1.数据库分区
分区优点
1、与单个磁盘或文件系统分区相比,可以存储更多的数据。
2、通过删除与增加那些数据有关的分区,很容易地删除或增加那些数据。
3、一些查询可以得到极大的优化。
4、通过跨多个磁盘甚至服务器来分散数据查询,来获得更大询吞吐量。
5、MySQL5.5之后支持所有函数的分区优化。限定只查询有效的分区。
Range分区
基于属于一个给定连续区间的列值,把多行分配给分区。
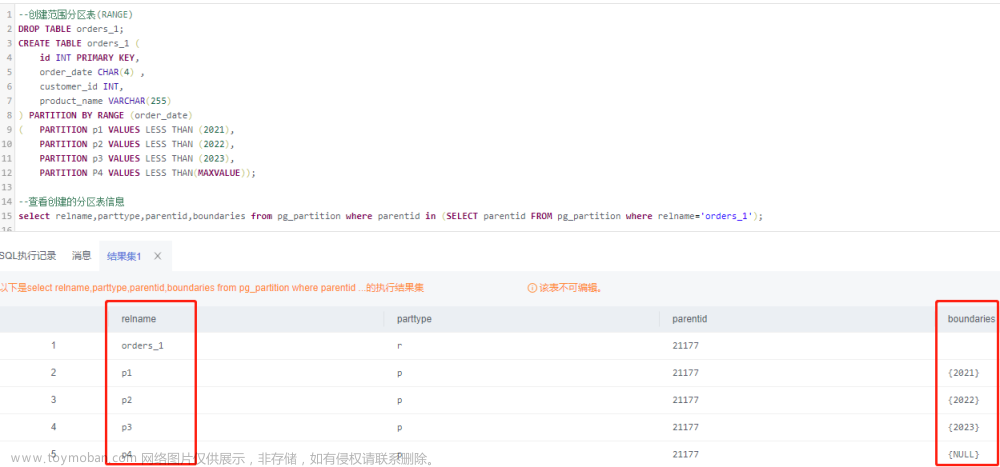
ALTER TABLE titles
//分区语句 range
partition by range (year(from_date))// year(from_date) 分区的依据
(
partition po1 values less than (1985), 小于不包含[-无穷,1985)
partition po2 values less than (1986),
partition po3 values less than (1987),
partition p04 values less than (1988),
partition p15 values less than (1999),
partition p16 values less than (MAXVALUE)
);
list分区
类以于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
create table t2 (id int,cid int,name varchar(20),pos_date datetime)
partition by list (cid)
(
partition po1 values in (1,2,3),
partition p02 values in (4,5,6),
partition po3 values in (7,8,9)
);
Hash分区
基于用户定义的表达式的返回值来进行选择的分区,基于插入的行的列信息通过表达式计算返回非负整数来确定分区
使用HASH分区的优点在于数据分布较为均匀
create table t3 (id int,cid int,name varchar(20),pos_date datetime)
partition by hash(cid)
partitions 4;
Linear Hash分区
1.缺点
数据分布不均衡(有的分区数据多,有的分区数据少)
2.优点
- 增加、删除、合并和拆分分区快捷
- 有利于处理大量数据表
create table t3 (id int,cid int,name varchar(20),pos_date datetime)
partition by linear hash(cid)
partitions 4;
key分区
create table t3 (id int,cid int,name varchar(20),pos_date datetime)
partition by key(cid)
partitions 4;
添加功能(mysql 5.5版本以上)
多列分区columns (string date)
create table t4(a int,b int,c int)
partition by range columns(a,b) //插入时按从左往右进行对比
(
partition po1 values less than (10,20),
partition p02 values less than (10,30),
partition po3 values less than (10,maxvalue)
);
子分区
子分区是分区表中每个分区的再次分割。
子分区可以用于特别大的表,在多个磁盘间分配数据和索引。
CREATE TABLE t5 (id INT,udate DATE)
PARTITION BY RANGE(YEAR(udate))
SUBPARTITION BY HASH(TO_DAYS(udate))
SUBPARTITIONS 2
(
PARTITION PO VALUES LESS THAN(1990)
PARTITION p1 VALUES LESS THAN (2000),
PARTITION p2 VALUES LESS THAN MAXVALUE
);
子分区将数据和索引分配到不同文件夹下,减轻单个I/O压力
CREATE TABLE t5 (id INT,udate DATE)
PARTITION BY RANGE(YEAR(udate))
SUBPARTITION BY HASH(TO_DAYS(udate))
(
partition p0l values less than (1999)
(
subpartition s0
data directory='/var/a/data'
inde× directory="/var/a/idx',
subpartition s1
data directory='/var/b/data'
index directory='/var/b/idx'
),
partition p02 values less than (2000)
(
subpartition s2
data directory='/var/c/data'
index directory='/var/c/idx',
subpartition s3
data directory='/var/d/data'
index directory='/var/d/idx'
)
);
分区管理和维护
1.alter进行简单修改分区
ALTER语句简单修改了分区。效果和先删除原表再按新的分区方式重新建表效果相同。
alter table t3 partition by key() partitions 2
2.删除分区
alter table t3 drop partition p02 //删除本分区结构和数据
alter table t3 truncate partition p01 //不删除本分区结构,只删除本分区数据
3.range添加分区
partition by range (year(from_date))// year(from_date) 分区的依据
(
partition po1 values less than (1985), 小于不包含[-无穷,1985)
partition po2 values less than (1986)
)
alter table t1 add partition (partition p02 values less than("date"))
注意
"date"填写的数据必须高于上次创建分区的最大值
4.list添加分区
partition by list (cid)
(
partition po1 values in (1,2,3),
partition p02 values in (4,5,6),
partition po3 values in (7,8,9)
);
alter table t1 add partition (partition p02 values in ("date"))
注意
"date"填写的数据不能包含原有的数据
5.分区重组
ALTER TABLE t1 REORGANIZE PARTITION pO1 INTO(
PARTITION sO VALUES LESS THAN(5)
PARTITION s1 VALUES LESS THAN(10));
注意
1.range分区重组 只能相邻的分区 不能跳过分区重组
2.list分区重组,重组的必须覆盖原有区间
6.hash和key分区数量
alter table t3 coalesce partition 2 //在原有的分区数量上减少2个
alter table t3 add partition partitions 2 //在原有的分区数量上增加2个
分片
- 垂直分片
业务维度将表拆分到不同的数据库中,专库专用,分担数据库压力。文章来源:https://www.toymoban.com/news/detail-710588.html
- 水平分片
解决单表数据过大的问题文章来源地址https://www.toymoban.com/news/detail-710588.html
数据库索引
- 按数据结构分类:B+tree索引 Hash索引 Full-text索引,
- 按物理存储分类: 聚集索引、非聚集索引。
- 按字段特性分类:主键索引(PRIMARY KEY)、唯一索引(UNIQUE)、普通索 (INDEX)、全文索引(FULLTEXT)。
- 按字段个数分类:单列索引、联合索引(也叫复合索引、组合索引)
到了这里,关于数据库分区的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!