深搜(DFS)与广搜(BFS)
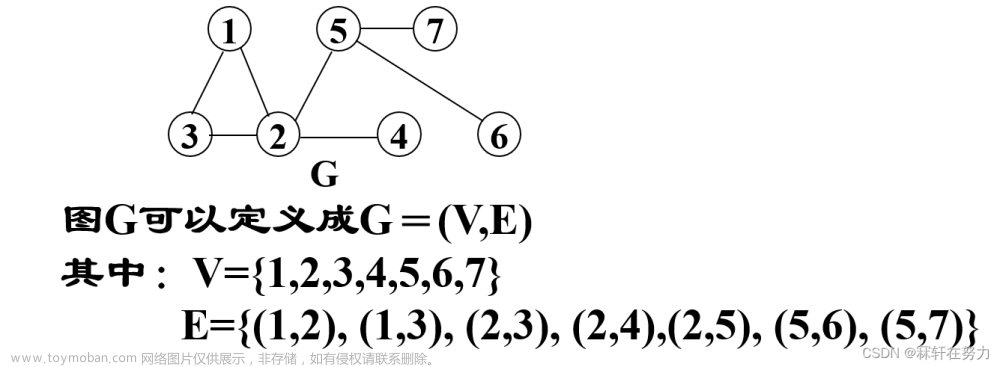
在查找二叉树某个节点时,如果把二叉树所有节点理解为解空间,待找到那个节点理解为满足特定条件的解,对此解答可以抽象描述为: 在解空间中搜索满足特定条件的解,这其实就是搜索算法(Search)的一种描述。当然也有其他描述,比如是“指一类用于在数据集合中查找特定项或解决问题的算法”,又或者是“指通过按照一定规则逐一检查数据,以找到所需的信息或解决特定的问题。”等等。
搜索算法在计算机科学和信息检索中具有广泛的应用,包括搜索引擎、数据库查询、排序、路径规划、机器学习和人工智能等领域。其中最基础之一的搜索算法就是 深度优先搜索(Depth First search,简称 DFS)和广度优先搜索(Breadth First Search,简称 BFS)。
PS:因发明“深度优先搜索算法”,约翰·霍普克洛夫特 与 罗伯特·塔扬在1986年共同获得计算机领域的最高奖图灵奖
在写这两种算法之前,先看几个数据结构。
队列(Queue)、栈(Stack)
排队相信是日常生活中购物时可能遇到的情况,其中最重要的一个原则就是先来的先买。同样的,可以把类似这种规则应用在数据结构上,那么这种数据结构就是队列(Queue):是一种线性数据结构,遵循先进先出(First-In-First-Out,FIFO)的原则。
(PS:什么叫线性数据?指一种数据元素的有序集合,其中元素之间存在线性(有序)关系。)
其两个基本的操作:
- 入队(Enqueue): 向队列的末尾添加一个新元素。这个操作将新元素排队等待被处理。通常,它是队列中元素的最后一个操作。
- 出队(Dequeue): 从队列的前端移除一个元素,并返回它。这个操作模拟了第一个等待的元素被处理的情况。通常,出队操作是队列中元素的第一个操作。
如果把队列遵循的原则进行修改为后进先出,这样就演变出另外一种数据结构 栈(Stack):是一种线性数据结构,它遵循先进后出(Last-In-First-Out,LIFO)的原则。
同样类似队列两个基本操作:
- 入栈(Push): 向栈顶添加一个新元素。
- 出栈(Pop): 从栈顶移除元素。
PS:栈顶(Top)是当前位于栈的顶部的元素,也是栈中唯一一个可见的元素。

LeetCode 20. 有效的括号【简单】
给定一个只包括 '(',')','{','}','','' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
- 每个右括号都有一个对应的相同类型的左括号。

双端队列(Double-Ended Queue,简称 Deque)
如果要一个数据结构即支持队列的操作也支持栈的操作,双端队列(Double-Ended Queue,简称Deque)是这样一种线性数据结构,它具有队列和栈的特性,允许在队列的两端执行插入和删除操作。双端队列支持元素的快速插入和删除,无论是在队列的前端(头部)还是后端(尾部),因此它被称为"双端",即有两个端点。
双端队列的存储实现上既可以 是链表,也可以是 数组;可以根据实际情况进行选择。
// java 示例代码
Deque<Integer> dequeList = new LinkedList<>();
Deque<Integer> dequeArray = new ArrayDeque<>();

PS:由于双端队列能够覆盖 栈、队列两者的操作,使用Java解决算法题时,如需使用栈(Stack)、队列(Queue)情况 经常都会使用 Deque 来完成。
深度优先搜索(Depth First Search)
深度搜索(Depth-First Search,DFS)中的"深度"指的是在搜索问题的解空间时,算法首先沿着一条路径深入到解空间中,直到达到最深处或者无法再深入为止;然后再回退并继续探索下一个分支。
虽然 在上一篇 二叉树 中没提及这个名称,但其实上篇涉及的几个算法问题解法都是深度搜索;DFS通常使用递归或栈(堆栈)数据结构来实现,在这里不妨再练习一题。
LeetCode 113. 路径总和 II 【中等】
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。叶子节点 是指没有子节点的节点。

广度优先搜索(Breadth First Search)
广度搜索(Breadth-First Search,BFS)中的"广度"指的是算法在搜索问题的解空间时,从起始点开始逐层地向外扩展,以确保先探索当前层的所有节点,然后再深入到下一层的节点,层层展开。
所谓“层层展开” 例如在二叉树结构中,根节点是第0层,子节点是第1层,孙子节点是第2层,依此类推。BFS通常使用队列数据结构来实现。
LeetCode 515. 在每个树行中找最大值【中等】
给定一棵二叉树的根节点 root ,请找出该二叉树中每一层的最大值。

LeetCode 695. 岛屿的最大面积【中等】
给你一个大小为 m x n 的二进制矩阵 grid 。
岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在 水平或者竖直的四个方向上 相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。
岛屿的面积是岛上值为 1 的单元格的数目。计算并返回 grid 中最大的岛屿面积。如果没有岛屿,则返回面积为 0 。文章来源:https://www.toymoban.com/news/detail-711319.html

 文章来源地址https://www.toymoban.com/news/detail-711319.html
文章来源地址https://www.toymoban.com/news/detail-711319.html
总结下
- 队列(Queue)、栈(Stack)数据结构开始,引出到 双端队列(Double-Ended Queue);
- 深度搜索(Depth-First Search)的基本应用,通常使用递归或栈(堆栈)数据结构来实现;
- 广度优先搜索(Breadth First Search)的基本应用,通常使用队列数据结构来实现。
到了这里,关于数据结构与算法 | 深搜(DFS)与广搜(BFS)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!