文章来源:https://www.toymoban.com/news/detail-711442.html
后台数据的处理语言有很多,Java 是对前端采集的数据的一种比较常见的开发语言。互联网移动客户端的用户量特别大,大量的数据处理需求应运而生。可移动嵌入式设备的表现形式 很多,如 PC 端,手机移动端,智能手表,Google 眼镜等。Server2client 的互联网开发模式比较常见,有一种新的数据服务模式 end2end 。端到端的数据服务模式也应该要回归到一个最终的服务器。编程就是处理数据,数据像书籍一样,很重要,要入库编辑处理。
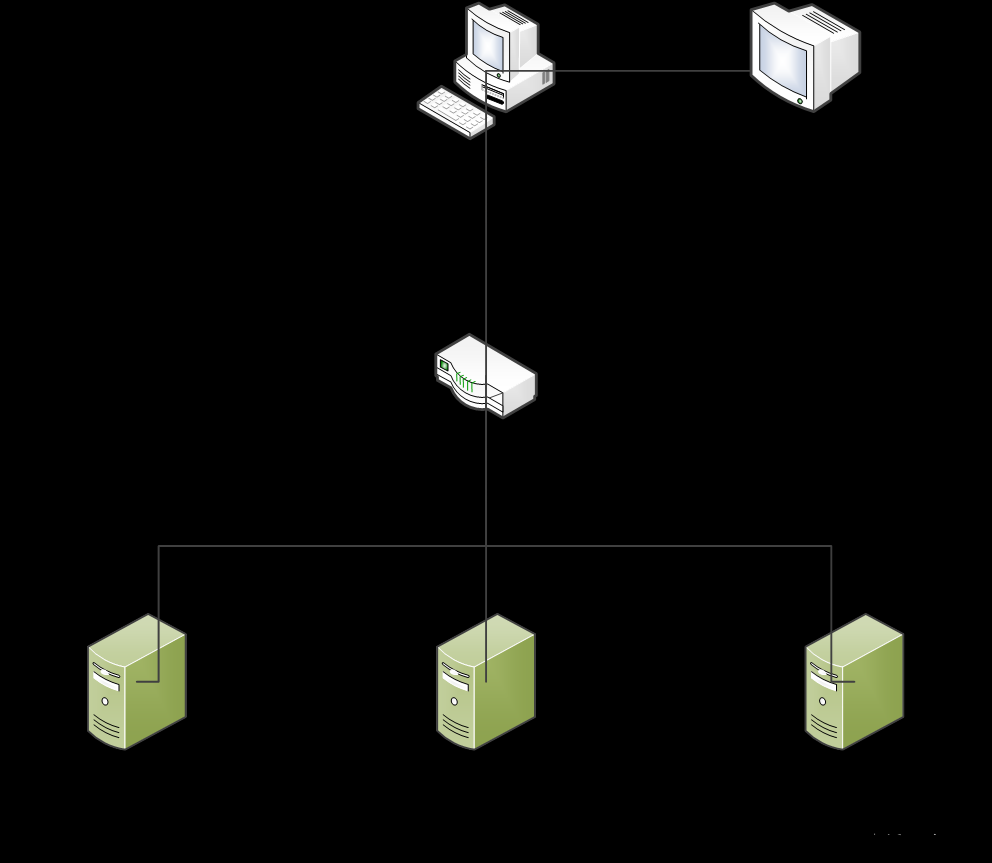
分布式集群的解决方案可以处理大量的数据累积。多线程高并发会增大单机的服务器压力。
每台服务器压力测试会有一个压力阈值。当一台服务器的 cup 处理压力太大的时候,需要做分布式处理。为了提高数据的处理效率,需要做集群。主机和从机的设置,集群节点压力值 的算法测试编写。当一台主机出现故障的时候,需要有合适地从机替换升级为主机,再进行 新一轮的主机和从机的挑选。每个集群的主机为处理数据的主要服务器。很多市面上的管理 集群节点的框架从 2017 年陆续出现,国产的 dubbo zookeeper, 国外的像 springcloud 。
处理多线程高并发的方式很多。时间和空间的考量,以时间换空间,或者是以空间换时间。 同步锁和分布式锁的应用,要综合考虑性能的问题。同步锁 synchronized 的使用会使得线程排队阻塞,损失时间性能。用户体验响应超时是不好的选择。分布式锁就像去火车站排队买票一样,把每一个购票者当做一个用户线程,占有一定的内存空间。排队购票是必需的选择。每个火车站的窗口的开设,每个购票窗口处理票务业务处理,到底一座城市需要有几个火车站,每个火车站需要开设几个购票窗口。算法的设计就是处理类似的计算问题,要计算很多因素,人流量是最大的统计数据处理情况。
小程序的流行,因为简单而设计。简洁即是美。小程序开发周期较短,数据流量平台要经过 微信的支持。每次到一个新的城市,首先是要询问地铁的购票乘车小程序,用得多了就会下 载相应的 APP。文章来源地址https://www.toymoban.com/news/detail-711442.html
到了这里,关于分布式集群与多线程高并发的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!