾处 |
注意:
r和r+要求文件必须存在mode可以追加字符
b, 如rb/r+b,b表示二进制流, 在POSIX环境(包括Linux环境)下,b可以忽略
面试题:
FILE *fp; fp = fopen("tmp", "r+write"); // 语句2问: 语句2是否会报错?
并不会, fopen函数只会识别
r+, 后面的字符会被忽略
FILE *
fopen返回的FILE结构体指针指向的内存块存在在哪里?
堆上
有逆操作的, 返回指针的函数, 其返回的指针一定指向堆上某一块空间
如无逆操作, 则有可能指向堆, 也有可能指向静态区
关闭操作
由于fopen返回的指针在堆上, 因此需要有一逆操作释放这一堆上的空间
int fclose(FILE *fp);
小例子
一个进程中, 打开的文件个数的上限?
#include <stdlib.h>
#include <stdio.h>
#include <errno.h>
int main()
{
FILE *fp;
int cnt = 0;
while (1)
{
fp = fopen("tmp", "r");
if (fp == NULL)
{
perror("fopen()");
break;
}
cnt ++;
}
printf("count = %d\n", cnt);
exit(0);
}
运行结果:
fopen(): Too many open files
count = 1021
在不更改当前默认环境的情况下, 进程默认打开三个流: stdin, stdout, stderr
ulimit -a可以查看当前默认环境的资源限制, 其中包括默认最多打开流的个数:
$ ulimit -a
real-time non-blocking time (microseconds, -R) unlimited
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 7303
max locked memory (kbytes, -l) 251856
max memory size (kbytes, -m) unlimited
open files (-n) 1024 # 默认最多1024个流
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 7303
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
由于最多可以打开1024个stream, 而默认已经打开了三个, 因此程序输出的count的大小就等于1024 - 3 = 1021
文件权限
在上一案例中, 程序打开的tmp文件是由touch命令创造出来的, 其权限为0664, 为什么是0664?
公式: 权限 = 0666 & ~umask
umask的值可以通过umask命令查询, 该值主要用于防止权限过松的文件出现
$ umask
0002
读/写字符操作
- 读字符
// 以unsigned char转为int的形式返回读到的字符
// 如读到文件末尾, 或发生错误, 返回EOF
int fgetc(FILE *stream); // 函数
int getc(FILE *stream); // 宏
// getchar()相当于getc(stdin)
- 写字符
int fputc(int c, FILE *stream);
int putc(int c, FILE *stream);
// 相当于putc(c, stdout)
int putchar(int c);
mycpy
实现复制文件命令mycpy
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char **argv)
{
FILE *fps, *fpd;
int ch;
if (argc < 3)
{
fprintf(stderr, "Usage:%s <src_file> <dest_file>", argv[0]);
exit(1);
}
fps = fopen(argv[1], "r");
if (fps == NULL)
{
perror("fopen()");
exit(1);
}
fpd = fopen(argv[2], "w");
if (fpd == NULL)
{
perror("fopen()");
fclose(fps);
exit(1);
}
while (1)
{
ch = fgetc(fps);
if (ch == EOF)
break;
fputc(ch, fpd);
}
// 先关闭依赖别人的流, 再关闭被依赖的文件
fclose(fpd);
fclose(fps);
}
编译后执行以下命令:
$ ./mycpy /etc/services ./out
$ diff /etc/services ./out
如果diff命令什么也没有输出, 则说明mycpy命令已正确执行
fsize
查看文件有效字符的个数
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char **argv)
{
FILE *fp;
long long cnt = 0;
if (argc < 2)
{
fprintf(stderr, "Usage:%s <file_name>", argv[0]);
exit(1);
}
fp = fopen(argv[1], "r");
if (fp == NULL)
{
perror("fopen()");
exit(1);
}
while (fgetc(fp) != EOF)
cnt ++;
printf("%lld\n", cnt);
fclose(fp);
exit(0);
}
读写字符串
- 读字符串:
// params:
// @s: 缓冲区
// @size: 缓冲区大小
char *fgets(char *s, int size, FILE *stream);
fgets有两种正常结束:
-
读到size-1个字节 (缓冲区内剩余一个字节需要存放'\0')
-
读到了'\n'字符 (文件末尾处默认有换行符)
问题:
假设有一文件:
abcd问: 用
fgets(buff, 5, file)语句读取该文件, 需要几次才能读完?2次, 第一次读取到"abcd", 第二次读取到"\n"
- 写字符串:
int fputs(const char *s, FILE *stream);
重写 mycpy
#include <stdlib.h>
#include <stdio.h>
#define BUFSIZE 1024
int main(int argc, char **argv)
{
FILE *fps, *fpd;
char buff[BUFSIZE];
if (argc < 3)
{
fprintf(stderr, "Usage:%s <src_file> <dest_file>", argv[0]);
exit(1);
}
fps = fopen(argv[1], "r");
if (fps == NULL)
{
perror("fopen()");
exit(1);
}
fpd = fopen(argv[2], "w");
if (fpd == NULL)
{
perror("fopen()");
fclose(fps);
exit(1);
}
// === 1 ===
// 利用读写字符串函数来完成文件复制
while (fgets(buff, BUFSIZE, fps) != NULL)
{
fputs(buff, fpd);
}
// === ===
// 先关闭依赖别人的流, 再关闭被依赖的文件
fclose(fpd);
fclose(fps);
}
重写后的代码改为利用读写字符串函数来完成复制文件的操作(见1处)
fread & fwrite
fread & fwrite用于二进制流的输入和输出
// 从stream流中读取nmemb个数据
// 每个数据的大小为size
// 读取到的所有数据保存到ptr指向的内存空间
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
// 将ptr指向的数据输出到stream
size_t fwrite(const void *ptr, size_t size, size_t nemeb, FILE *stream);
问题:
要通过
fread()从文件中读取字符串, 每次读取10个字符
- 假设文件中的有效字符数远大于10, 则2个语句各返回几?
// 语句1 fread(ptr, 1, 10, fp); // 语句2 fread(ptr, 10, 1, fp);语句1返回10(读到了10个大小为1的对象)
语句2返回1(读到了1个大小为10的对象)
- 假设文件中的有效字符数不足10个(比如5个), 则2个语句各返回几?
语句1返回5, 而语句2返回0
另外, 语句二返回0后, 它究竟读了多少个字符, 也无从得知; 因此, 如果要通过
fread()从文件中读取字符串, 则一定要使用语句1的方法!
注意:
用
fread()或fwrite()操作文件, 最好还是只做存取单一大小的数据(例如: 单一类型的结构体数据)的操作; 尽管如此, 这样的操作依然是有风险的, 因为一旦文件中由于各种原因含有了其他的数据, 那么fread()就会彻底失灵
printf & scanf
- printf一族
int printf(const char *format, ...);
int fprintf(FILE *stream, const char *stream, ...);
// 将format与参数综合的结果, 输入到str中
int sprintf(char *str, const char *format, ...);
// 与sprintf类似, 只是多了对str大小的规定(size)以防止写越界
int snprintf(char *str, size_t size, const char *format, ...);
注意:
尽管printf一族提供了大量的输出函数, 但是这些函数还是不能完全解决问题
sprintf和snprintf中, str不能自行增长, 因此不能解决需要输出长字符串的需求
- scanf一族
int scanf(const char *format, ...);
int fscanf(FILE *stream, const char *format, ...);
int sscanf(const char *str, const char *format, ...);
注意:
使用scanf一族时, 是不清楚要输入进来的数据有多长的
因此要注意, 输入文本的长度是否大于缓冲区的大小
年-月-日
以year-month-day的格式打印日期:
#include <stdlib.h>
#include <stdio.h>
int main()
{
char buf[1024];
int year = 2014, month = 5, day = 13;
sprintf(buf, "%d-%d-%d", year, month, day);
puts(buf);
exit(0);
}
文件位置
// 将文件指针定位到文件的某一位置(whence+offset)
// whence有三个选项: SEEK_SET(文件开始位置), SEEK_CUR(当前位置), SEEK_END(文件末尾位置)
// offset的单位为字节int fseek(FILE *stream, long offset, int whence);
long fseek(FILE *stream, long offset, int whence);
// 获得当前文件指针指向的文件位置
long ftell(FILE *stream);
// 相当于: (void) fseek(stream, 0L, SEEK_SET)
void rewind(FILE *stream);
文件位置指针
文件位置指针指向对文件进行操作的位置, 如:
fp = fopen(...);
for (i = 0; i < 10; i ++)
{
fputc(fp);
}
在上述代码结束后, fp的文件位置指针指向文件第11个字节的位置
为了能将文件位置指针移动到文件内的任意位置上, 有了fseek等函数
flen
将原先的fsize.c复制为flen.c, 并重写为:
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char **argv)
{
FILE *fp;
if (argc < 2)
{
fprintf(stderr, "Usage:%s <file_name>", argv[0]);
exit(1);
}
fp = fopen(argv[1], "r");
if (fp == NULL)
{
perror("fopen()");
exit(1);
}
fseek(fp, 0, SEEK_END);
printf("%ld\n", ftell(fp));
fclose(fp);
exit(0);
}
fseeko & ftello
由于
ftell的返回值的类型为long, 而又不可能为负数, 因此其值域(在64位机器上)为$[0, 2^32 - 1]$, 因此利用ftell和fseek一同工作时, 只能定位2G大小的文件
由于ftell有值域限制, 因此有了fseeko和ftello:
int fseeko(FILE *stream, off_t offset, int whence);
off_t ftello(FILE *stream);
在一些机器上, off_t是32位的, 在定义宏_FILE_OFFSET_BITS值为64后, 可以保证off_t为64位
可以在Makefile中定义CFLAG, 使编译器在编译阶段得知_FILE_OFFSET_BITS被定义为64:
CFLAGS+=-D_FILE_OFFSET_BITS=64
注意:
fseeko和ftello是POSIX环境的方言, C89和C99标准对其没有定义
刷新缓冲区
printf("Before while()"); // 第1行
while(1);
printf("After while()");
上述代码什么也不会打印, 这是由于标准输出是行缓冲的, 而"Before while()"并非一行内容
可以将第1行代码修改为printf("Before while()\n");或者在第1行代码后增加fflush(stdout);来刷新标准输出的缓冲区
缓冲区的作用: 大多数情况下是好事, 合并系统调用
行缓冲:
换行的时候刷新, 缓冲区满了的时候刷新, 强制刷新
全缓冲:
缓冲区满了的时候刷新, 强制刷新(默认, 只要不是终端设备)
无缓冲:
如stderr, 需要立即输出的内容
可以利用
setvbuf修改缓冲模式
读取完整一行
实现了完整读取一行内容的函数:
// 从stream中读取一行内容, 存到lineptr指向的缓冲区
ssize_t getline(char **lineptr, size_t *n, FILE *stream);
使用时, 需要定义宏#define _GNU_SOURCE
可以在Makefile中, 添加CFLAG:
CFLAGS+=-D_GNU_SOURCE
注意:
不需要自己为缓冲区分配空间, lineptr可为一个值为NULL的指针变量的地址
getline只能在GNU C环境中使用
mygetline
自行实现一个功能为从流中读取一行内容, 且在标准C环境中可以使用的工具:
#ifndef _MY_GETLINE_H__
#define _MY_GETLINE_H__
#define DEFAULT_LINE_BUF_SIZE 120
/*
* 从stream中读取一行内容, 并将读取到的内容保存在*lineptr指向的缓冲区中
* n指向缓冲区大小
*
* 返回值:
*
* 返回读取到的文本长度, 如果发生错误或读到文件末尾, 返回-1
* */
long long mygetline(char **lineptr, size_t *n, FILE *stream);
/*
* 释放缓冲区占用的内存空间
* */
void mygetline_free(char **lineptr);
#endif
#include <stdlib.h>
#include <stdio.h>
#include "mygetline.h"
long long mygetline(char **lineptr, size_t *n, FILE *stream)
{
size_t buffsize = *n;
char *linebuff = *lineptr;
long long idx = 0LL;
int ch;
if (*lineptr == NULL || *n <= 0)
{
buffsize = DEFAULT_LINE_BUF_SIZE;
linebuff = malloc(buffsize * sizeof(char));
}
if (linebuff == NULL)
return -1;
while ((ch = fgetc(stream)) != EOF)
{
if ((char)ch == '\n')
break;
linebuff[idx ++] = (char)ch;
if (idx >= buffsize - 1)
{
buffsize += (buffsize >> 1);
linebuff = realloc(linebuff, buffsize);
}
}
linebuff[idx] = '\0';
*lineptr = linebuff;
*n = buffsize;
return ch != EOF ? idx : -1;
}
void mygetline_free(char **lineptr)
{
if (*lineptr != NULL)
free(*lineptr);
*lineptr = NULL;
}
临时文件
-
如何不冲突地创建临时文件
-
及时销毁
可用函数: tmpnam/tmpfile文章来源:https://www.toymoban.com/news/detail-709941.html
// 获得一个可用的临时文件名
// 注意: 使用该函数时, 需要:
// 1.首先拿到临时文件名
// 2.用该名称创建临时文件
// 由于这两步不是原子操作, 可能与其他进程产生冲突
// 因此该要谨慎使用该函数
char *tmpnam(char *s);
// 以二进制读写(w+b)模式打开一个临时文件
FILE *tmpfile(void);
下一章: 系统调用IO文章来源地址https://www.toymoban.com/news/detail-709941.html
到了这里,关于最全的李慧芹APUE-标准IO笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!