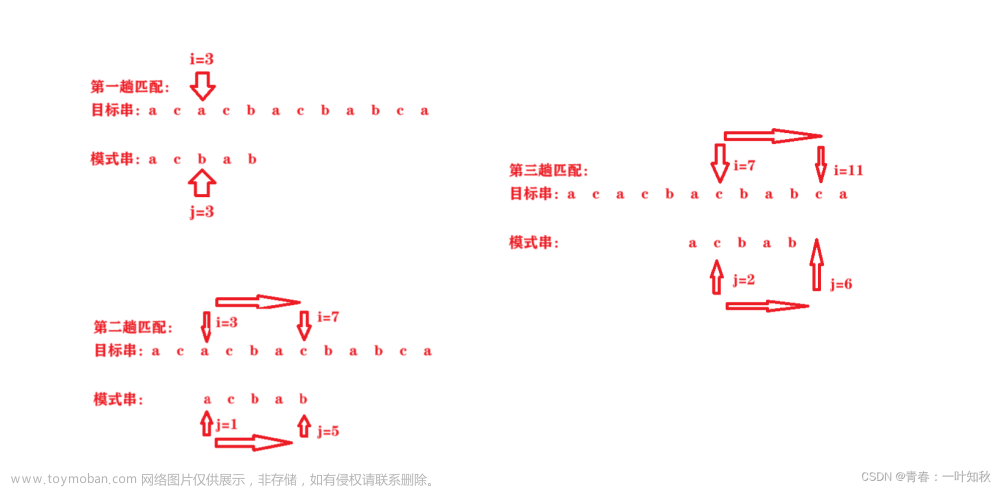
KMP算法是一种高效的字符串匹配算法,它的核心思想是利用已经匹配成功的子串前缀的信息,避免重复匹配,从而达到提高匹配效率的目的。KMP算法的核心是构建模式串的前缀数组Next,Next数组的意义是:当模式串中的某个字符与主串中的某个字符失配时,Next数组记录了模式串中应该回退到哪个位置,以便继续匹配。Next数组的计算方法是找出模式串每一个前缀中最长的相等前缀和后缀,并记录下来它们的长度,作为Next数组中的对应值。
在字符串匹配时,KMP算法从主串和模式串的开头开始逐个字符比较,若发现匹配失败,则根据Next数组中的值进行回退,从失配位置的下一位重新开始比较。这样回退的次数比暴力匹配方式要少得多,因此匹配效率得到了大幅提升。
6.1.1 遍历输出进程内存
首先需要实现取进程PID的功能,当用户传入一个进程名称时则输出该进程的PID号,通过封装GetPidByName函数,该函数用于根据指定的进程名称,获取该进程的进程PID,以便于后续针对进程进行操作。函数参数name为指定的进程名称字符串。该函数通过调用CreateToolhelp32Snapshot函数创建一个系统快照,返回系统中所有进程的快照句柄。然后使用该快照句柄,通过进程快照函数Process32First和Process32Next函数逐个对比进程的名称,找到进程名称匹配的PID,返回该PID。若无法找到匹配的进程名称,则返回0。读者需要注意,当使用进程遍历功能时通常需要引入<tlhelp32.h>库作为支持;
// 根据进程名得到进程PID
DWORD GetPidByName(const char* name)
{
HANDLE snapshot = CreateToolhelp32Snapshot(TH32CS_SNAPPROCESS, 0);
PROCESSENTRY32 pe32 = { sizeof(PROCESSENTRY32) };
DWORD pid = 0;
if (Process32First(snapshot, &pe32))
{
do
{
if (_stricmp(pe32.szExeFile, name) == 0)
{
pid = pe32.th32ProcessID;
break;
}
} while (Process32Next(snapshot, &pe32));
}
CloseHandle(snapshot);
return pid;
}
在开始使用KMP枚举特征码之前我们需要实现简单的内存读写功能,通过封装一个MemoryTraversal函数,该函数接收三个参数分别是,进程PID,进程开始内存地址,以及进程结束内存地址,该函数输出当前进程内存机器码,每次读入4096字节,然后每16个字符换一次行,遍历内存0x00401000 - 0x7FFFFFFF这篇内存区域,这段代码实现如下所示;
// 遍历并输出进程内存
VOID MemoryTraversal(DWORD PID, const DWORD beginAddr, const DWORD endAddr)
{
const DWORD pageSize = 4096;
// 打开并获取进程句柄
HANDLE process = ::OpenProcess(PROCESS_ALL_ACCESS, false, PID);
BOOL _break = FALSE;
BYTE page[pageSize];
DWORD tmpAddr = beginAddr;
// 循环枚举进程
while (tmpAddr <= endAddr)
{
// 每次读入内存
ReadProcessMemory(process, (LPCVOID)tmpAddr, &page, pageSize, 0);
// 依次循环每一个字节
for (int x = 0; x < 4096; x++)
{
// 每16个字符换一行
if (x % 15 != 0)
{
DWORD ch = page[x];
if (ch >= 0 && ch <= 15)
{
printf("0%x ", ch);
}
else
{
printf("%x ", ch);
}
}
else
{
printf(" | %x \n", tmpAddr+x);
}
}
tmpAddr += pageSize;
}
}
int main(int argc, char *argv[])
{
// 通过进程名获取进程PID号
DWORD Pid = GetPidByName("PlantsVsZombies.exe");
printf("[*] 获取进程PID = %d \n", Pid);
// 输出内存遍历0x401000-0x7FFFFFFF
MemoryTraversal(Pid, 0x401000, 0x7FFFFFFF);
system("pause");
return 0;
}
读者可自行编译这段代码片段,并运行特定进程,当程序运行后即可输出PlantsVsZombies.exe进程内的机器码,并以16个字符为一个单位进行输出,其效果图如下所示;

6.1.2 使用KMP搜索特征码
为了能让读者更好的理解KMP特征码搜索的实现原理,这里笔者依然在MemoryTraversal函数基础之上进行一定的改进在本次改进中,我们增加了memcmp函数,通过使用该函数我们可以很容易的实现对特定内存区域的相同比较,读者在调用ScanMemorySignatureCode函数时需要传入,开始地址,结束地址,特征码,以及特征码长度,当找到特定内存后则返回该内存的所在位置。
// 内存特征码搜索
ULONG ScanMemorySignatureCode(DWORD Pid, DWORD beginAddr, DWORD endAddr, unsigned char *ShellCode, DWORD ShellCodeLen)
{
unsigned char *read = new unsigned char[ShellCodeLen];
// 打开进程
HANDLE process = OpenProcess(PROCESS_ALL_ACCESS, false, Pid);
// 开始搜索内存特征
for (int x = 0; x < endAddr; x++)
{
DWORD addr = beginAddr + x;
// 每次读入ShellCodeLen字节特征
ReadProcessMemory(process, (LPVOID)addr, read, ShellCodeLen, 0);
int a = memcmp(read, ShellCode, ShellCodeLen);
if (a == 0)
{
printf("%x :", addr);
for (int y = 0; y < ShellCodeLen; y++)
{
printf("%02x ", read[y]);
}
printf(" \n");
return addr;
}
}
return 0;
}
int main(int argc, char *argv[])
{
// 通过进程名获取进程PID号
DWORD Pid = GetPidByName("PlantsVsZombies.exe");
printf("[*] 获取进程PID = %d \n", Pid);
// 开始搜索特征码
unsigned char ScanOpCode[3] = { 0x56, 0x57, 0x33 };
// 依次传入开始地址,结束地址,特征码,以及特征码长度
ULONG Address = ScanMemorySignatureCode(Pid, 0x401000, 0x7FFFFFFF, ScanOpCode, 3);
printf("[*] 找到内存地址 = 0x%x \n", Address);
system("pause");
return 0;
}
上述程序运行后,将枚举当前进程0x401000-0x7FFFFFFF区域中特征码为0x56, 0x57, 0x33的内存地址,枚举到以后则输出该内存地址的位置,输出效果图如下图所示;

有了上面的模板我们只需要在此基础之上增加KMP枚举方法即可实现,如下代码则是替换具有KMP功能的搜索模式,在代码中可看出我们仅仅只是将ScanMemorySignatureCode函数内部的memcmp函数替换为了KMPSearchString函数,其他位置并没有任何变化,此处主要增加的函数有GetNextval以及KMPSearchString,这两个函数的核心思想是利用KMP算法,在主字符串中寻找子字符串时,遇到匹配失败的字符时,能够跳过一些已经比较过的字符,重复利用部分匹配的结果,提高字符串匹配的效率。将子串的每个字符失配时应该跳转的位置通过GetNextval函数计算得出,然后在KMPSearchString函数中通过这个数组进行跳转和匹配。该算法的时间复杂度为O(m+n),其中m和n分别表示主串和模式串的长度。
#include <iostream>
#include <windows.h>
#include <tlhelp32.h>
using namespace std;
// 根据进程名得到进程PID
DWORD GetPidByName(const char* name)
{
HANDLE snapshot = CreateToolhelp32Snapshot(TH32CS_SNAPPROCESS, 0);
PROCESSENTRY32 pe32 = { sizeof(PROCESSENTRY32) };
DWORD pid = 0;
if (Process32First(snapshot, &pe32))
{
do
{
if (_stricmp(pe32.szExeFile, name) == 0)
{
pid = pe32.th32ProcessID;
break;
}
} while (Process32Next(snapshot, &pe32));
}
CloseHandle(snapshot);
return pid;
}
/*
* P 为模式串,下标从 0 开始。
* nextval 数组是模式串 SubString 中每个字符失配时应该回溯的位置。
*/
void GetNextval(string SubString, int nextval[])
{
int SubStringLen = SubString.size(); // 计算模式串的长度
int i = 0; // 子串的指针
int j = -1; // 前缀的指针
nextval[0] = -1; // 初始化 nextval 数组,将第一个值设为 -1
while (i < SubStringLen - 1)
{
if (j == -1 || SubString[i] == SubString[j]) // 如果子串和前缀相等,或 j==-1
{
i++; j++; // 子串指针和前缀指针分别加一
if (SubString[i] != SubString[j]) // 如果下一个字符不相等
{
nextval[i] = j; // 将前缀指针 j 的值赋给 nextval 数组中的当前位置 i
}
else // 如果下一个字符相等
{
nextval[i] = nextval[j]; // 已经有 nextval[j],所以将它赋给 nextval[i]
}
}
else // 如果子串和前缀不相等
{
j = nextval[j]; // 更新前缀指针 j 的值,指向 nextval[j]
}
}
}
/* 在 MainString 中找到 SubString 第一次出现的位置 下标从0开始*/
int KMPSearchString(string MainString, string SubString, int next[])
{
GetNextval(SubString, next);
int MainStringIndex = 0; // 存储主字符串下标
int SubStringIndex = 0; // 存储子字符串下标
int MainStringLen = MainString.size(); // 主字符串大小
int SubStringLen = SubString.size(); // 子字符串大小
// 循环遍历字符串,因为末尾 '\0' 的存在,所以不会越界
while (MainStringIndex < MainStringLen && SubStringIndex < SubStringLen)
{
// MainString 的第一个字符不匹配或 MainString[] == SubString[]
if (SubStringIndex == -1 || MainString[MainStringIndex] == SubString[SubStringIndex])
{
MainStringIndex++; SubStringIndex++;
}
else // 当字符串匹配失败则跳转
{
SubStringIndex = next[SubStringIndex];
}
}
// 最后匹配成功直接返回位置
if (SubStringIndex == SubStringLen)
{
return MainStringIndex - SubStringIndex;
}
return -1;
}
// 内存特征码搜索
ULONG ScanMemorySignatureCode(DWORD Pid, DWORD beginAddr, DWORD endAddr, char *ShellCode, DWORD ShellCodeLen)
{
char *read = new char[ShellCodeLen];
// 打开进程
HANDLE process = OpenProcess(PROCESS_ALL_ACCESS, false, Pid);
int next[100] = { 0 };
// 开始搜索内存特征
for (int x = 0; x < endAddr; x++)
{
DWORD addr = beginAddr + x;
// 每次读入ShellCodeLen字节特征
ReadProcessMemory(process, (LPVOID)addr, read, ShellCodeLen, 0);
// 在Str字符串中找Search子串,找到后返回位置
int ret = KMPSearchString(read, ShellCode, next);
if (ret != -1)
{
return addr;
}
}
return 0;
}
int main(int argc, char *argv[])
{
// 通过进程名获取进程PID号
DWORD Pid = GetPidByName("PlantsVsZombies.exe");
printf("[*] 获取进程PID = %d \n", Pid);
// 开始搜索特征码
char ScanOpCode[3] = { 0x56, 0x57, 0x33 };
// 依次传入开始地址,结束地址,特征码,以及特征码长度
ULONG Address = ScanMemorySignatureCode(Pid, 0x401000, 0x7FFFFFFF, ScanOpCode, 3);
printf("[*] 找到内存地址 = 0x%x \n", Address);
system("pause");
return 0;
}
编译并运行上述代码片段,读者应该能看出与暴力枚举并无任何区别,其输出效果图如下图所示;文章来源:https://www.toymoban.com/news/detail-709959.html
 文章来源地址https://www.toymoban.com/news/detail-709959.html
文章来源地址https://www.toymoban.com/news/detail-709959.html
到了这里,关于6.1 KMP算法搜索机器码的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!







![集成多元算法,打造高效字面文本相似度计算与匹配搜索解决方案,助力文本匹配冷启动[BM25、词向量、SimHash、Tfidf、SequenceMatcher]](https://imgs.yssmx.com/Uploads/2024/02/753544-1.png)




